







目录
16、Virtual sequencer 和sequencer区别
17、sequence, sequence,sequencer,driver之间的通信
24、SVA中重复操作符——连续[*n]、非连续[=n]、跟随[->n]
25、sequence序列操作符——and、intersect、or、first_match、within、throughout、ended
1、常用总线对比
AMBA (Advanced Microcontroller Bus Architecture) 高级处理器总线架构
AHB (Advanced High-performance Bus) 高级高性能总线
ASB (Advanced System Bus) 高级系统总线
APB (Advanced Peripheral Bus) 高级外围总线
AXI (Advanced eXtensible Interface) 高级可拓展接口
这些内容加起来就定义出一套为了高性能SoC而设计的片上通信的标准。
AHB主要是针对高效率、高频宽及快速系统模块所设计的总线,它可以连接如微处理器、芯片上或芯片外的内存模块和DMA等高效率模块。
APB主要用在低速且低功率的外围,可针对外围设备作功率消耗及复杂接口的最佳化。APB在AHB和低带宽的外围设备之间提供了通信的桥梁,所以APB是AHB或ASB的二级拓展总线
AXI:高速度、高带宽,管道化互联,单向通道,只需要首地址,读写并行,支持乱序,支持非对齐操作,有效支持初始延迟较高的外设,连线非常多。
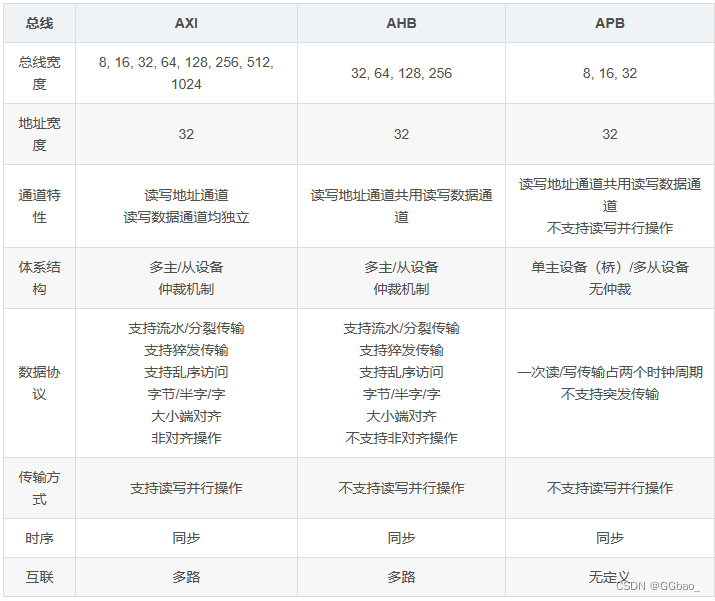
(1条消息) AHB、APB、AXI三种协议对比分析(AMBA总线)_apb axi_fujiayu1997zz的博客-CSDN博客
2、格雷码的作用
数据位跳变就相当于硬件电路中的晶体管翻转。许多位同时跳变就相当于多个晶体管同时翻转,会导致电路中出现很大的尖峰电流脉冲,从而导致数据不稳定。
格雷码,其重要特征是一个数变为相邻的另一个数时,只有一个数据位发生跳变,由于这种特点,就可以避免电路中出现亚稳态而导致数据错误。
简而言之,格雷码的一位改变特征减小了电路出错概率,实际很多场合也用到了格雷码。
二进制到格雷码转换:
①格雷码中最高有效位(最左边)等同于二进制数中响应的最高有效位。
②从左到右,加上每一对相邻的二进制编码位,从而得到下一个格雷码位,舍去进位。
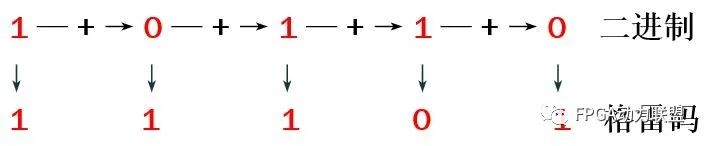
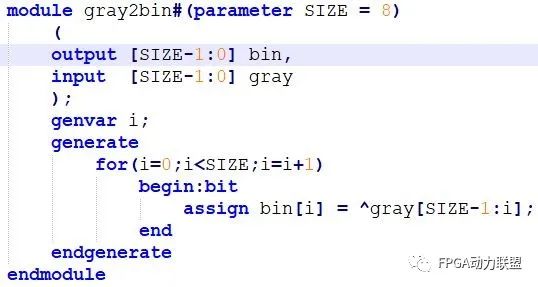
任意位宽的二进制转格雷码verilog代码:
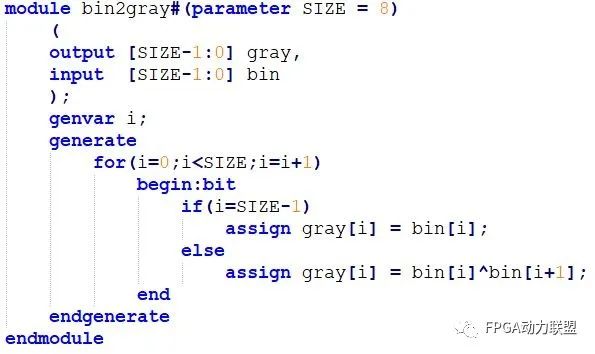
格雷码到二进制转换:
①二进制的最高有效位(最左边)等同于格雷码中响应的最高有效位。
②将所产生的每个二进制码位加下一个相邻位置的格雷码,从而得到下一个二进制位。舍去进位。
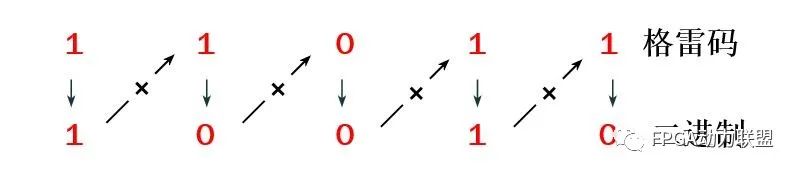
任意位宽的格雷码转二进制verilog代码:
3、异步信号处理
异步信号处理与亚稳态_hard丶working的博客-CSDN博客
4、FIFO的验证(异步)
1、复位:读复位、写复位(复位后读写地址都是默认值,满标志为0,空标志为1)
2、读写:读写数据
3、时钟:相同时钟读写、写快读慢、写慢读快
4、异常:空满(空读、满写)
异步FIFO模块验证-面试总结_异步fifo验证_kobetriumph的博客-CSDN博客
5、寄存器复位值怎么检查
利用寄存器模型的内建seq来检查。
通过读取寄存器模型的复位值(与寄存器描述文件一致),与前门访问获取的寄存器复位值进行比较,以此判断硬件各个寄存器的复位值是否按照寄存器描述去实现。
6、寄存器读写是怎么检查的?前门访问,你怎么知道对不对?
读写测试
随机值测试:随机写一个寄存器值,然后读出check。
位粘连测试:采用00...001和11...110进行移位操作写入读出对比测试防止寄存器某些位粘连。
位翻转测试:写0x55...555(0101...0101)、0xaa...aaa(1010...1010),读出check。
位边界测试:写00...00,fff...ff(1111...1111),读出check。
7、代码覆盖率不满足100%怎么办?
代码覆盖率的主要作用
- 保证基本逻辑的正确性(要结合有效的校验,这点很容易在实际中变形)
- 引入对未覆盖代码的思考,分析是编码本身逻辑混乱,还是需求实现有问题
- 促进代码重构,得到更优的代码
最主要的提升代码覆盖率的方法是增加用例和优化代码。
根据业务流程规划测试用例,设计用例场景、提供校验准则,保证用例的有效性,从而提高代码覆盖率。
构造异常用例,对其他异常场景补充用例。
剔除不需要计算覆盖率的代码,例如库代码等。
减少不必要的判断,例如不必在每次new以后都做指针判空。
简化逻辑,消除重复代码。
8、断言覆盖率怎么写的,验证了哪些?
断言是一种声明性的代码,验证设计功能和时序。断言可以检查信号的值或者设计的状态,cover property语句用来测量这些关系是否发生。
9、callback机制
SystemVerilog | 回调Callback必知必会 - 知乎 (zhihu.com)
Callback机制其作用是提高TB的可重用性,其还可进行特殊激励的产生等callback的类还是原先的类,只是内部的callback函数变了,而factory这是产生一个新的扩展类进行替换。在不创建复杂的OOP层次结构前提下,针对组件中的某些行为,在其之后,内置一些函数,增加或者修改UVM组件的操作,增加新的功能,从而实现一个环境多个用例。还可以通过callback机制构建异常的测试用例。
操作步骤:
1、UVM组件中内嵌callback函数或者任务
2、定义一个常见的uvm_callbacks class
3、从UVM callback空壳类扩展uvm_callback类
4、在验证环境中创建并登记uvm_callback
SystemVerilog中:

UVM中:

应用场景:
回调函数的典型应用可以是在VIP(Verification IP)中。VIP的使用使得验证工程师可以访问验证其设计中所需要的接口协议和存储器等。通常在VIP中,回调函数是改变其协议行为的重要手段,当然这取决于这个VIP是是怎么实现的以及开放了多少功能,特别是在第三方提供的VIP,供应商又要对其加密又希望给用户提供修改VIP行为的便利。这里举个栗子,比如AXI VIP,通过重定义回调函数可以去改变不同transaction之间的延迟、决定AW通道和W通道是否要对齐或支持写数据超前、注入故障等等功能。
在monitor上也有callback的用武之地,比如在monitor留了收集覆盖率信息的hook,或者对monitor采集到的transaction进行不同目的的检查。
10、面相对象编程特性
封装、继承和多态
封装:把数据和使用数据的方法封装在一个集合里,成为class。好处:良好的封装能较少耦合;类内部的结构可以自由修改;可以对成员进行更精确的控制;隐藏信息,实现细节。
继承:允许通过现有类去得到一个新的类,并且可以共享现有类的属性和方法。现有类叫做基类,新类叫做派生类或者扩展类。实际上继承者是被继承者的特殊化,它除了拥有被继承者的特性外,还拥有自己独有得特性。
多态:得到扩展类后,有时我们会使用基类句柄去调用拓展类对象,这时候怎么判断调用对象?通过对类中方法进行virtual声明。
11、factory机制
UVM中factory机制可以根据类名创建这个类的一个实例,还可以在创建类的实例时根据是否有重载类型来决定是创建原始的类,还是创建重载后的类的实例。
其存在的意义就是为了能够方便的替换TB中的实例或者已注册的类型。一般而言,在搭建完TB后,我们如果需要对TB进行更改配置或者相关的类信息,我们可以通过使用factory 机制进行覆盖,达到替换的效果,从而大大提高TB的可重用性和灵活性。
重载方法可以将其原来所属的类型替换为另一个新的类型。在重载之后,原本用于创建(create)原属类型的请求,将由factory机制来创建新的替换类型:这样就可以在不修改原有代码的条件下,用子类替代其父类。这就是用factory机制进行重载的作用。
在实例化时,UVM会通过factory机制在自己内部的一张表格中查看是否有相关的重载记录(在使用set_type_override(uvm_object_wrapper original_type,uvm_object_wrapper override_type) 或 set_inst_overide() 等重载方法后,就相当于在factory机制的表格中加入了一条重载记录):当查到有重载记录时,就会使用新的类来替代旧的类。
使用factory机制重载必须满足的条件:
- 新的用于替换的类型,必须继承于原有类型:class comp2 extends comp1
- 无论是用于重载的类comp2还是被重载的类comp1,都要在定义的时候注册到factory机制中。`uvm_component_utils(comp1) `uvm_component_utils(comp2)
-
被重载的类在例化时,必须使用factory机制的实例化方式creat,而不是传统的new方式
c1 = comp1::type_id::create("c1",null);
-
在被重载的类中,需要重写的方法,必须定义为virtual类型,否则访问不到重载类中的这个被重写后的方法。
12、clocking block描述
Clocking block在验证中的正确使用 - 知乎 (zhihu.com)
Interface是一组接口,用于对信号进行一个封装,捆扎起来。如果像 verilog中对各个信号进行连接,每一层我们都需要对接口信号进行定义,若信号过多,很容易出现人为错误,而且后期的可重用性不高。因此使用interface接口进行连接,不仅可以简化代码,而且提高可重用性,除此之外,interface内部提供了其他一些功能,用于测试平台与DUT之间的同步和避免竞争。
Clocking block:在interface内部我们可以定义clocking块,可以使得信号保持同步,对于接口的采样和驱动有详细的设置操作,从而避免TB与DUT的接口竞争,减少我们由于信号竞争导致的错误。采样提前,驱动落后,保证信号不会出现竞争。 如果clock blocking定义在下沿,可能会出现竞争
13、接口如何传递到环境中
- 传递virtual interface到环境中;
- 配置单一变量值,例如int、string、enum等;
- 传递配置对象(config_object)到环境;
- 传递virtual interface到环境中;
- 虽然SV可以通过层次化的interface的索引完成传递,但是这种传递方式不利于软件环境的封装和复用。通过使用uvm_config_db配置机制来传递接口,可以将接口的传递与获取彻底分离开。
uvm_config_db#(int)::get(this, "", "pre_num", pre_num);
- 接口传递从硬件世界到UVM环境可以通过uvm_config_db来实现,在实现过程中应当注意:
- 接口传递应发生在run_test()之前。这保证了在进入build_phase之前,virtual interface已经被传递到uvm_config_db中。
- 用户应当把interface与virtual interface区分开来,在传递过程中的类型应当为virtual interface,即实际接口的句柄。
- 配置单一变量值,例如int、string、enum等;
在各个test中,可以在build_phase阶段对底层组件的各个变量加以配置,进而在环境例化之前完成配置,使得环境可以按照预期运行。
- 传递配置对象(config_object)到环境;
在test配置中,需要配置的参数不只是数量多,可能还分属于不同的组件。对这么多层次的变量做出类似上边的单一变量传递,需要更多的代码,容易出错且不易复用。如果整合各个组件中的变量,将其放置在一个uvm_object中,再对中心化的配置对象进行传递,将有利于整体环境的修改维护,提升代码的复用性。
14、componet与object区别
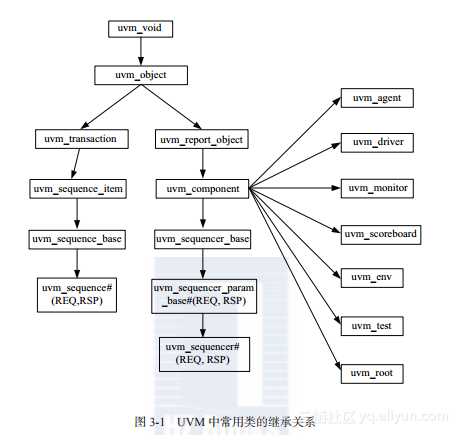
UVM中 component也是由object派生出来的,不过相比于object, component有很多其没有的属性,例如phase机制和树形结构等。在UVM中,不仅仅需要component 这种较为复杂的类,进行TB的层次化搭建,也需要object这种基础类进行TB的事务搭建和一些环境配置等。
uvm_component有两大特性是uvm_object所没有的,一是通过在new的时候指定parent参数来形成一种树形的组织结构,二是有phase的自动执行特点。
uvm_component 必须通过 create 创建,uvm_objection 可以采用 new/create 创建uvm_component 存在于验证的整个过程中,其中存在的组任何组件( component )均不会被析构(释放内存空间),uvm_object 可以在验证的过程中任何时刻被实例化和析构。
item属于object
15、说说ref类型
Ref参数类型是引用
- 向子程序传递数组时应尽量使用ref获取最佳性能,如果不希望子程序改变数组的值,可以使用const ref类型
- 在任务里可以修改变量而且修改结果对调用它的函数随时可见。
16、Virtual sequencer 和sequencer区别
Virtual sequencer主要用于对不同的agent进行协调时,需要有一定顶层的sequencer对内部各个agent中的sequencer进行协调。
virtual sequencer是面向多个sequencer的多个sequence群,而sequencer是面向一个sequencer的sequence群。
virtual sequencer桥接着所有底层的sequencer的句柄,其本身也不需要传递item,不需要和driver连接。只需要将其内部的底层sequencer句柄和sequencer实体对象连接。
17、sequence, sequence,sequencer,driver之间的通信
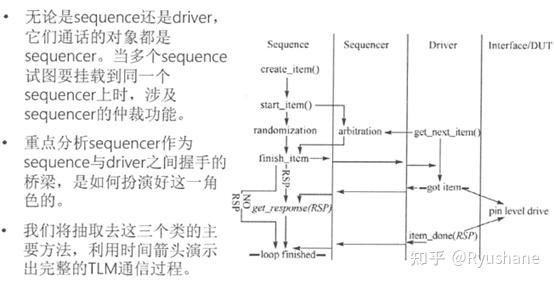


在多个sequence同时向sequencer发送item时,需要有ID信息表明该item从哪个sequence来,ID信息在sequence创建item时就赋值了。
18、代码覆盖率、功能覆盖率和断言覆盖率的区别
代码覆盖率——是针对RTL设计代码的运行完备度的体现,包括行覆盖率、条件覆盖率、FSM覆盖率、跳转覆盖率、分支覆盖率,只要仿真就可以收集,可以看DUT的哪部分代码没有动,如果有一部分代码一直没动看一下是不是case没有写到。
功能覆盖率——与spec比较来发现,design是否行为正确,需要按verification plan来比较进度。用来衡量哪些设计特征已经被测试程序测试过的一个指标,首要的选择是使用更多的种子来运行现有的测试程序;其次是建立新的约束,只有在确实需要的时候才会求助于定向测试,改进功能覆盖率最简单的方法是仅仅增加仿真时间或者尝试新的随机种子。验证的目的就是确保设计在实际环境中的行为正确。设计规范里详细说明了设备应该如何运行,而验证计划里则列出了相应的功能应该如何激励、验证和测量
断言覆盖率---用于检查几个信号之间的关系,常用在查找错误,主要是检查时序上的错误,测量断言被触发的频繁程度。
19、IC验证流程
1、搞清楚要验证的东西
对设计spec进行阅读和理解,把DUT的结构、功能,时序弄清楚。
2、编写验证计划,指导性的文件
(1)提取验证功能点
(2)明确DUT接口信号(所有信号的名字,位宽,功能,时序关系等)
(3)TB的架构(能够描述每一个组件的功能)
(4)检查点(check point)
(5)功能覆盖率(覆盖点)
(6)测试用例的规划(testcase尽可能的规划完整)
(7)结束标准
3、搭建TB&Debug&调通第一个最基本的testcase,然后再编写测试用例debug,进行主要验证。
4、Regression(回归测试,一天一次,有随机测试)
5、分析代码/功能覆盖率,增加新的测试用例
6、测试报告,测试结果:测试用例(pass/fail),覆盖率报告
20、后门访问路径的配置
必须设置后门操作路径,register model才能工作。核心方法是调用reg::get_full_hdl_path
1、register的hdl_path/rtl路径由两部分构成:
分别是(1)uvm_reg_block的基路径(我们叫做reg的base_path)(2)reg本身自己的相对路径(我们叫做reg的offset_path)。
首先是reg的base_path:这个path定义在reg所在的block中(也叫做block的路径),设置block的路径的方式有两种(uvm_reg_block中有两个变量用来存放block的路径)
(1) uvm_object_string_pool #(uvm_queue#(string)) hdl_paths_pool
(2) string root_hdl_paths[string]
其中对于hdl_paths_pool,形象的表示如下

当调用reg_blk.add_hdl_path(path)时会增加一个路径,如果调用4次,则会增加4次路径,如上图所示
对于root_hdl_paths,调用reg_blk.set_hdl_path_root(root_path)来设置路径
那么最终block的路径是什么,答案是如果设置了root path,那么就是这个root path,如果没有设置,那么就是hdl_paths_pool中的值(在实际使用过程中只会add一次,这里假设是path1),其实这里的path1只是这个block的相对地址,怎么得到这个block的绝对地址呢,hier的概念,那么就是 parent_block的路径加上自身设置的路径。这里默认图中是block是root block。
那么reg1的路径是什么。首先base_path=path1(block的绝对路径),offset_ path是什么呢。在reg中,有一个变量叫做
uvm_object_string_pool#(uvm_queue#(uvm_hdl_path_concat)) m_hdl_paths_pool
这个变量用来保存reg自身设置的相对路径。
通过调用add_hdl_path_slice设置了相对路径path_offset。
这个时候这个reg的绝对 rtl 路径是base_path+offset_path。
举个例子:
在上图中
reg_blk.add_hdl_path("tb");reg1.add_hdl_path_splice("reg_boot");
最终这个reg的绝对路径是tb.reg_boot(实际硬件中路径)。
原文链接:https://blog.csdn.net/liuwei848/article/details/103567184
21、APB协议版本间差异
(29条消息) APB协议详解与3.0-4.0-5.0对比_apb协议时序_IC碎碎念的博客-CSDN博客
22、硬件DUT和环境是怎么关联的
Testbench 和 DUT 是通过接口进行数据交互的。接口仅仅是信号的一个集合。
在接口的定义中需要注意的一个问题是:对于同一个信号,其方向(input/output)对于 DUT 和对于 testbench 来说是相反的, 在接口中需要定义信号的方向是针对 testbench 的方向, 这一点需要注意。
为了方面后续的工作,接口的个数合适为宜,总的原则是:
1. 将相互关系紧密的信号放到同一个接口中。
2. 要将同一个时钟周期的信号放到同一个接口中。
3. 将和同一个模块连接的信号要放到同一个接口中。
上面的三点基本上表达的是同一个意思, 这样有利于后期方便激励。
定义好一个接口以后,首先,我们需要在 tb_top 模块中例化接口和待测 DUT,在例化 DUT 的时候,将 DUT 的接口和接口中定义的管脚绑定即可。在例化 dut 时,我们将 dut 的管脚和虚接口的管脚绑定在一起。这样,我们在 testbench 中对虚接口进行操作,也就对 DUT 的管脚进行了操作。在 testbench 中只有 driver 和 monitor 会对 DUT 进行激励的加载和监听。我们在 uvm_top 模块中,通过 uvm_config_db 的 set 语句将定义在 driver 中的虚接口和 uvm_top 模块中的接口连接起来。在 driver 中首先需要定义一个虚接口virtual vif。这里的虚接口的意思是,这个接口在 driver 这里是不存在的,这里只是一个句柄,通过虚接口, testbench 能访问到 uvm_top 中定义的实体接口,从而访问到DUT。随后在 driver 中通过 uvm_config_db 的 get 操作将 driver 中的虚接口和uvm_top 中的实体接口连接起来。这样, driver 通过虚接口实现了对 DUT 的操作。
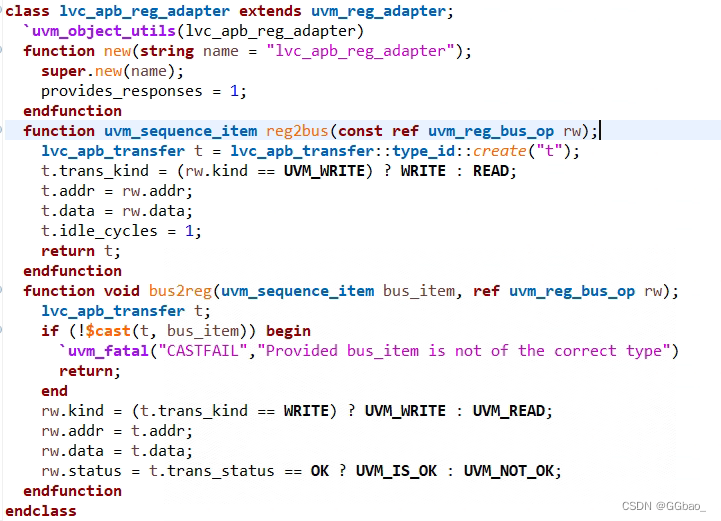
23、adapter的两个函数的写法
注意函数返回类型,传入参数类型,是否需要热余人等。
24、SVA中重复操作符——连续[*n]、非连续[=n]、跟随[->n]

25、sequence序列操作符——and、intersect、or、first_match、within、throughout、ended

SVA——断言属性之序列(sequence与property的用法)_disable iff_SD.ZHAI的博客-CSDN博客
26、timescale的用法
timescale是Verilog HDL 中的一种时间尺度预编译指令,它用来定义模块的仿真时的时间单位和时间精度。格式如下:
`timescale 仿真时间单位/时间精度
注意:用于说明仿真时间单位和时间精度的 数字只能是1、10、100,不能为其它的数字。而且,时间精度不能比时间单位还要大。最多两则一样大。比如:下面定义都是对的:
`timescale 1ns/1ps
`timescale 100ns/100ns
时间精度就是模块仿真时间和延时的精确程序,比如:定义时间精度为10ns, 那么时序中所有的延时至多能精确到10ns,而8ns或者18ns是不可能做到的。
在编译过程中,timescale指令影响这一编译器指令后面所有模块中的时延值,直至遇到另一个timescale指令resetall指令。
在verilog中是没有默认timescale的,一个没有指定timescale的verilog模块就有可能错误的继承了前面编译模块的无效timescale参数。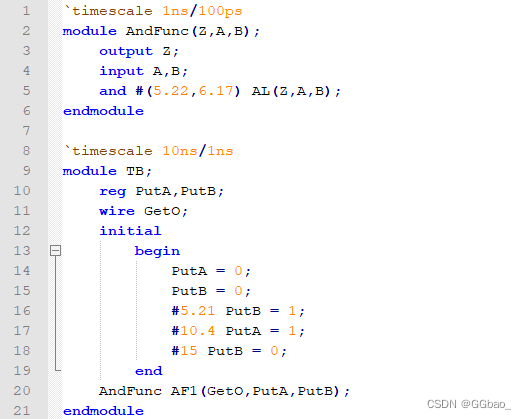
这个例子中,每个模块都有自身的timescale编译器指令。timescale编译器指令第一次应用于时延。因此在第一个模块中,5.22对应5.2ns,6.17对应6.2ns;在第二个模块中5.21对应52ns,10.4对应104ns,15对应150ns,如果仿真模块TB,设计中的所有模块最小时间精度为100ps。因此,所有延迟(特别是模块TB中的延迟)将换算成精度为100ps。延迟52ns现在对应520*100ps,104对应1040*100ps,150对应1500*100ps,更重要的是,仿真使用100ps为时间精度。如果仿真模块AndFunc,由于模块TB不是模块AndFunc的子模块,模块TB中的timescale程序指令将不再有效。
(1条消息) 你真的会用`timescale吗?_孤独的单刀的博客-CSDN博客
27、数字电路验证的维度
验证人员在验证流程中需要具备的五个技术维度。
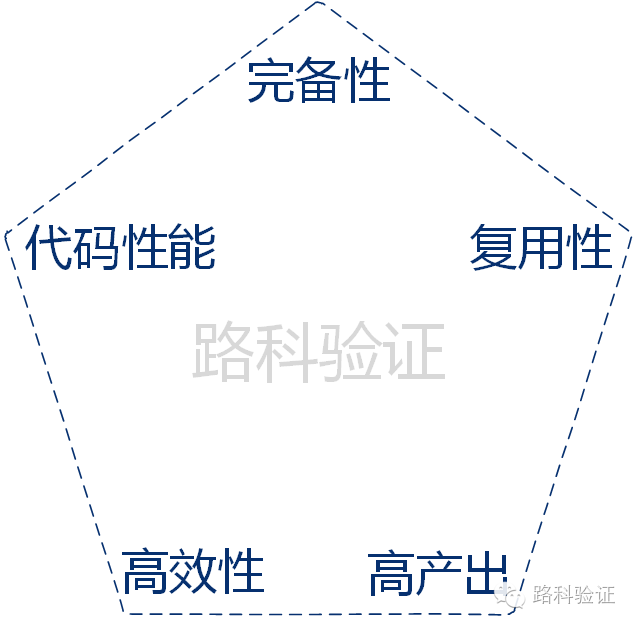
完备性:该维度要求验证的充分。需要引入各种数据来综合量化出验证的进度,这其中包括了验证功能点的覆盖率,代码覆盖率,是否经过了低功耗验证流程(power aware verification),是否经过了跨时钟域检查等等。 通过数据量化,来对验证人员和验证经理增强足够信心来宣布某一个项目节点中,验证已经得到了“充分”的验证。
复用性:从项目的实际运用角度来看,复用性和完备性是同等重要的。下一代硬件设计自身一般不会有第一代芯片的艰难历程(否则它也就称不上是系列芯片了)。 那么从硬件设计的角度来看,这些更新如果不会在逻辑上面有大的变动,那么带来的工作量是可以估计的。而从验证角度来看,我们也很自然地希望验证的工作量也不需要太大——可是事实并不一定是这样的。首先从芯片项目的集成性而言,设计人员相比较验证人员,在同一功能模块的稳定性是更高的,那么当一个验证人员在尝试阅读和修改上一个项目的验证代码时,就要看看他的运气。一般来讲,他的运气会跟上一个验证人员的代码风格有直接的关系……同时,验证人员在处理一些总线协议的时候要有意识引入参数来为日后的复用做好准备。而不断融合的验证方法学,走到今天,UVM(Universal Verification Methodology)之所以划分出不同的功能单元,实现小的颗粒度,提供快速插拔式的环境集成,也是为了复用性考虑的。
高效性:指的是用尽可能少的工作量来完成验证工作。验证人员需要针对不同的情况来在上述的五种维度之间做好平衡,至少需要保持一种意识,那就是工程学的执行阶段本身就是一种平衡,对于验证人员来讲,他需要作出的判断就是在每一个项目每一项验证任务中做好取舍,来给出一个合适的验证考量维度。甚至对于同一项验证任务而言,采取不同的验证策略也会有不同的完成效果。
高产出:指的是在一定的时间,可以调试、报告、帮助修正出多少个设计缺陷,以及可以建立多么完整的验证环境。
代码性能:代码性能似乎也跟高效高产出有冲突的地方,因为对于验证代码的整洁性、复用性甚至一点点地美感都对于数字意义上的验证完备性没有直接联系,这也包括你的验证经理可能有好长时间都不会注意到你写的验证代码,除非有一天你验证的那个设计出了一个缺陷,而且是一个显而易见的缺陷却没有被发现,这可能才会引起验证经理的注意专门来访问可能是一团糟的代码结构。
芯片验证全视之三: 验证能力的五个维度 - guolongnv - 博客园 (cnblogs.com)
28、数组IC验证方法的分类
数字IC验证方法的分类_静态验证的常见方法_嗨小小小黑的博客-CSDN博客
29、task和function的区别

Function和task说明语句的不同点:
(1)函数只能和主模块共用同一个仿真时间单位,而任务可以自己定义自己的仿真时间单位。
(2)函数不能启动任务,但是任务可以能启动其他任务和函数。
(3)函数至少要有一个输入变量,而任务可以没有或者有多个任何类型的变量。
(4)函数返回一个值,而任务则不返回值。
(5) 任务可以有任意多个输入、输入输出inout、输出变量;在任务中可以使用延迟、事件和时序控制结构,在任务中可以调用其他的任务和函数。
(6) 可重入任务使用关键字automatic进行定义,它的每一次调用都对不同的地址空间进行操作。因此在被多次并发调用时,它仍然可以获得正确的结果。
(7) 函数只能有一个返回值,并且至少要有一个输入变量;在函数中不能使用延迟、事件和时序控制结构,但可以调用其他函数,不能调用任务。
(8) 当声明函数时,Verilog仿真器都会隐含地声明一个同名的寄存器变量,函数返回值通过这个寄存器传递回调用处。
(9) 递归函数使用关键字automatic进行定义,递归函数的每一次调用都拥有不同的地址空间。因此对这种函数的递归调用和并发调用可以得到正确的结果。
(10) 任务和函数都包含在设计层次之中,可以通过层次名对它们进行调用。
注意:
在Verilog中函数不能调用任务,但在SystemVerilog对这条限制稍有放宽,允许函数调用任务,但只能在由 fork…join_none语句生成的线程中调用。
Verilog语法之十一:任务(task)和函数(function) - 知乎 (zhihu.com)
30、正则匹配
\d匹配任意的数字,\D匹配任意的非数字
\w: 匹配的是 a-z,A-Z,数字和下划线
\s匹配的是空白字符(包括:\n,\t,\r和空格)
^ 匹配字符串的开始
$ 匹配字符串的结束
31、virtual interface
通过引入interface可以简化模块儿之间的连接,即interface是连接硬件的,其是硬件语言;但对于验证来说,其描述语言往往是软件语言,interface无法在基于OOP的测试平台中实例化,因此我们无法通过interface把激励传送到DUT中;为了解决这个问题,引入了virtual interface,使得基于OOP的验证环境可以通过虚接口把激励传送给DUT。
virtual interface的本质是指向interface的指针,因此其并不是一个真实存在的实体,而interface是一个真实存在的实体;基于OOP的测试平台会通过调用virtual interface来间接操作实际的信号。

(1条消息) System Verilog学习笔记—虚接口(virtual interface)_Verification_White的博客-CSDN博客 SystemVerilog概念浅析之virtual interface - 知乎 (zhihu.com)
32、UVM中sequence的启动方式
(1)start()函数显式调用
(2)`uvm_do()宏启动
(3)default_sequence启动
33、program
program中的注意点:
- program中不能例化其他program和module
- 不能出现interface和always,可以使用initial forever替代always
- program内部可以发起多个initial块
- program中内部定义的变量最好采用阻塞赋值,当然采用非阻塞仿真器也不会产生error,驱动外部信号则应该采用非阻塞赋值
- program中的initial块和module中的initial块执行位置不同,前者在reactive,后者在active块中执行。
- program中存在的多个initial块中,如果有一个initial采用了退出系统函数$exit(),则会结束该program,而不仅仅是该initial块。
SystemVerilog中的Program的学习笔记_verilog program_沧月九流的博客-CSDN博客
system verilog中module和program的区别_绿茶盖儿的博客-CSDN博客
34、Verilog中对有符号数和无符号数进行比特选择或者拼接
1、对于长位宽赋值给短位宽的情况,无论左操作数、右操作数是有符号数还是无符号数,都是直接截断高位,而左操作数二进制所表示的实际十进制数据要看左操作数是无符号数还是有符号数,如果左操作数是无符号数,直接转换成十进制即可,如果是有符号数,则看成2的补码解释成十进制数,这也是实际计算机系统中有符号数的表示方法。
2、对于短位宽赋值给长位宽的情况,需要对高位进行位扩展,具体是扩展1还是扩展0,记住:完全依据右操作数!,具体如下:
1)右操作数是无符号数,则无论左操作数是什么类型,高位都扩展成0;
2)右操作数是有符号数,则要看右操作数的符号位,按照右操作数的符号位扩展,符号位是1就扩展1,是0就扩展0;
3)位扩展后的左操作按照是无符号数还是有符号数解释成对应的十进制数值,如果是无符号数,则直接转换成十进制数值,如果是有符号数,则看成2的补码解释成十进制数;
4)从上面4种情况看出,有符号数赋值成无符号数会出现数据错误的情况,因此要避免这种赋值,而其他情况都是可以保证数据正确的。
35、Verilog中小端[0+:8]注意点
举例说明:
reg [31:0] big_vect;
reg [0:31] little_vect;
问题:
big_vect[0 +:8] 转化后一定是big_vect[较大的数值 : 较小的数值]
little_vect[0 +:8] 转化后一定是little_vect[较小的数值 : 较大的数值]
reg [31:0] big_vect;为大端,那么转化后的也一定是大端,形式不变
big_vect [0+: 8] 从0 开始,升序,位宽为8 ======》》》》》big_vect [7 :0]
little_vect [0 +: 8] 从0 开始,升序,位宽为8 ======》》》》》little_vect [0 :7]
big_vect [15 -: 8] 从15开始,降序,位宽为8 ======》》》》》big_vect [15 :8]
little_vect [15 -: 8] 从15开始,降序,位宽为8 ======》》》》》little_vect [8:15]















 5072
5072











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









