







题目连结:https://rosalind.info/problems/subs/
motif的中文直接翻译是「主题」
在生物资讯中,motif中文可称作模体,意思是在DNA或RNA或蛋白质上,重複出现的片段、小区段,通常是被蛋白质「辨识、结合」的区域。
这些片段不需要完全一模一样,可以容忍有一些不同

motif这名词取的真不错
要比喻的话,我会称他是「旋律」
像是庆祝生日的这首「生日快乐歌」

每个人的发音不同、乐器的音色不同,甚至有节奏差异
但旋律一听我们耳熟能详,能辨识出对方在弹唱的音乐
甚至把「祝你生日快乐」唱成 「猪你生z怪了」有一些词彙上的差异
只要旋律对了,我们还是能听的懂,不影响认知

或者在金融市场上,看到特定pattern的K线图、均线排列
代表这支股票正在多头走势,就像听到股票即将起飞的旋律
不过胡扯一通
其实这一题与上面的概念都无关,单纯只要寻找「子字串匹配」就可以了
不用什麽模糊匹配、模糊搜寻、模糊辨识
子字串匹配只是其中一种寻找Motif的方法
是最简单、最基本的搜寻方式,但是通常「不够准确」
输入:
GATATATGCATATACTT
ATAT
输出:
2 4 10
给一段序列GATATATGCATATACTT
寻找并记录ATAT重複片段的起始点位置
程式码:
暴力破解,双层for迴圈 处理字元比对
s = "GATATATGCATATACTT"
sub = "ATAT"
positions = []
for i in range(0, len(s) - len(sub) + 1):
match = True
for j in range(len(sub)):
if s[i + j] != sub[j]:
match = False
break
if match:
positions.append(i + 1)
for m in positions:
print(m, end=" ")
暴力破解,写成函式
利用python字串比对的写法
if s1 == s2:
或者
if s[i:i+len(t)] == t:
但其实底层也是跑一层for迴圈(处理字元比对),效率相同
def find_substring_locations(s, t):
positions = []
for i in range(len(s) - len(t) + 1):
if s[i:i + len(t)] == t:
positions.append(i + 1) # 位置从1开始计算位置
return positions
# 等价的写法,列表推导式
# def find_substring_locations(s, t):
# return [
# i + 1 # 位置从1开始计算位置
# for i in range(len(s) - len(t) + 1)
# if s[i:len(t) + i] == t
# ]
s = "GATATATGCATATACTT"
sub = "ATAT"
print(" ".join(map(str, find_substring_locations(s, sub))))
KMP演算法
(文长、烧脑、吐血)
KMP演算法是1977年由三位大学教授提出的:Knuth、Morris、Pratt 字串匹配的经典算法
暴力解法是每次都重新从头比对
但其实在比对失败后,可以很明显的拿「下一个位置」直接套上去继续比
靠「已经比对成功的部分」来建一张表(失败表),在比对失败时回退「之前成功的长度」来避免重複工作量
失败表(Failure Table) 名词也很多种,又称:
- LPS表(最长前缀后缀表, Longest Prefix Suffix Table)
- Next表(Next Array)
- 部分匹配表(Partial Match Table)
- 回跳表(Jump Table / Skip Table)
打破对KMP的错误幻想
第一次练习的同学,才需要看这一段,提几个容易误解的地方
1. 这不是KMP这不是肯德基
以下这种方法不算是KMP
主字串:ABAAAABABA
子字串:BAB

主串BAA与BAB对不上
我在比对到失败以后,直接找下一个B来比对就好,略过中间所有的AAA…
这岂不就是「跳过」的解法吗?
=> 这只是带有「人为优化」的直觉,误以为是跳着比对
实际上在做的事情还是「暴力破解」,一个个比对
2. 挪动主串、挪动子串?
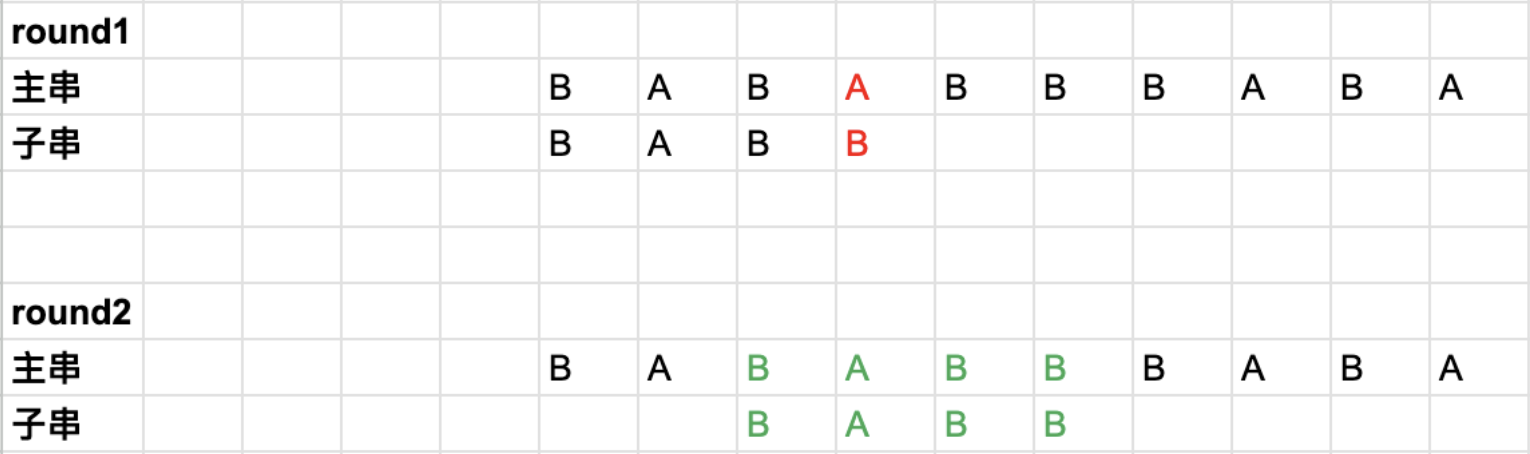
看这两张round1 round2的比对
-
挪动子串的做法
-
挪动主串的做法
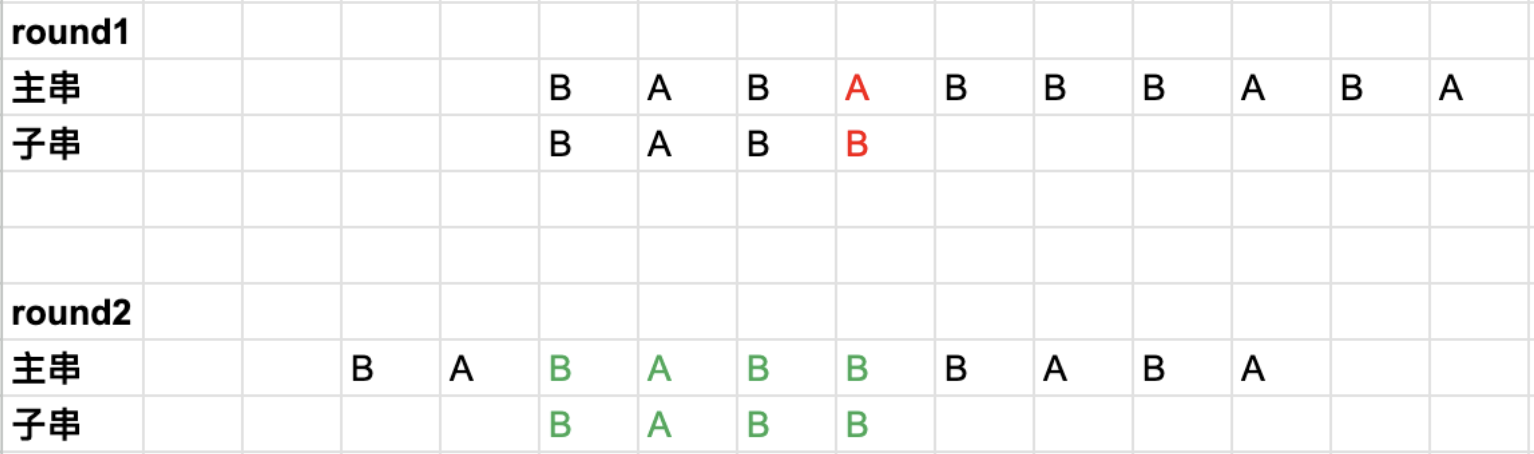
大家都说KMP是「移动子串」,但其实也可以说KMP是「移动主串」
两者只是视角不同,一个相对的概念而已,本质上是做一样的事情。
因为在这道题中,只有A、B两字串比对
若整个宇宙只有A、B两物体,那麽以下两者完全等价
A固定、B移动 <=> A移动、B固定
3. 失败表怎麽推算?
『字串前缀与后缀有多少相似(重叠),记录重叠的长度n』
这样子一旦比对失败后,就能知道 下一个主字串要与「子字串的第n个位置」开始比对
首先请试着照你脑中所想,填写以下栏位
- 1号练习题 字串:“AABBABABBA”

网路上很多教学的范例,会让人觉得是寻找出“最大重複字串长度”
然而实际上概念却是“前缀(最开头)vs后缀(最尾端)”
只准许找头尾,有这样一个限制
答案如下
如果你的答案第一次就正确,那麽恭喜有理解前缀、后缀的意思
- 1号练习题 答案
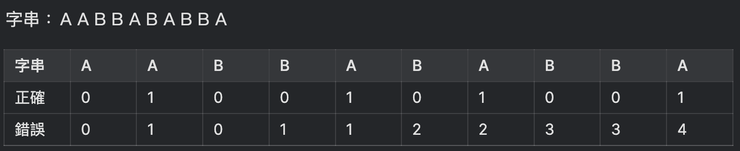
如果找的是“最大重複字串长度”,你推出来会是错误的那行
(顺带一提,失败表的开头从-1或0开始建表都可以,只是先加一或减一的区别而已,网路上两种做法都有,只要在最终整个KMP的比对逻辑配合一致就行。
此篇文章以0为主)
若仍不理解,多看几遍这段叙述
失败表:『包含「最近加入进来的字」的字串,与字串的开头有多么相像』的分数
再看另一题
- 2号练习题 字串:“AABAABBAAA”

最后再来看一题
- 3号练习题 字串:“AAABAAAAAB”

这题是最複杂也是有陷阱的
3号练习题 后半段过程:
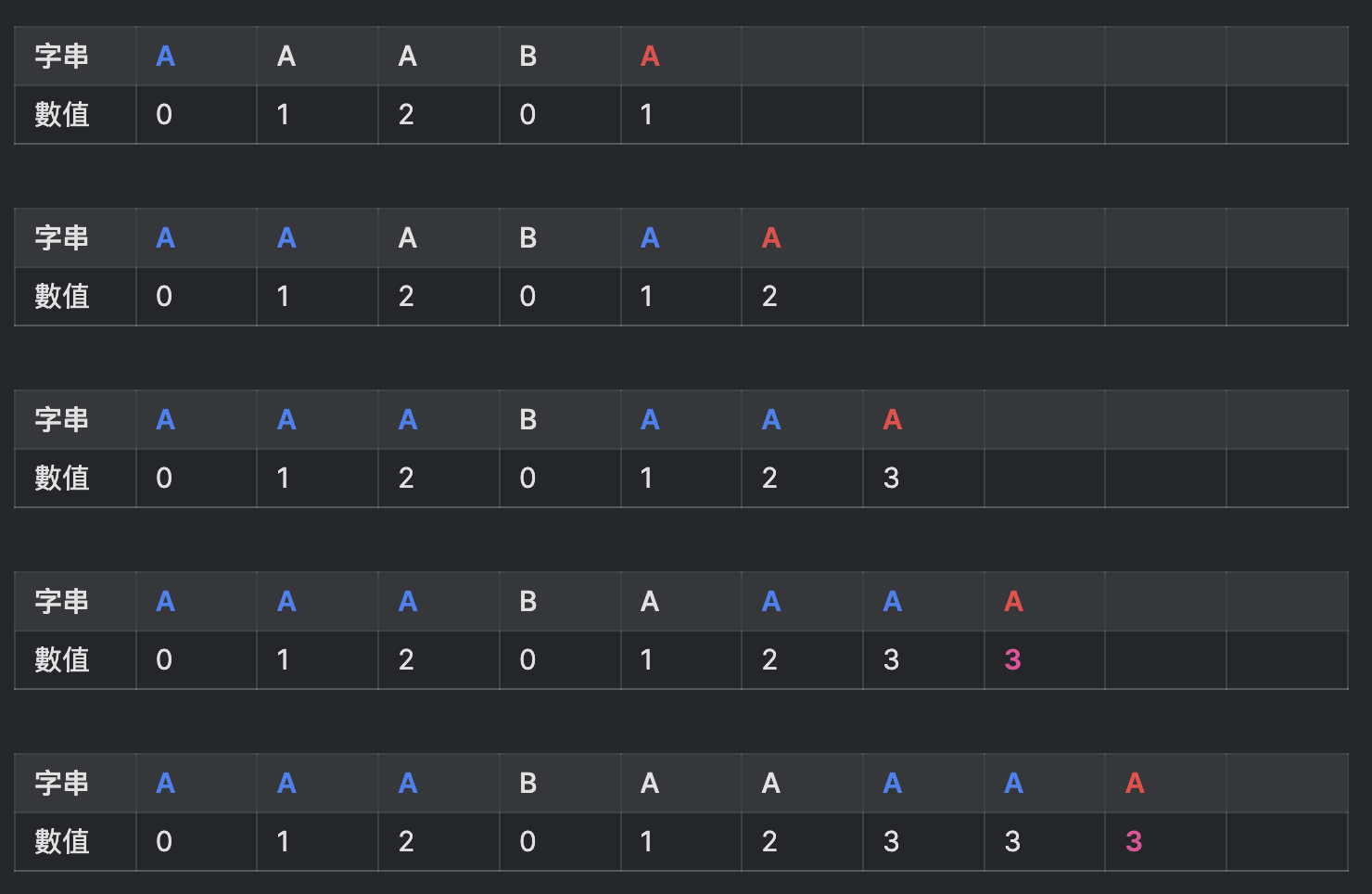
若都能答对
代表手推算完全会了,再来就是如何用逻辑流程建立失败表
(用人眼看很快、要写程式反而难,很神奇吧大脑)
建议:至少手边有纸张,真正推算过一次,因为等一下会用到
尝试建立失败表
参考 1号练习题
首先要建立好第1项(索引为0),在迴圈里面才能开始跟后面第2、第3项比对
# 一开始写 step1
def build_table_step1(t):
table = [0] # 先建好第0项 失败表[0]
length = 0 # 目前位置的 最长(前缀=后缀)的长度,是失败表所填入的数字
for i in range(1, len(t)): # 从第2项(索引为1)开始比对
if t[i] == t[length]: # 若两者合得来,combo数+1
length += 1
table.append(length)
else:
length = 0 # => 写法错误,但先这样试试
table.append(length)
return table
# 1号练习题
print(build_table_step1("AABBABABBA")) # [0, 1, 0, 0, 1, 0, 1, 0, 0, 1]
# 2号练习题:
print(build_table_step1("AABAABBAAA")) # [0, 1, 0, 1, 2, 3, 0, 1, 2, 0(*)]
哇,直接通过1号练习题测资
天哪,好简单喔!
但是马上死在2号练习题
最后一项,很明显是死在else处的逻辑
因为比对错误后不可以直接写0,必须「延续」上一个同样为A的数值
# 接着到 step2
def build_table_step2(t):
table = [0]
length = 0
for i in range(1, len(t)):
if t[i] == t[length]:
length += 1
table.append(length)
else:
# length = table[i - 1] # => 写法错误:改成延续「前一项数值」,其实不对
length = table[length - 1] # => 改成这样会更接近一点,回退、跳到上一个纪录资讯(存档点)=> 但也还不对
table.append(length)
return table
# 1号练习题
print(build_table_step2("AABBABABBA")) # [0, 1, 0, 0, 1, 0, 1, 0, 0, 1]
# 2号练习题:
print(build_table_step2("AABAABBAAA")) # [0, 1, 0, 1, 2, 3, 0, 1, 2, 1(*)]
但不是傻傻「延续」上一个数值,而是要「回跳」上一个纪录点(table)
可是,当回跳以后,仍然死在2号练习题
「回跳」的意思是这样子的:
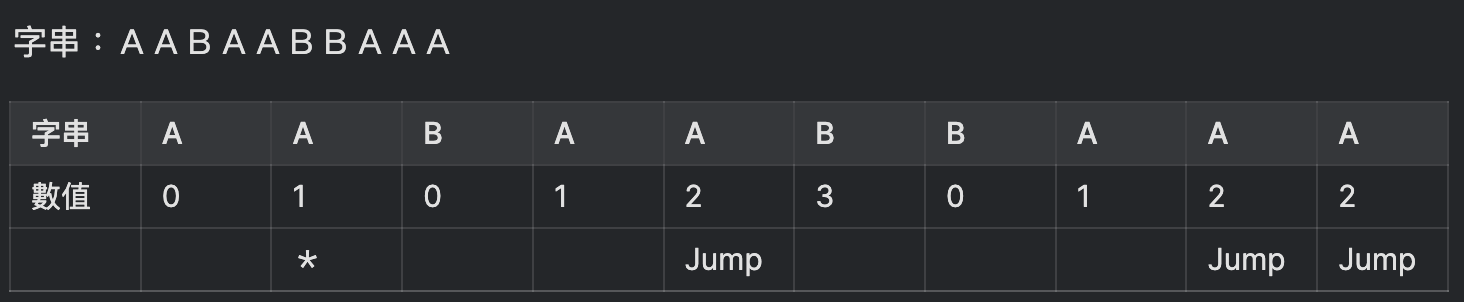
所有的「Jump点」,遭遇比对失败以后,都要直接跳回*处,从此重生点继续往右比对
那麽,跳回*之后呢,要做什麽处理?
失败直接给0吗?跳回只能有一次?
好啊,越来越接近答案了
于是先来看看3号练习题测试资料,从中间开始往下
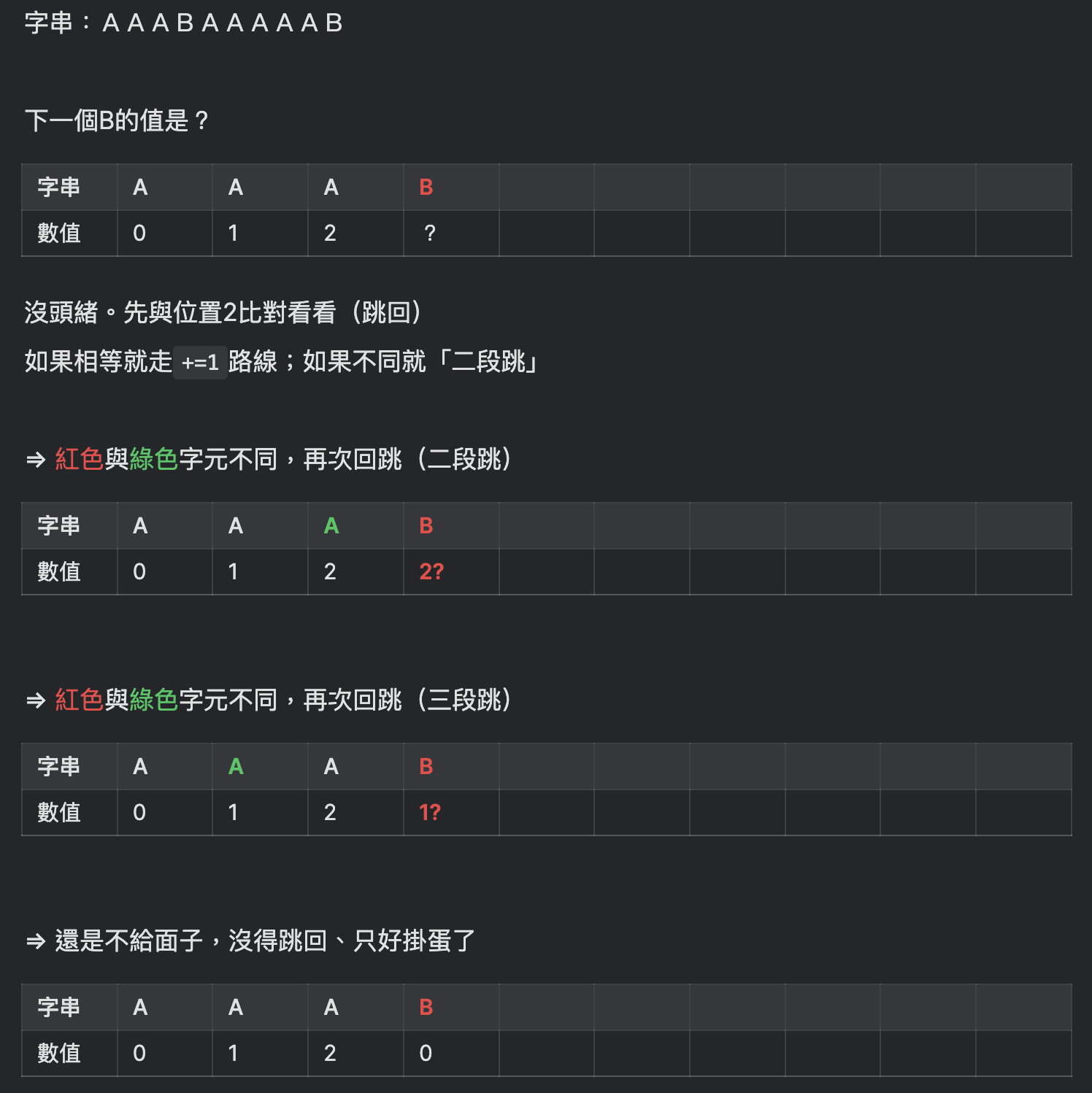
也就是说
一旦「下一个字比对失败」,就必须依脚下所踩着的数字,回跳到该数字的位置(索引)
如果「下一个字」与「回跳回去的字(索引的字)」比对成功,那就挂着该数字啦~
如果比对失败,那就「二段跳」、再失败「三段跳」…一直按脚底下的数字跳回更前面
打个比喻:恋爱KMP学
下一个字元,如果匹配成功(相亲成功),combo+=1
如果匹配失败(跟下一位对象不合)我就回去找前一任女朋友
如果与前一任女友匹配成功,我就与她继续走下去
前一任女友不理我(匹配失败),我就再回去找更前一任女朋友
# 接着到 step3
def build_table_step3(t):
table = [0]
length = 0
for i in range(1, len(t)):
# 失恋就找上一任女友,直到合得来 or 恢復单身
while length > 0 and t[i] != t[length]:
length = table[length - 1]
# 哇,下一个对象是我合的来的人,直接变女友
if t[i] == t[length]:
length += 1
# 原本else处程式码,已改写成上面的while逻辑了
table.append(length)
return table
# 1号练习题
print(build_table_step3("AABBABABBA")) # [0, 1, 0, 0, 1, 0, 1, 0, 0, 1]
# 2号练习题:
print(build_table_step3("AABAABBAAA")) # [0, 1, 0, 1, 2, 3, 0, 1, 2, 2]
# 3号练习题:
print(build_table_step3("AAABAAAAAB")) # [0, 1, 2, 0, 1, 2, 3, 3, 3, 4]
好的好的,这样改写完以后,三个练习测资都能过了
代表KMP最难的部分——「失败表」已经完成
有了失败表后,在比对失败时,能从第几个开始继续比对(跳过几次步骤)
接着来实作主程式
实作主程式
这里要捨弃「双层for迴圈」比对的方式(不然又会变成暴力解)
要拥抱「匹配成功,combo+=1」的概念
# 主程式 step1
def kmp_search_step1(s, t):
positions = []
table = build_table_step3(t) # 建立失败表
length = 0
for i in range(len(s)): # 不是从1开始喔,而是也须要比对[0]
# for j in range(len(t)): # 不是这种双迴圈的写法喔!
# ...
if s[i] == t[length]: # 字元比对成功
length += 1
# else: # 1. 字元比对失败,这里要做什麽?
# ???
if length == len(t): # 字串完全匹配
positions.append(i) # 2. 错误写法,底下length也不该归0
length = 0
return positions
s = "GATATATGCATATACTT"
sub = "ATAT"
print(kmp_search_step1(s, sub)) # [4, 10, 15] 错误 => 正确答案是 [2, 4, 10]
有两个地方要修正
- 比对失败时
- 字串完全匹配时,将符合项目加进
# 主程式 step2
def kmp_search_step2(s, t):
positions = []
table = build_table_step3(t)
length = 0
for i in range(len(s)):
while length > 0 and s[i] != t[length]:
length = table[length - 1]
if s[i] == t[length]: # 字元比对成功
length += 1
# 原本else处程式码,已改写成上面的while逻辑了
if length == len(t): # 字串完全匹配
positions.append(i - length +2) # 起点位置:i - length + 1,且index预设为0,需再+1
length = table[length - 1] # 匹配完重设回前一个 ex: 主字串:AAAA、子字串:AA
return positions
s = "GATATATGCATATACTT"
sub = "ATAT"
print(kmp_search_step2(s, sub)) # [2, 4, 10]
最终程式码:
def kmp_search(s, t):
positions = []
table = build_table(t)
length = 0
for i in range(len(s)):
while length > 0 and s[i] != t[length]:
length = table[length - 1]
if s[i] == t[length]: # 字元比对成功
length += 1
if length == len(t): # 字串完全匹配
positions.append(i - length + 2) # 起点位置:i - length + 1,且index预设为0,需再+1
length = table[length - 1] # 匹配完重设回前一个 ex: 主字串:AAAA、子字串:AA
return positions
def build_table(t):
table = [0]
length = 0
for i in range(1, len(t)):
# 失恋就找上一任女友,直到合得来 or 恢復单身
while length > 0 and t[i] != t[length]:
length = table[length - 1]
# 哇,下一个对象是我合的来的人,直接变女友
if t[i] == t[length]:
length += 1
table.append(length)
return table
s = "GATATATGCATATACTT"
sub = "ATAT"
print(kmp_search(s, sub))
BM演算法
还有个东西叫作 Boyer-Moore,这是目前最实际应用中最快的比对演算法
字串搜寻工具grep就使用这一套
什麽,你想学?真的假的
难道你已经被KMP烧坏脑袋了吗
这边只附程式码,未来有机会再提BM演算法
程式码:
def boyer_moore(text, pattern):
m, n = len(pattern), len(text)
if m == 0:
return []
# 建立坏字元表
bad_char = {}
for i in range(m):
bad_char[pattern[i]] = i
print(bad_char)
result = []
shift = 0
while shift <= n - m:
j = m - 1
while j >= 0 and pattern[j] == text[shift + j]:
j -= 1
if j < 0:
result.append(shift + 1) # 1-based index
# 原本是 shift += m,但这会跳过重叠
# 改为根据下一个坏字元跳,或至少右移一格
shift += 1
else:
last = bad_char.get(text[shift + j], -1)
shift += max(1, j - last)
return result
s = "GATATATGCATATACTT"
sub = "ATAT"
print(boyer_moore(s, sub))
时间複杂度
(N代表主字串长度、M代表是子字串长度)
暴力破解法:平均O(N+M)、最差O(N×M);
有加mismatch(不匹配就break)的话其实随机资料的平均与KMP差不多
KMP演算法:平均O(N+M)、最差O(N+M)
平均与最差都相同,最稳定发挥
Boyer-Moore:平均O(N/M)、最差O(N×M)
平均超级快,但是遇到最差情形会爆炸、退化成暴力法相同(运气好跳超快,省去一堆功夫;但遇到字母种类少又重複时,跳不动)
基因序列的高重複性(只有ATCG)四个字元,字母数太少
不适合使用Boyer-Moore,容物退化变得更慢
如果是 英文字母(A-Z)或者中文字比对
字元集大小较大,遇到一样的字母机遇较低,才适合Boyer-Moore
KMP非常井然有序,整体来说稳定发挥
每一次都“狭带着充足资讯”进行「隐性递迴」
冷笑话:
「我去面试的时候,主管问我有没有resilience(韧性)」
我回答:「我是学KMP的,我从不从头开始,我会记住哪里开始错。」

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









