







梯度消失与梯度爆炸问题
Glorot 和 He 初始化
- 我们需要信号在两个方向上正确流动:进行预测时,信号为正向;在反向传播梯度时,信号为反向。我们需要每层输出的方差等于输入的方差,并且在反方向流过某层之前和之后的梯度具有相同的方差。Glorot初始化(使用逻辑激活函数时)按照下列公式随机初始化每层的连接权重,其中
f
a
n
a
v
g
=
(
f
a
n
i
n
+
f
a
n
o
u
t
)
/
2
fan_{avg}=(fan_{in}+fan_{out})/2
fanavg=(fanin+fanout)/2。

使用Glorot初始化可以大大加快训练速度。

- 默认情况下,Keras使用具有均匀分布的Glorot初始化。创建层时,可以通过设置 kernel_initializer="he_uniform"或kernel_initializer="he_normal"来将其更改为He初始化。
keras.layers.Dense(10, activation="relu", kernel_initializer="he_normal")
- 如果要使用均匀分布,但基于fanavg而不是fanin进行He初始化,则可以使用Variance Scaling:
he_avg_init = keras.initializers.VarianceScaling(scale=2., mode='fan_avg', distribution='uniform')
keras.layers.Dense(10, activation="sigmoid", kenel_initializer=he_avg_init)
非饱和激活函数
- ReLU函数的变体,例如leaky ReLU。该函数定义为
L
e
a
k
y
R
e
L
U
α
=
m
a
x
(
α
z
,
z
)
LeakyReLU_{\alpha}=max(\alpha_{z},z)
LeakyReLUα=max(αz,z).
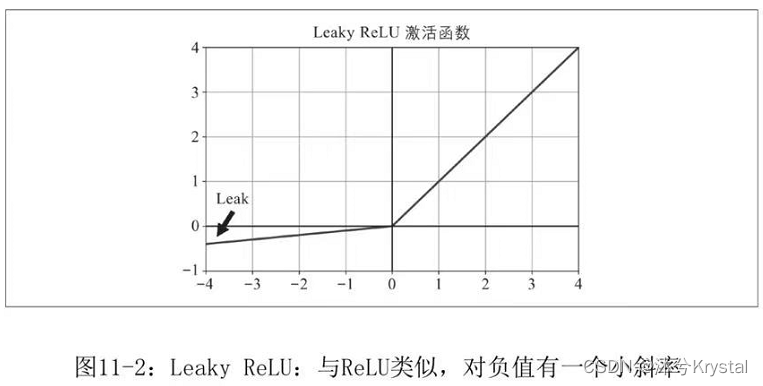
超参数 α \alpha α 定义函数“泄漏”的程度,通常设置为0.01,实际上,设置 α = 0.2 \alpha = 0.2 α=0.2(大泄漏)似乎比 α = 0.01 \alpha = 0.01 α=0.01(小泄漏)会产生更好的性能。 - 2015年提出了一种新的激活函数,称为指数线性单元(Exponential Linear Unit,ELU)。
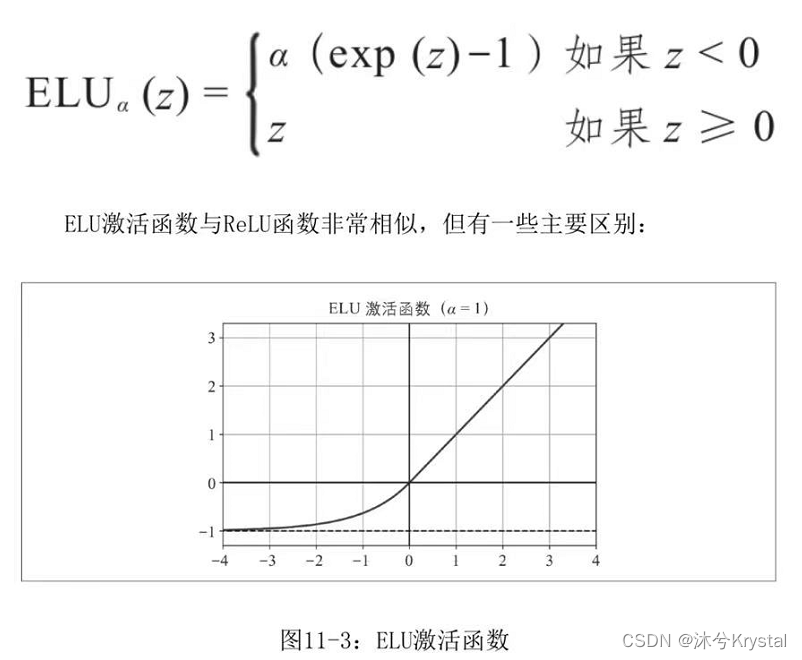
超参数 α \alpha α定义一个值,该值为当 z z z为较大负数时ELU函数逼近的值。通常将其设置为1.
对于 z < 0 z<0 z<0,它具有非零梯度,从而避免了神经元死亡的问题。 - 产生自归一化的条件:
- 输入特征必须是标准化的(平均值为0,标准差为1);
- 每个隐藏层的权重必须使用LeCun正态初始化。在Keras中,这意味着设置 kernel_initializer=“lecun_normal”。
- 网络的架构必须是顺序的。
- 使用激活函数,通常 SELU>ELU>Leaky ReLU(及其变体)>ReLU>tanh>logistic。
- 使用leaky ReLU 激活函数,创建一个 LeakyReLU 层,并将其添加到想要应用它的层之后的模型中:
model = keras.models.Sequential([
[...]
keras.layers.Dense(10, kernel_initializer="he_normal"),
keras.layers.LeakyReLU(alpha=0.2),
[...]
])
- 对于SELU激活,在创建层时设置activation="selu"和 kernel_initializer=“lecun_normal”:
layer = keras.layers.Dense(10, activation="selu",
kernel_initializer="lecun_normal")
批量归一化
- 2015年提出一种称为批量归一化(BN)的技术来解决梯度消失/梯度爆炸问题。该操作可以使模型学习各层输入的最佳缩放和均值。
- 为了使输入零中心并归一化,该算法需要估计每个输入的均值和标准差。
- 批量归一化算法如下:
1. η B = 1 m B ∑ i = 1 m B x ( i ) 2. δ 2 = 1 m B ∑ i = 1 m B ( x ( i ) − η B ) 2 3. x ^ ( i ) = x ( i ) − η B δ 2 + ε 4. z ( i ) = γ ⊗ x ^ ( i ) + β \begin{array}{ll} 1.&\eta _{B} = \frac{1}{m_B} {\sum_{i = 1}^{m_B} x^{(i)} }\\ 2.&\delta ^2 = \frac{1}{m_B} {\sum_{i = 1}^{m_B} (x^{(i)}-\eta_{B})^2 }\\ 3.&\hat{x}^{(i)} = \frac{x^{(i)}-\eta_{B}}{\sqrt{\delta ^2+\varepsilon } }\\ 4.&z^{(i)}=\gamma \otimes \hat{x}^{(i)}+\beta \end{array} 1.2.3.4.ηB=mB1∑i=1mBx(i)δ2=mB1∑i=1mB(x(i)−ηB)2x^(i)=δ2+εx(i)−ηBz(i)=γ⊗x^(i)+β
m B m_B mB 是小批量中的实例数量, γ \gamma γ 是该层的输出缩放向量, ⊗ \otimes ⊗ 表示逐元素乘法(每个输入乘以其相应的输出缩放参数), β \beta β 是层的输出移动(偏移)参数向量, z ( i ) z^{(i)} z(i) 是BN操作的输出,它是输入的缩放和偏移版本。 - 在训练期间,BN会归一化其输入,那在测试期间呢?我们需要对单个实例,而不是成批次的实例做出预测,此时计算统计量是不可靠的。
- 大多数批量归一化的实现都是通过使用该层输入的 均值和标准差 的移动平均值 来估计训练期间的最终统计信息。这是Keras在使用BatchNormalization层时自动执行的操作。
- 综上所述,在每个批归一化层学习了四个参数向量:
- 通过常规反向传播学习 γ \gamma γ(输出缩放向量)和 β \beta β(输出偏移向量)
- 使用指数移动平均值估计的 η \eta η(最终的输入均值向量)和 δ \delta δ(最终输入标准差向量)。
用Keras实现批量归一化
- 实现批量归一化,只需在每个隐藏层的激活函数之前或之后添加一个BatchNormalization层,然后可选地在模型的第一层后添加一个BN层。
import tensorflow as tf
from tensorflow import keras
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.BatchNormalization(),
keras.layers.Dense(300, activation="elu", kernel_initializer="he_normal"),
keras.layers.BatchNormalization(),
keras.layers.Dense(100, activation="elu", kernel_initializer="he_normal"),
keras.layers.BatchNormalization(),
keras.layers.Dense(10, activation="softmax")
])
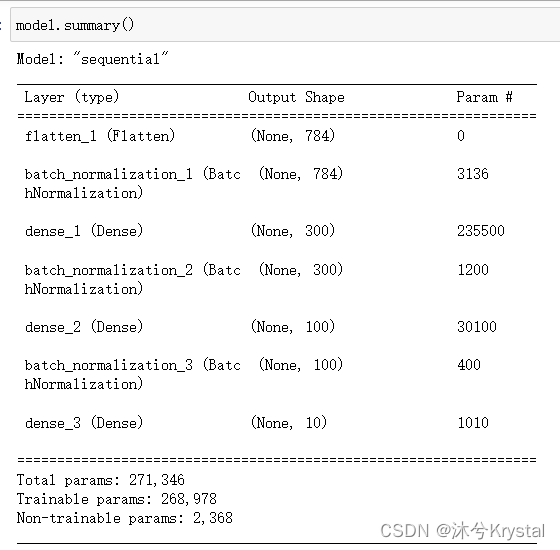
- 看一下第一个BN层的参数。两个是可训练的(通过反向传播),两个不是:

- 在Keras中创建BN层时,还会创建两个操作,在训练期间的每次迭代中,Keras都会调用这两个操作。这些操作会更新移动平均值。
- BN论文的作者主张在激活函数之前添加BN层,要在激活函数之前添加BN层,必须从隐藏层中删除激活函数,并将其作为单独的层添加到BN层之后。此外,由于批量归一化层的每个输入都包含一个偏移参数,因此可以从上一层中删除偏置项(创建时只需传递use_bias=False即可):
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.BatchNormalization(),
keras.layers.Dense(300, kernel_initializer="he_normal", use_bias=False),
keras.layers.BatchNormalization(),
keras.layers.Activation("elu"),
keras.layers.Dense(100, kernel_initializer="he_normal", use_bias=False),
keras.layers.BatchNormalization(),
keras.layers.Activation("elu"),
keras.layers.Dense(10, activation="softmax")
])
- BatchNormalization类具有许多可以调整的超参数,偶尔可能需要调整momentum。BatchNormalization层在更新指数移动平均值时使用此超参数。给定一个新值(即在当前批次中计算的输入均值或标准差的新向量),该层使用以下公式来更新运行时平均 v ^ \hat{v} v^:
\hat{v}\gets \hat{v}\times momentum+v\times(1-momentum)
一个良好的动量值通常接近于1,例如0.9、0.99。
- 另一个重要的超参数是 axis:它确定哪个轴该被归一化。默认为-1,对最后一个轴进行归一化。
梯度裁剪
- 缓解梯度爆炸问题的另一个流行技术是:在反向传播期间裁剪梯度,使它们永远不会超过某个阈值,称为梯度裁剪。这种技术最常用于循环神经网络,因为在RNN难以使用批量归一化。
- 在Keras中实现梯度裁剪,即是在创建优化器时设置 clipvalue 或 clipnorm 参数的问题:
optimizer = keras.optimizers.SGD(clipvalue=1.0)
model.compile(loss="mse", optimizer=optimizer)
- 如果要确保“梯度裁剪”不更改梯度向量的方向,应该设置clipnorm按照范数来裁剪。














 6162
6162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









