







The California Gold Rush of 2015 is all about Deep Learning.
It's everywhere, you just don't know how to look.
All of today's excitement in Artificial Intelligence and Machine Learning stems from ground-breaking results in speech and visual object recognition using Deep Learning[1]. These algorithms are being applied to all sorts of data, and the learned deep neural networks outperform traditional expert systems carefully designed by scientists and engineers. End-to-end learning of deep representations from raw data is now possible due to a handful of well-performing deep learning recipes ( ConvNets, Dropout, ReLUs, LSTM, DQN, ImageNet). But if there's one final takeaway that we can extract from decades of machine learning research, is that for many problems going deep isn't a choice, it's often a requirement.
Most of the apps and services you're already using (AirBnB, Snapchat, Twitch.tv, Uber, Yelp, LinkedIn, etc) are quite data-hungry and before you know it, they're all going to go mega-deep. So whether you need to revitalize your data science team with deep learning or you're starting an AI-from-day-one operation, it's pretty clear that everybody is rushing to get some of this Silicon Valley Gold.
From Titans to Gold Miners: Your atypical Gold Rush
Like all great gold rushes, this movement is led by new faces, which are pouring into Silicon Valley like droves. But these aren't your typical unskilled immigrants willing to pick up a hammer, nor your fresh computer science grads with some app-writing skills. The key deep learning players of today (known as the Titans of Deep Learning) are computer science professors and researchers (seldom born in the USA) leaving their academic posts and bringing their students and ideas straight into Silicon Valley.
"
Turn on, Tune in, Dropout" -- Timothy Leary
Recently, Google and Facebook announced that their operations are now being powered by Deep Learning [2,3]. And with most Deep Learning Titans representing the tech giants ( Yann LeCun at Facebook Research, Geoffrey Hinton at Google, Andrew Ng at Baidu), Deep Learning is likely to become one of the most sought after tech skills. With Toyota to invest in $1 Billion in Robotics and Artificial Intelligence Research (November 6, 2015), the announcement of YC Research (October 7, 2015), and the new Google Brain Residency Program "Pre-doc" AI jobs (October 26, 2015), Silicon Valley just got a whole lot more interesting.
Silicon Valley re-defines itself, yet again
To understand why it took so long for Deep Learning to take-off, let's take a brief look at the key technologies which defined Silicon Valley over the last 50 years. The following timeline gives an overview of where Silicon Valley has been and where it's going.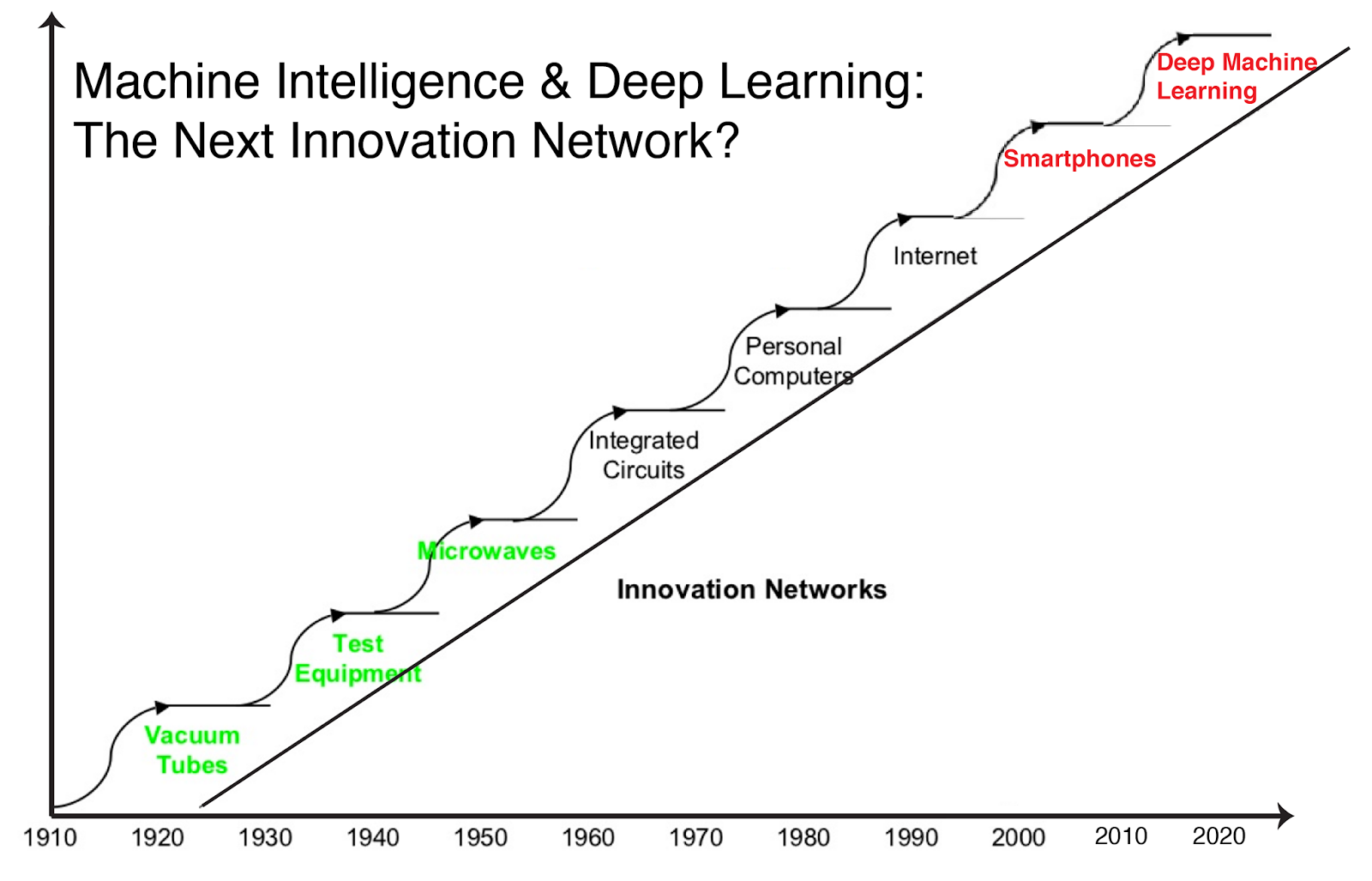
Figure Adapted from Steve Blank's Secret History of Silicon Valley
1970s: Semiconductors
The story of the digital-era starts with semiconductors. "Silicon" in "Silicon Valley" originally referred to the silicon chip or integrated circuit innovations as well as the location (close to Stanford) of much tech-related activity. The dominant firm from that time period was Fairchild Semiconductor International and it eventually gave rise to more recognizable companies like Intel. For a more detailed discussion of this birthing era, take a look at Steve Blank's Secret History of Silicon Valley[4].

Read more about Fairchild at TechCrunch's First Trillion-Dollar Startup
1980s: Personal Computers
Initially computers were quite large and used solely by research labs, government, and big businesses. But it was the personal computer which turned computer programming from a hobby into a vital skill. You no longer needed to be an MIT student to program on one of these badboys. While both Microsoft and Apple were founded in 1975 and 1976, respectively, they persevered due to their pioneering work in graphical user interfaces. This was the birth of the modern user-friendly Operating System. IBM approached Microsoft in 1980, regarding its upcoming personal computer, and from then on Microsoft would be King for a very long time.

See Mac-history's article on Microsoft's relationship with Apple
1990s: Internet
While the nerds at Universities were posting ascii messages on newsgroups in the 90s, service providers in the 1990s like AOL helped make the internet accessible to everyone. Remember getting all those AOL disks in the mail? Buying a chunk of digital real state (your own domain name) became possible and anybody with a dial up connection and some primitive text/HTML skills could start posting online content. With a mission statement like "organize the world's information", it was eventually Google that got the most of out the late 90s dot-com bubble, and remains a very strong player in all things tech.
2000s: Mobile and Social
While the dot-com bubble was about creating an online presence for startups and established companies, the way we use the internet has dramatically changed since 2001. A ton of new social communities have emerged, and due to Facebook we're now stars in our own reality show. Social and advertising have essentially turned the modern internet into a mainstream TV-like experience. The internet is no longer only for the nerds. The kings of this era (Google and Facebook) are also the biggest players in the Deep Learning space, because they have the largest user bases and in-house apps which can benefit most from machine learning.
2010-2015: Deep Learning comes to the party
Spend more than a day in Silicon Valley and you'll hear the popular expression, "Software is eating the world." Rampant spreading of software was only possible once the internet (1990s) AND mobile devices (2000s) became essential parts of our lives. No longer do we physically mail floppy disks, and social media fuels any app that goes viral. What traditional software is missing (or has been missing up until now) is the ability to improve over time from everyday use. If that same software is able to connect to a large Deep Learning system and start improving, then we have a game-changer on our hands. This is already happening with online advertising, digital assistants like Siri, and smart auto-responders like Google's new email auto-reply feature.
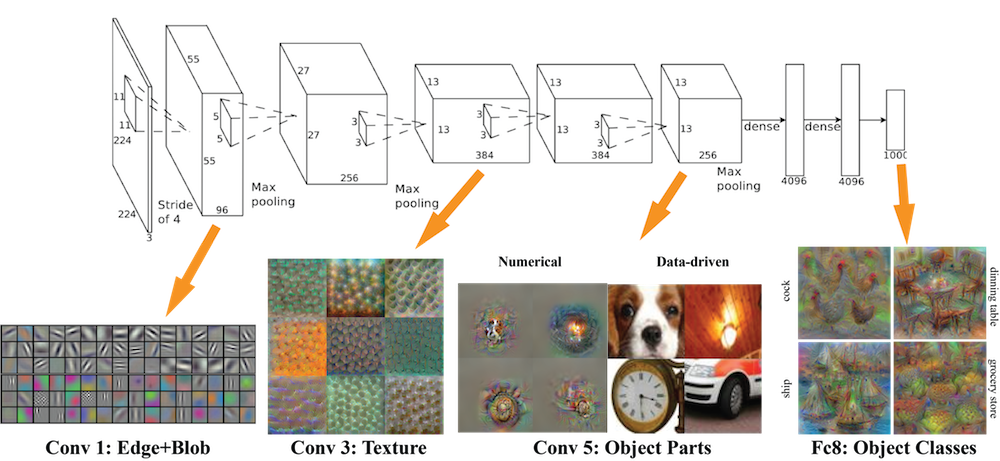
The hierarchical award-winning "AlexNet" Deep Learning architecture
Visualized using MIT's Toolbox for Deep Learning Neuron Visualization
Massive hiring of deep learning experts by the leading tech companies has only begun, but we also should be on the lookout for new ventures built on top of Deep Learning, not just a revitalization of last decade's successes. On this front, keep a close look at the following Deep Learning Cloud Service upstarts: Richard Socher from MetaMind, Matthew Zeiler from Clarifai, and Carlos Guestrin from Dato.
2015-2020: Deep Learning Revitalizes Robotics
Recently it has been shown that Deep Learning can be used to help robots learn tasks involving movement, object manipulation, and decision making[6,7,8,9]. Before Deep Learning, lots of different pieces of robotic software and hardware would have to be developed independently and then hacked together for demo day. Today, you can use one of a handful of "Deep Learning for Robotics recipes" and start watching your robot learn the task you care about.

Robots Learns to Grasp using Deep Learning at Carnegie Mellon University.
Conclusion
Unlike in 1849, the Deep Learning Gold Rush of 2015 is not going to bring some 300,000 gold-seekers in boats to California's mainland. This isn't a bring-your-own-hammer kind of game -- the Titans have already descended from their Ivory Towers and handed us ample mining tools. But it won't hurt to gain some experience with traditional "shallow" machine learning techniques so you can appreciate the power of Deep Learning.I hope you enjoyed today's read and have a better sense of how Silicon Valley is undergoing a transformation. And remember, today's wave of Deep Learning upstart CEOs have PhDs, but once Deep Learning software becomes more user-friendly (TensorFlow?), maybe you won't have to wait so long to dropout.
References
[1] Krizhevsky, A., Sutskever, I. and Hinton, G. E. ImageNet Classification with Deep Convolutional Neural Networks. In NIPS 2012.
[2] D'Onfro, J. Google is 're-thinking' all of its products to include machine learning. Business Insider. October 22, 2015.
[3] D'Onfro, J. How Facebook will use artificial intelligence to organize insane amounts of data into the perfect News Feed and a personal assistant with superpowers. Business Insider. November 3, 2015.
[4] Blank, S. Secret History of Silicon Valley. 2008.
[5] Donglai Wei, Bolei Zhou, Antonio Torralba William T. Freeman. mNeuron: A Matlab Plugin to Visualize Neurons from Deep Models. 2015.
[6] Lerrel Pinto, Abhinav Gupta. Supersizing Self-supervision: Learning to Graspfrom 50K Tries and 700 Robot Hours. arXiv. 2015.
[7] Sergey Levine, Chelsea Finn, Trevor Darrell, Pieter Abbeel. End-to-End Training of Deep Visuomotor Policies. In RSS 2015.
[8] Mnih, Volodymyr, et al. "Human-level control through deep reinforcement learning." Nature 518.7540 (2015): 529-533.
[9] Ian Lenz, Ross Knepper, and Ashutosh Saxena. DeepMPC: Learning Deep Latent Features for Model Predictive Control. In Robotics Science and Systems (RSS), 2015
























 326
326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









