







earn 等机器学习库实现的算法都只能处理数值型数据,所以我们要对现实世界中大量的离散型数据进行预处理。
离散型数据分为两种:有序和无序。衣服的尺码:S、M 和 L 就是有序的,因为 S < M < L。衣服的颜色就是无序的,因为无法比较红色和绿色的大小,这样的比较也毫无意义。
在介绍处理离散型数据的方法之前,先造点样例数据。
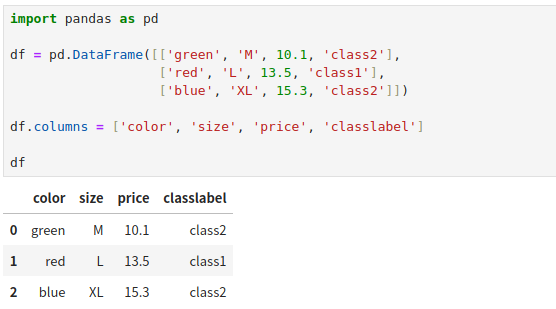
我们的数据中含有无序的离散型特征 color,有序的离散型特征 size 和数值型特征 price。最后一列是样本类别 classlabel。
我们需要将离散型特征转成数值型。
处理有序离散型特征
目前没有一个合适函数可以帮助我们将有序的离散型特征取值映射到对应大小关系的数值上,我们需要自己定义它们的大小关系,假设:XL = L + 1 = M + 2。
那么我们可以定义一个映射关系去将 size 列转成数值型。

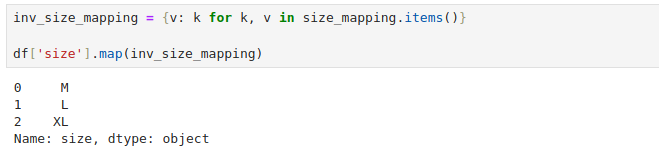
我们也可以定义一个反向的映射关系将数字转成有序的离散字符串。
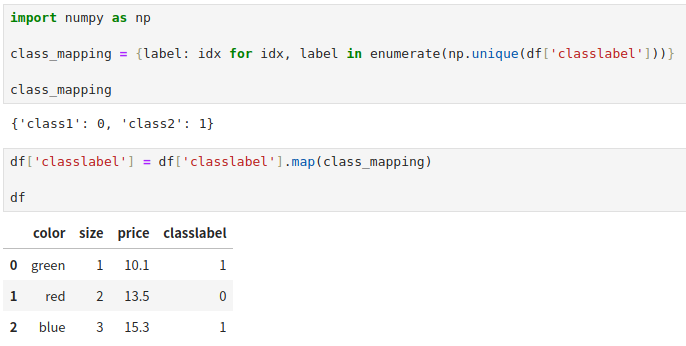
将类别标签转成数字
许多机器学习库要求将类别标签也编码成数字。尽管大多数 scikit-learn 实现的算法默认会内部自动将字符串类别标签转成数字,但是为了避免潜在的 bug,我建议还是手动自己转。
类别标签没有顺序和大小一说,我们可以简单地通过枚举将类别标签映射成从 0 开始的数字,然后再次使用 map 方法转换。
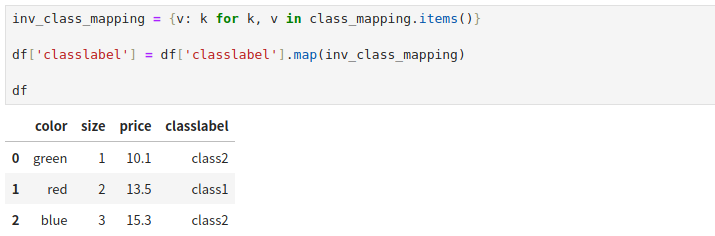
同样地也能反向转换,将数字转成字符串表示的类别标签。
scikit-learn 也提供了一个 LabelEncoder 类帮助我们转换类别标签。

其实我在前面的逻辑回归和 SVM 文章中就已经使用了这种方式将 Iris 数据集的类别标签转成数字了。
处理无序离散型数据
你可能会想到用 LabelEncoder。

但是这样很明显会潜在地引入了顺序,算法会捕获到这种顺序关系:red > green > blue,从而会影响模型性能。
有一种叫作独热编码(one hot encoding)的方法可以有效处理这种无序的离散型数据,它通过创建 dummy feature 来完成这项任务。
下面是 Pandas 的 get_dummies 方法,它只会处理取值为字符串的列,而且其他数值型列保持不变。
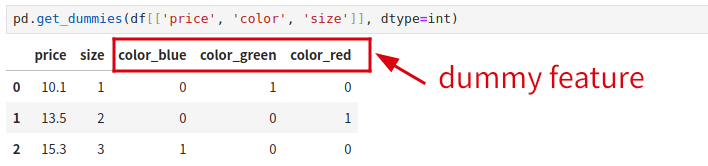
color 列有 blue、green 和 red 三种离散取值,于是就创建了三个 dummy 特征:color_blue,color_green 和 color_red。如果原有的样本(行)在 color 列的取值是 green,那么对应的 dummy 特征中只有 color_green 列取值为 1,其他列为 0。
scikit-learn 也提供了独热编码的实现。
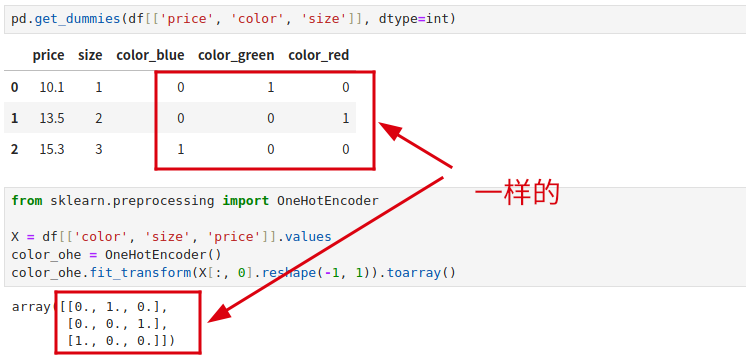
不过在 scikit-learn 提供的 OneHotEncoder 方法中,我们通过 X[:, 0].reshape(-1, 1) 指定了要处理的是 color 列,从而避免了它处理其他的列。
我们可以利用 scikit-learn 提供的 ColumnTransformer 对不同的列做不同的转换,只需要传入(处理步骤名称,转换器,列序号)组成的列表就行了。
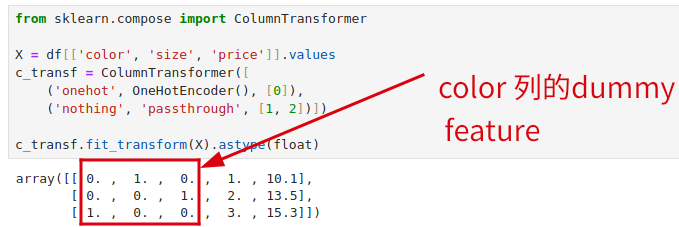
passthrough 表示不做任何处理。
我认为 Pandas 提供的方法在可视化结果上更直观。
有一点需要注意的是,独热编码会增加数据维度,导致由数据特征组成特征矩阵中有很多存储了 0 和 1 的列,增加了稀疏性。
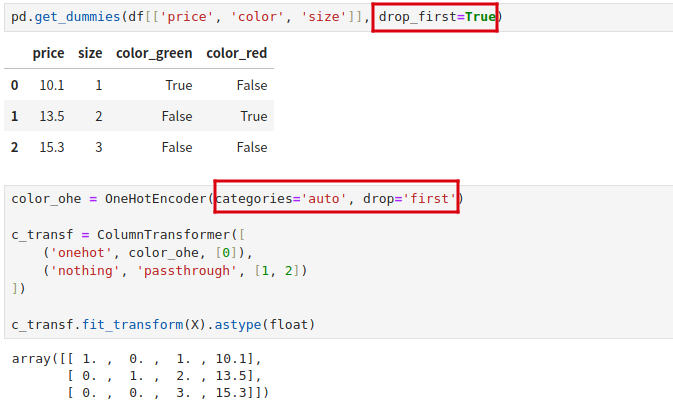
我们可以移除一些 dummy feature,而同时保证不丢失信息。比如将 color_blue 列丢弃,如果 color_green 和 color_red 列取值都是 0,那显然这个样本颜色就是 blue。
我们只需要额外指定几个参数就可以通过 Pandas 或者 scikit-learn 实现丢弃 dummy feature 了。

















 501
501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









