






语义分割(Semantic Segmentation):是图像处理和机器视觉一个重要分支。与分类任务不同,语义分割需要判断图像每个像素点的类别,进行精确分割。语义分割目前在自动驾驶、自动抠图、医疗影像等领域有着比较广泛的应用。——语义分割是一个分类问题!
Unet可以说是最常用、最简单的一种分割模型了,它简单、高效、易懂、容易构建、可以从小数据集中训练。UNet主要贡献是在U型结构上,该结构可以使它使用更少的训练图片的同时,且分割的准确度也不会差,UNet的网络结构如下图:
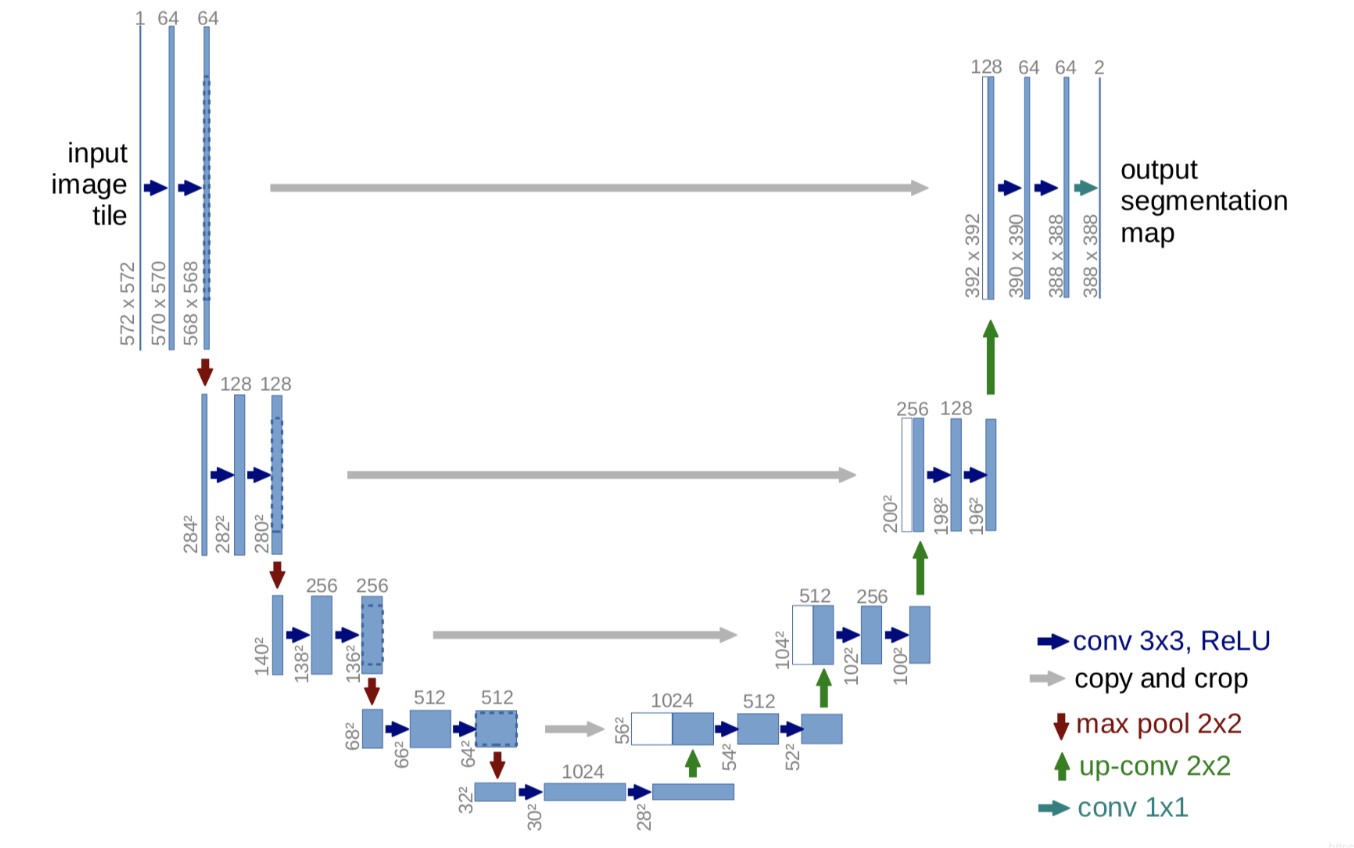
unet网络非常的简单,前半部分就是特征提取,后半部分是上采样。在一些文献中把这种结构叫做编码器-解码器结构(自编码:标签是自身,编解码结构:标签是掩码图),由于网络的整体结构是一个大些的英文字母U,所以叫做U-net。
- Encoder:左半部分,由两个3x3的卷积层(RELU)再加上一个2x2的maxpooling层组成一个下采样的模块(后面代码可以看出);
- Decoder:右半部分,由一个上采样的卷积层(去卷积层)+特征拼接concat+两个3x3的卷积层(ReLU)反复构成(代码中可以看出来);
这个结构就是先对图片进行卷积和池化,在Unet论文中是池化4次,比方说一开始的图片224x224的,那么就会变成112x112,56x56,28x28,14x14四个不同尺寸的特征。然后我们对14x14的特征图做上采样或者反卷积,得到28x28的特征图,这个28x28的特征图与之前的28x28的特征图进行通道上的拼接concat,然后再对拼接之后的特征图做卷积和上采样,得到56x56的特征图,再与之前的56x56的特征拼接、卷积,再上采样,经过四次上采样可以得到一个与输入图像尺寸相同的224x224的预测结构。
在当时,Unet相比更早提出的FCN网络,使用拼接来作为特征图的融合方式。
- FCN是通过特征图对应像素值的相加来融合特征的;
- U-net通过通道数的拼接,这样可以形成更厚的特征,当然这样会更佳消耗显存;
Unet的好处:网络层越深得到的特征图,有着更大的视野域,浅层卷积关注纹理特征,深层网络关注本质的那种特征,所以深层浅层特征都是有各自的意义的;另外一点是通过反卷积得到的更大的尺寸的特征图的边缘,是缺少信息的,毕竟每一次下采样提炼特征的同时,也必然会损失一些边缘特征,而失去的特征并不能从上采样中找回,因此通过特征的拼接,来实现边缘特征的一个找回。
代码实例:
import torch
import torch.nn as nn
from torch.nn.functional import interpolate
# unet
#DoubleConv
class CNNlayer(nn.Module):
def __init__(self, c_in, c_Out):
super(CNNlayer, self).__init__()
self.layer = nn.Sequential(
#设置填充模式为'reflect',在高和宽维度上两边各填充1个单位
nn.Conv2d(c_in, c_Out, 3, 1, padding=1, padding_mode="reflect", bias=False),
nn.BatchNorm2d(c_Out),
nn.LeakyReLU(),
nn.Dropout2d(0.3),
nn.Conv2d(c_Out, c_Out, 3, 1, 1, padding_mode="reflect", bias=False),
nn.BatchNorm2d(c_Out),
nn.LeakyReLU(),
nn.Dropout2d(0.4)
)
def forward(self, x):
return self.layer(x)
# 下采样(使用最大池化)---降噪能力较强
class DownSampling(nn.Module):
def __init__(self):
super(DownSampling, self).__init__()
self.layer = nn.Sequential(
nn.MaxPool2d(2)
)
def forward(self, x):
return self.layer(x)
# #2:使用步长为2的卷积做下采样
# class DownSampling(nn.Module):
# def __init__(self,C):
# super(DownSampling, self).__init__()
# self.layer=nn.Sequential(
# nn.Conv2d(C,C,3,2,1,padding_mode="reflect"),
# nn.LeakyReLU(),
# nn.BatchNorm2d(C)
# )
# def forward(self,x):
# return self.layer(x)
# 上采样+多尺度特征图融合concate
class UpSampling(nn.Module):
def __init__(self, c):
super(UpSampling, self).__init__()
# 特征图大小扩大两倍,通道数减半
self.layer = nn.Sequential(
nn.Conv2d(in_channels=c, out_channels=c // 2, kernel_size=3, stride=1, padding=1, padding_mode="reflect", bias=False),
nn.BatchNorm2d(c // 2),
nn.LeakyReLU(),
)
def forward(self, x, r):
# 使用临近插值法进行上采样
up = interpolate(x, scale_factor=2, mode="nearest") # 特征图放大2倍,通道数不变
x = self.layer(up) # 通道数减半,大小不变
# 通道拼接(cat)
out=torch.cat((x, r), dim=1)#通道合并,大小不变
return out
class UNet(nn.Module):
def __init__(self):
super(UNet, self).__init__()
#4次下采样
self.C1 = CNNlayer(3, 64) # 1,64,256,256
self.D1=DownSampling()#1,64,128,128
self.C2=CNNlayer(64,128) #1, 128, 128, 128
self.D2=DownSampling()#1,128,64,64
self.C3=CNNlayer(128,256) #1,256,64,64
self.D3=DownSampling()#1,256,32,32
self.C4=CNNlayer(256,512) #1,512,32,32
self.D4=DownSampling()#1,512,16,16
#middle
self.C5_ground=CNNlayer(512,1024) #1,1024,16,16
#4次上采样+concate
self.U1=UpSampling(1024)#1,1024,32,32
self.C6=CNNlayer(1024,512)#1,512,32,32
self.U2 = UpSampling(512)#1,512,64,64
self.C7 = CNNlayer(512, 256)#1,256,64,64
self.U3 = UpSampling(256)#1,256,128,128
self.C8 = CNNlayer(256, 128)#1,128,128,128
self.U4 = UpSampling(128)#1,128,256,256
self.C9 = CNNlayer(128, 64)#1,64,256,256
#输出层64->2(是一个二分类问题,输出为背景+前景)
self.Pre=nn.Conv2d(in_channels=64,out_channels=2,kernel_size=3,stride=1,padding=1)
def forward(self, x):
# 下采样部分
R1 = self.C1(x)
R2=self.C2(self.D1(R1))
R3 = self.C3(self.D2(R2))
R4 = self.C4(self.D3(R3))
R5= self.C5_ground(self.D4(R4))
#上采样部分
O1 =self.C6(self.U1(R5, R4))
O2=self.C7(self.U2(O1,R3))
O3 = self.C8(self.U3(O2, R2))
O4=self.C9(self.U4(O3,R1))
return self.Pre(O4)
if __name__ == '__main__':
#测试网络结构
x = torch.randn(1, 3, 512, 512)
net = UNet()
out = net(x)
print(out.shape)
















 1767
1767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











