






点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
导读作者:Dipanjan (DJ) Sarkar
编译:ronghuaiyang
数据科学中离散数据的处理方式。
介绍
在本系列的前一篇文章中,我们讨论了处理结构化连续数字数据的各种特征工程策略。考虑到我们不必处理任何属于分类类型的数据属性中,与每个类别值相关的语义的额外复杂性,处理数字数据通常比处理分类数据更容易。我们将使用一种实际操作的方法来讨论处理分类数据的几种编码方案,以及处理大规模特征爆炸的一些流行技术,通常称为“维数的诅咒”。
类别数据上的特征工程
虽然在各种机器学习框架中已经取得了许多进展,可以接受复杂的分类数据类型,比如文本标签。通常,特征工程中的任何标准工作流都涉及到某种形式的将这些分类值转换为数字标签,然后对这些值应用某种编码方案。我们在开始前先把必要的必需品装好。
import pandas as pd
import numpy as np名词属性变换
名词属性由离散的范畴值组成,它们之间没有概念或秩序。这里的想法是将这些属性转换为更有代表性的数值格式,以便下游代码和管道能够轻松理解。让我们来看一个与电子游戏销售相关的新数据集。这个数据集也可以在Kaggle 和我的GitHub仓库中找到。
vg_df = pd.read_csv('datasets/vgsales.csv', encoding='utf-8')
vg_df[['Name', 'Platform', 'Year', 'Genre', 'Publisher']].iloc[1:7]
让我们关注一下上面数据框中描述的视频游戏“Genre”属性。很明显,这是一个名义上的分类属性,就像“发布者”和“平台”一样。我们可以很容易地得到独特的视频游戏类型列表如下。
genres = np.unique(vg_df['Genre'])
genres
Output
------
array(['Action', 'Adventure', 'Fighting', 'Misc', 'Platform',
'Puzzle', 'Racing', 'Role-Playing', 'Shooter', 'Simulation',
'Sports', 'Strategy'], dtype=object)这告诉我们我们有12种不同的电子游戏类型。现在,我们可以通过利用 scikit-learn生成一个标签编码方案,将每个类别映射到一个数值。
from sklearn.preprocessing import LabelEncoder
gle = LabelEncoder()
genre_labels = gle.fit_transform(vg_df['Genre'])
genre_mappings = {index: label for index, label in
enumerate(gle.classes_)}
genre_mappings
Output
------
{0: 'Action', 1: 'Adventure', 2: 'Fighting', 3: 'Misc',
4: 'Platform', 5: 'Puzzle', 6: 'Racing', 7: 'Role-Playing',
8: 'Shooter', 9: 'Simulation', 10: 'Sports', 11: 'Strategy'}因此,在“LabelEncoder”对象“gle”的帮助下,生成了一个映射方案,其中每个类型值都映射到一个数字。转换后的标签存储在“genre_tags”值中,我们可以将该值写回数据帧。
vg_df['GenreLabel'] = genre_labels
vg_df[['Name', 'Platform', 'Year', 'Genre', 'GenreLabel']].iloc[1:7]
这些标签通常可以直接使用,特别是在像 scikit-learn这样的框架中,如果您打算使用它们作为预测的响应变量,那么就需要对它们进行额外的编码,然后才能使用它们作为特征。
序号属性的变换
序号属性是具有顺序的分类属性。让我们考虑一下我们的Pokemon dataset,我们在本系列的Part 1中使用了它。让我们更具体地关注“Generation”属性。
poke_df = pd.read_csv('datasets/Pokemon.csv', encoding='utf-8')
poke_df = poke_df.sample(random_state=1,
frac=1).reset_index(drop=True)
np.unique(poke_df['Generation'])
Output
------
array(['Gen 1', 'Gen 2', 'Gen 3', 'Gen 4', 'Gen 5', 'Gen 6'],
dtype=object)基于上面的输出,我们可以看到总共有6代,而每一个Pokemon都属于基于游戏(游戏发行时)的特定代,并且电视剧也遵循着类似的时间轴。这个属性通常是有序的(这里需要领域知识),因为大多数属于Generation 1的Pokemon在电子游戏和电视节目中出现的时间都比Generation 2早。粉丝们可以看看下面的图来记住每一代流行的Pokemon(粉丝们的观点可能会有所不同!)

因此他们之间有顺序。一般来说,没有通用的模块或函数来自动映射和转换这些特征,并将其转换为基于顺序的数字表示形式。因此,我们可以使用自定义编码\映射方案。
gen_ord_map = {'Gen 1': 1, 'Gen 2': 2, 'Gen 3': 3,
'Gen 4': 4, 'Gen 5': 5, 'Gen 6': 6}
poke_df['GenerationLabel'] = poke_df['Generation'].map(gen_ord_map)
poke_df[['Name', 'Generation', 'GenerationLabel']].iloc[4:10]
从上面的代码可以很明显地看出, pandas中的 map(…) 函数对于转换这个序号特征非常有用。
编码类别属性
如果您还记得我们前面提到的内容,那么分类数据上的特征工程通常包括前面一节描述的转换过程和编码过程,在这个过程中,我们应用特定的编码模式为特定分类属性中的每个类别\值创建dummy变量或特征。
您可能想知道,我们在上一节中刚刚将类别转换为数字标签,现在究竟为什么需要这个?原因很简单。考虑视频游戏类型,如果我们直接把 GenreLabel属性作为特征送到机器学习模型中,它将认为这是一个连续的数值特征,认为10 大于6 ,但这毫无意义,因为运动流派当然不是比竞赛更大或更小,这是本质上不同的值或类别,不能直接比较。因此,我们需要一个额外的编码方案,其中为每个属性的所有不同类别中的每个惟一值或类别创建dummy特征。
One-hot编码方案
考虑到我们有m个标签的任何分类属性的数值表示(转换后),独热编码方案将属性编码或转换为只能包含1或0值的m个二进制特征。因此,分类特征中的每个观察值都转换为一个大小为m的向量,其中只有一个值为1(表示它是活动的)。让我们从我们的Pokémon数据集中选取一个子集,描述两个感兴趣的属性。
poke_df[['Name', 'Generation', 'Legendary']].iloc[4:10]
我们感兴趣的属性是Pokémon的 Generation和的 Legendary状态。第一步是根据前面所学的内容将这些属性转换为数字表示。
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
# transform and map pokemon generations
gen_le = LabelEncoder()
gen_labels = gen_le.fit_transform(poke_df['Generation'])
poke_df['Gen_Label'] = gen_labels
# transform and map pokemon legendary status
leg_le = LabelEncoder()
leg_labels = leg_le.fit_transform(poke_df['Legendary'])
poke_df['Lgnd_Label'] = leg_labels
poke_df_sub = poke_df[['Name', 'Generation', 'Gen_Label',
'Legendary', 'Lgnd_Label']]
poke_df_sub.iloc[4:10]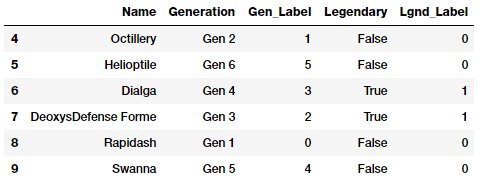
特征 Gen_Label和 Lgnd_Label现在描述了分类特性的数字表示。现在让我们对这些特征应用one-hot编码方案。
# encode generation labels using one-hot encoding scheme
gen_ohe = OneHotEncoder()
gen_feature_arr = gen_ohe.fit_transform(
poke_df[['Gen_Label']]).toarray()
gen_feature_labels = list(gen_le.classes_)
gen_features = pd.DataFrame(gen_feature_arr,
columns=gen_feature_labels)
# encode legendary status labels using one-hot encoding scheme
leg_ohe = OneHotEncoder()
leg_feature_arr = leg_ohe.fit_transform(
poke_df[['Lgnd_Label']]).toarray()
leg_feature_labels = ['Legendary_'+str(cls_label)
for cls_label in leg_le.classes_]
leg_features = pd.DataFrame(leg_feature_arr,
columns=leg_feature_labels)通常,可以使用 fit_transform(…)函数将这两个特征一起编码,方法是将这两个特征一起传递给一个二维数组。但是我们将每个特征单独编码,以便更容易理解。除此之外,我们还可以创建单独的数据帧并相应地标记它们。现在让我们将这些特征帧连接起来,看看最终的结果。
poke_df_ohe = pd.concat([poke_df_sub, gen_features, leg_features], axis=1)
columns = sum([['Name', 'Generation', 'Gen_Label'],
gen_feature_labels, ['Legendary', 'Lgnd_Label'],
leg_feature_labels], [])
poke_df_ohe[columns].iloc[4:10]
你可以看到为 Generation创建了6 个dummy变量或二进制特征,为 Legendary创建了2个,因为它们分别是这些属性中不同类别的总数。类别的活动状态由其中一个dummy变量中的1值表示,这在上面的数据帧中非常明显。
假设你在训练数据上构建了这个编码方案,并构建了一些模型,现在你有了一些新的数据,在进行如下预测之前,必须对这些数据的特征进行设计。
new_poke_df = pd.DataFrame([['PikaZoom', 'Gen 3', True],
['CharMyToast', 'Gen 4', False]],
columns=['Name', 'Generation', 'Legendary'])
new_poke_df
您可以通过在新数据上调用以前构建的“LabeLEncoder”和“OneHotEncoder”对象的“transform(…)”函数。记住我们的工作流,首先我们做转换。
new_gen_labels = gen_le.transform(new_poke_df['Generation'])
new_poke_df['Gen_Label'] = new_gen_labels
new_leg_labels = leg_le.transform(new_poke_df['Legendary'])
new_poke_df['Lgnd_Label'] = new_leg_labels
new_poke_df[['Name', 'Generation', 'Gen_Label', 'Legendary',
'Lgnd_Label']]
一旦我们有了数字标签,现在让我们应用编码方案!
new_gen_feature_arr = gen_ohe.transform(new_poke_df[['Gen_Label']]).toarray()
new_gen_features = pd.DataFrame(new_gen_feature_arr,
columns=gen_feature_labels)
new_leg_feature_arr = leg_ohe.transform(new_poke_df[['Lgnd_Label']]).toarray()
new_leg_features = pd.DataFrame(new_leg_feature_arr,
columns=leg_feature_labels)
new_poke_ohe = pd.concat([new_poke_df, new_gen_features, new_leg_features], axis=1)
columns = sum([['Name', 'Generation', 'Gen_Label'],
gen_feature_labels,
['Legendary', 'Lgnd_Label'], leg_feature_labels], [])
new_poke_ohe[columns]
您还可以通过利用“pandas”中的“to_dummies(…)”函数轻松地应用one-hot编码方案。
gen_onehot_features = pd.get_dummies(poke_df['Generation'])
pd.concat([poke_df[['Name', 'Generation']], gen_onehot_features],
axis=1).iloc[4:10]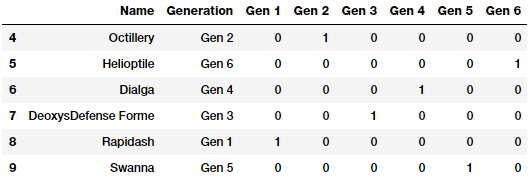
上述数据帧描述了应用于 Generation属性的独热编码方案,结果与预期的结果相同。
Dummy编码策略
dummy编码方案类似于独编码方案,但在dummy编码方案的情况下,当应用于具有m不同标签的分类特征时,我们得到m - 1个二进制特征。因此,分类变量的每个值都被转换成大小为m - 1的向量。额外的特征被完全忽略,因此,如果类别值范围从{0,1,…,m-1} 删除0 *或m -1 特征列,相应的类别值通常由所有零向量(0)* 表示。让我们尝试在Pokemon的 Generation上应用dummy编码方案,去掉第一级二进制编码特征( Gen1)。
gen_dummy_features = pd.get_dummies(poke_df['Generation'],
drop_first=True)
pd.concat([poke_df[['Name', 'Generation']], gen_dummy_features],
axis=1).iloc[4:10]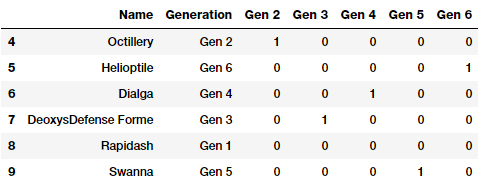
如果需要,还可以选择删除最后一级二进制编码特性( Gen6),如下所示。
If you want, you can also choose to drop the last level binary encoded feature ( Gen6) as follows.
gen_onehot_features = pd.get_dummies(poke_df['Generation'])
gen_dummy_features = gen_onehot_features.iloc[:,:-1]
pd.concat([poke_df[['Name', 'Generation']], gen_dummy_features],
axis=1).iloc[4:10]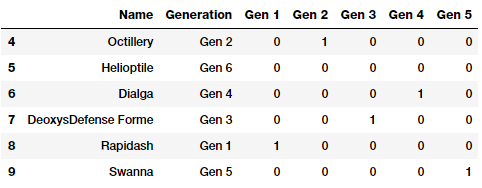
根据上面的描述,很明显,属于被删除特征的类别被表示为一个0向量(0),就像我们前面讨论的那样。
Effect编码方案
effect编码方案实际上与dummy编码方案非常相似,除了在编码过程中,对于表示dummy编码方案中所有0的类别值,编码后的特征或特征向量在effect编码方案中被-1替换。通过下面的示例,这一点将变得更加清晰。
gen_onehot_features = pd.get_dummies(poke_df['Generation'])
gen_effect_features = gen_onehot_features.iloc[:,:-1]
gen_effect_features.loc[np.all(gen_effect_features == 0,
axis=1)] = -1.
pd.concat([poke_df[['Name', 'Generation']], gen_effect_features],
axis=1).iloc[4:10]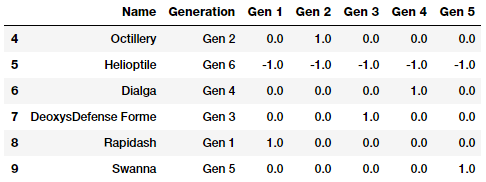
上面的输出清楚地显示了属于 Generation6的Pokemon现在用一个向量-1来表示,而在dummy 编码中是0。
Bin-counting方案
到目前为止,我们所讨论的编码方案通常在分类数据上工作得很好,但是当特征中不同类别的数量变得非常大时,它们就会开始产生问题。对于m个不同标签的特征进行分类,都必须有m个单独的特征。这可以很容易地增加特性集的大小,从而导致诸如存储问题、模型训练时间、空间和内存方面的问题。除此之外,我们还必须处理众所周知的维数诅咒。基本上,由于大量的特征和没有足够的代表性样本,模型性能开始受到影响,常常导致过拟合。

因此,我们需要寻找其他类别数据特征工程方案,用于具有大量可能的类别特征(如IP地址)。bin计数模式是一种有用的模式,用于处理具有许多类别的分类变量。在这个方案中,我们没有使用实际的标签值进行编码,而是使用了基于概率的统计信息,这些信息是关于值和实际目标或响应值的,我们的目标是在建模工作中预测这些值。一个简单的例子是基于过去的历史数据的IP地址和那些在DDOS攻击中使用我们可以建立由任何IP地址引起的DDOS攻击的概率值。利用这些信息,我们可以编码一个输入特征,该特征描述了如果将来出现相同的IP地址,那么引起DDOS攻击的概率值是多少。该方案需要历史数据作为先决条件,是一个复杂的方案。用一个完整的例子来描述这一点目前在这里是困难的,但是有一些在线资源可以参考。
特征哈希方案
特征哈希方案是处理大规模分类特征的另一种有用的特征工程方案。在此方案中,哈希函数通常与预先设置的编码特征(作为预定义长度的向量)一起使用,以便将特征的哈希值用作此预定义向量中的索引,并相应地更新值。由于哈希函数将大量的值映射到一个有限的小值集中,多个不同的值可能会创建相同的哈希,这称为冲突。通常,使用带符号的哈希函数,以便将从哈希中获得的值的符号用作在适当索引处的最终特征向量中存储的值的符号。这应确保较少的碰撞和较少的累积误差。
哈希方案适用于字符串、数字和其他结构(如向量)。您可以将散列输出看作是b bin的有限集合,这样当散列函数应用于相同的值\类别时,它们会根据散列值从b bin分配到相同的bin(或bin的子集)。我们可以预先定义b的值,该值将成为我们使用特征哈希方案编码的每个分类属性的编码特征向量的最终大小。
因此,即使我们在一个特征中有超过1000不同的类别,并且我们将b=10设置为最终的特征向量大小,与使用独热编码方案的1000个二进制特征相比,输出特征集仍然只有10个特性。让我们考虑一下电子游戏数据集中的 Genre属性。
unique_genres = np.unique(vg_df[['Genre']])
print("Total game genres:", len(unique_genres))
print(unique_genres)
Output
------
Total game genres: 12
['Action' 'Adventure' 'Fighting' 'Misc' 'Platform' 'Puzzle' 'Racing'
'Role-Playing' 'Shooter' 'Simulation' 'Sports' 'Strategy']我们可以看到总共有12种类型的电子游戏。如果我们在 Genre特征上使用独热编码方案,我们最终将拥有12个二进制特征。相反,我们现在将通过利用“scikit-learn”的“FeatureHasher”类来使用特征散列方案,该类使用带签名的32位版本的Murmurhash3散列函数。在本例中,我们将预先定义最终的特征向量大小为6。
from sklearn.feature_extraction import FeatureHasher
fh = FeatureHasher(n_features=6, input_type='string')
hashed_features = fh.fit_transform(vg_df['Genre'])
hashed_features = hashed_features.toarray()
pd.concat([vg_df[['Name', 'Genre']], pd.DataFrame(hashed_features)],
axis=1).iloc[1:7]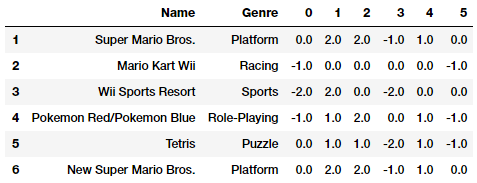
基于上面的输出, Genre分类属性已经使用哈希格式编码为6个特征,而不是12个。我们还可以看到1和6代表了相同类型的游戏Platform,它们被正确地编码为相同的特征向量。
总结
这些示例应该让您对离散分类数据上的特征工程的流行策略有一个很好的了解。如果你阅读了本系列文章的Part 1,你会发现与连续的数字数据相比,使用分类数据稍微有些挑战性,但绝对是有趣的!我们还讨论了使用特征工程处理大型特征空间的一些方法,但是你还应该记住,还有其他一些技术,包括处理大型特性空间的feature selection和dimension reduction方法。我们将在后面的文章中讨论其中的一些方法。
 —
END—
—
END—
英文原文:https://towardsdatascience.com/understanding-feature-engineering-part-2-categorical-data-f54324193e63
更多机器学习,深度学习的相关内容,请关注作者的网易云课堂:
●通俗易懂的深度学习-机器学习
●通俗的TensorFlow

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!![]()















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









