







转载请注明出处:http://blog.csdn.net/gamer_gyt
博主微博:http://weibo.com/234654758
Github:https://github.com/thinkgamer

扫一扫 关注微信公众号!号主 专注于搜索和推荐系统,尝试使用算法去更好的服务于用户,包括但不局限于机器学习,深度学习,强化学习,自然语言理解,知识图谱,还不定时分享技术,资料,思考等文章!
【技术服务】,详情点击查看:https://mp.weixin.qq.com/s/PtX9ukKRBmazAWARprGIAg
TF-IDF算法介绍
TF-IDF(Term Frequency–InverseDocument Frequency)是一种用于资讯检索与文本挖掘的常用加权技术。TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF-IDF实际是TF*IDF,其中TF(Term Frequency)表示词条t在文档Di中的出现的频率,TF的计算公式如下所示:
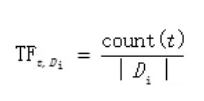
其中IDF(InverseDocument Frequency)表示总文档与包含词条t的文档的比值求对数,IDF的计算公式如下所示:
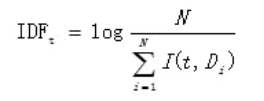
其中N为所有的文档总数,I(t,Di)表示文档Di是否包含词条t,若包含为1,不包含为0。但此处存在一个问题,即当词条t在所有文档中都没有出现的话公式6.2的分母为0,此时就需要对IDF做平滑处理,改善后的IDF计算公式如下所示:
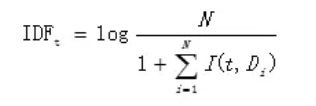
那么最终词条t在文档Di中的TF-IDF值为:TF-IDFt,Di = TFt,Di * IDFt 。
从上述的计算词条t在文档Di中的TF-IDF值计算可以看出:当一个词条在文档中出现的频率越高,且新鲜度低(即普遍度低),则其对应的TF-IDF值越高。
比如现在有一个预料库,包含了100篇(N)论文,其中涉及包含推荐系统(t)这个词条的有20篇,在第一篇论文(D1)中总共有200个技术词汇,其中推荐系统出现了15次,则词条推荐系统的在第一篇论文(D1)中的TF-IDF值为:
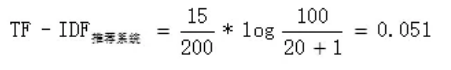
短标题关键词提取
废话不多说,直接上代码,实现如下:
# -*-coding:utf-8-*-
"""
Data: 2018-08
Author: Thinkgamer
"""
import jieba
import math
import jieba.analyse
class TF_IDF:
def __init__(self,file,stop_file):
self.file = file
self.stop_file = stop_file
self.stop_words = self.getStopWords()
# 获取停用词列表
def getStopWords(self):
swlist=list()
for line in open(self.stop_file,"r",encoding="utf-8").readlines():
swlist.append(line.strip())
print("加载停用词完成...")
return swlist
# 加载商品和其对应的短标题,使用jieba进行分词并去除停用词
def loadData(self):
dMap = dict()
for line in open(self.file,"r",encoding="utf-8").readlines():
id,title = line.strip().split("\t")
dMap.setdefault(id, [])
for word in list(jieba.cut(str(title).replace(" ",""), cut_all=False)):
if word not in self.stop_words:
dMap[id].append(word)
print("加载商品和对应的短标题,并使用jieba分词和去除停用词完成...")
return dMap
# 获取一个短标题中的词频
def getFreqWord(self,words):
freqWord = dict()
for word in words:
freqWord.setdefault(word,0)
freqWord[word] += 1
return freqWord
# 统计单词在所有短标题中出现的次数
def getCountWordInFile(self,word,dMap):
count = 0
for key in dMap.keys():
if word in dMap[key]:
count += 1
return count
# 计算TFIDF值
def getTFIDF(self,words,dMap):
# 记录单词关键词和对应的tfidf值
outDic = dict()
freqWord = self.getFreqWord(words)
for word in words:
# 计算TF值,即单个word在整句中出现的次数
tf = freqWord[word]*1.0 / len(words)
# 计算IDF值,即log(所有的标题数/(包含单个word的标题数+1))
idf = math.log(len(dMap)/(self.getCountWordInFile(word,dMap)+1))
tfidf = tf * idf
outDic[word] = tfidf
# 给字典排序
orderDic = sorted(outDic.items(), key=lambda x:x[1], reverse=True)
return orderDic
def getTag(self,words):
# withWeight 用来设置是否打印权重
print(jieba.analyse.extract_tags(words, topK=20, withWeight=True))
if __name__ == "__main__":
# 数据集
file = "data/id_title.txt"
# 停用词文件
stop_file = "data/stop_words.txt"
tfidf=TF_IDF(file,stop_file)
tfidf.getTag(open("data/one","r",encoding="utf-8").read(),)
# dMap 中key为商品id,value为去除停用词后的词
# dMap = tfidf.loadData()
# for id in dMap.keys():
# tfIdfDic = tfidf.getTFIDF(dMap[id],dMap)
# print(id,tfIdfDic)














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









