






一:基本思路
- 在Idea中安装插件,使得Idea中可以编写scala代码。
- 使用Maven创建项目,并在pom.xml文件中配置相关的依赖。
-
下载安装Scala
(1)访问Scala官方网站(https://www.scala-lang.org/download/)下载适合操 作系统的Scala安装包
(2) 打开命令提示符(CMD),输入以下命令:scala -version 如果显示Scala 的版本信息,说明安装成功。
(三)在IDEA中添加Scala插件
IDEA中,默认是不支持编写Scala的,需要额外配置一个插件。如下图示。
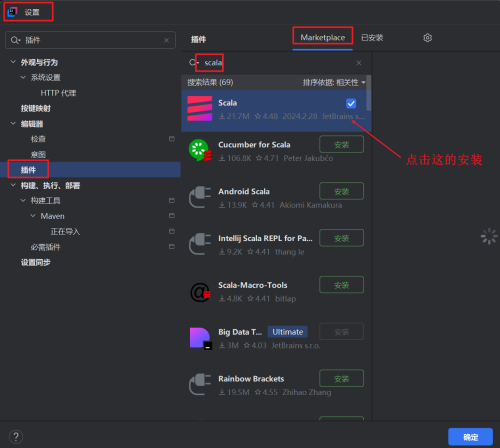
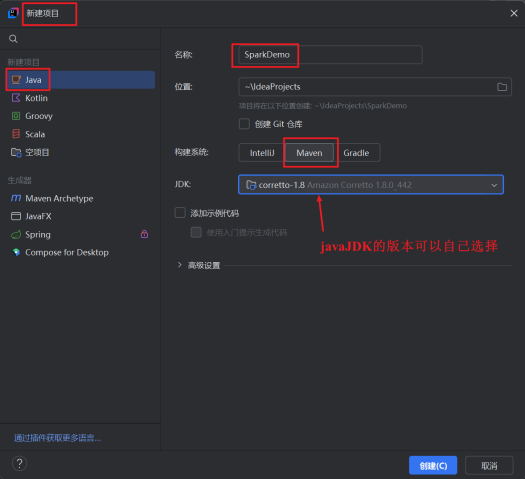
(四)使用Maven创建新项目
核心的操作步骤如下:
- 启动idea,选择新建项目。之后的设置如下:
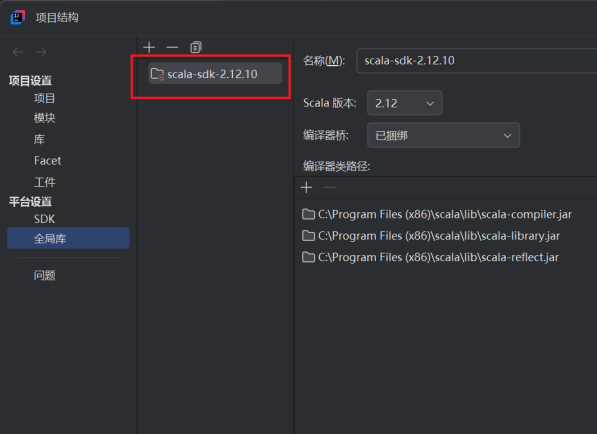
2.将Scala添加到全局库中
3.设置maven依赖项。修改pom.xml文件,添加如下:
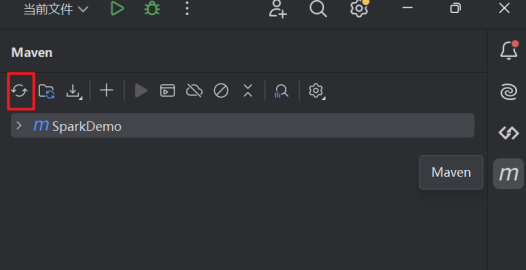
<properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <!-- 声明并引入共有的依赖--> <dependencies> <!-- scala-library--> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>2.12.15</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>3.2.2</version> </dependency> </dependencies> </project>4.下载依赖。添加完成之后,刷新Maven,它会帮助我们去下载依赖。
5.编写代码。修改文件夹的名字。

6.新建Scala类。如果这里没有看到Scala类的选项,就去检查第2步。
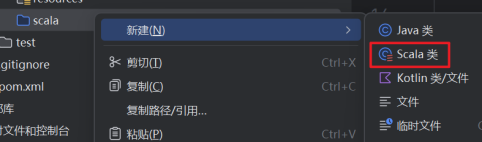
选择Object,输入WordCount
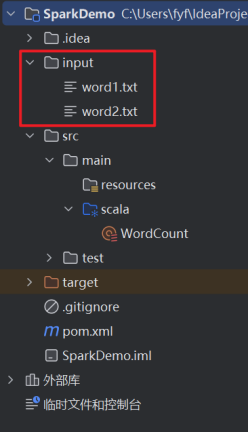
7.编写代码如下 它的功能是wordcount的功能:从指定的文件夹中去读取文件,并做词频统计。 import org.apache.spark.{SparkConf, SparkContext} object WordCount{ def main(args: Array[String]): Unit = { // 配置 Spark 应用程序 val conf = new SparkConf().setAppName("WordCount").setMaster("local[*]") // 创建 SparkContext 对象 val sc = new SparkContext(conf) // 读取目录下的所有文本文件 val textFiles = sc.wholeTextFiles("input") // 提取文本内容并执行 WordCount 操作 val counts = textFiles.flatMap { case (_, content) => content.split("\\s+") }.map(word => (word, 1)).reduceByKey(_ + _) // 将所有分区的数据合并成一个分区 val singlePartitionCounts = counts.coalesce(1) // 保存结果到文件 singlePartitionCounts.saveAsTextFile("output") // 停止 SparkContext sc.stop() } }8.准备待统计的词频文件。在项目根目录下建立文件夹input,并穿件两个文本文件:word1.txt, word2.txt。如下图。
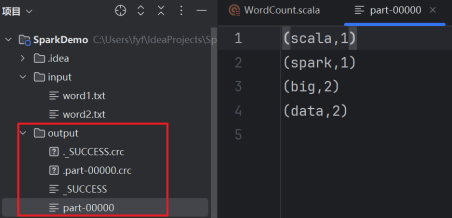
9.运行代码。点击运行代码。
10生成结果如上右图。

















 5917
5917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









