









数据仓库

特点
#面向主题性:数仓的数据在分析时,并不是泛泛而去胡乱分析,而是必须先确定好主题,也就是分析时所占的角度(用户主题,销售主题、地域主题、线路主题,征信主题、赔付主题)
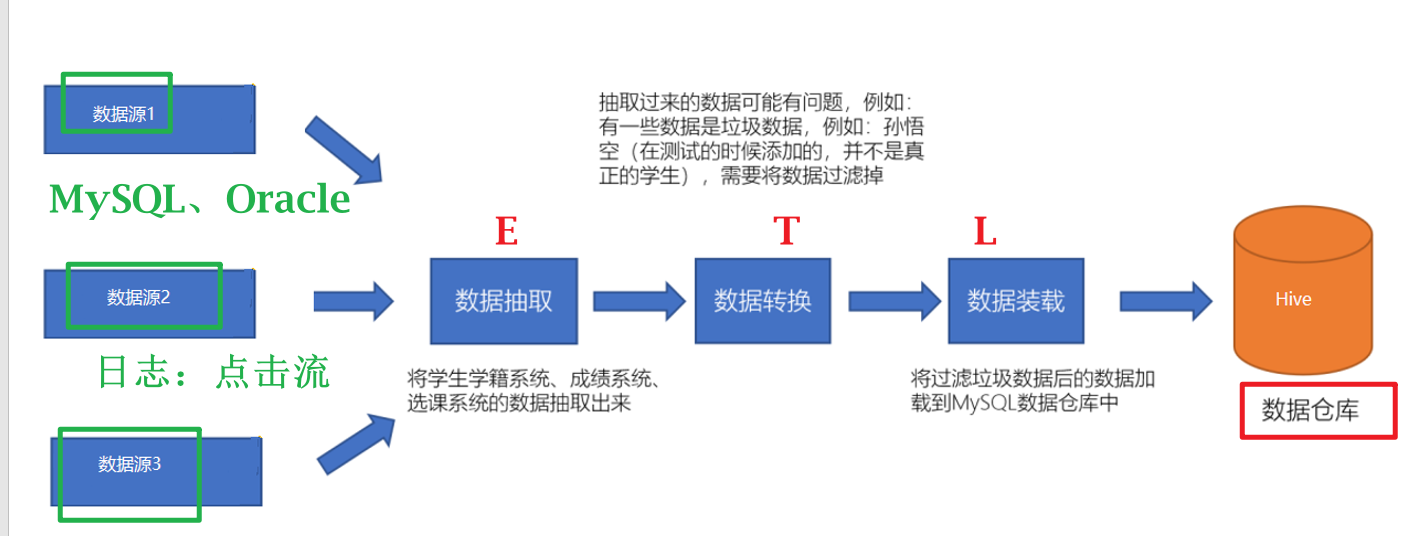
#集成性:数仓的数据往往来自多种数据源,需要将多个数据源的数据进行整合,整合时会面临格式不一致,口径不统一问题,则需要对数据进行处理,这个过程也被称为ETL。
#稳定性:数仓中的数据一般有一个数据采集周期(天,周,月),在下一个采集周期到来之前,数仓中的数据是不变的。
#时变性:数仓中的数据在下一个采集周期到来时,需要对数仓的数据进行更新。数仓数据的采集方式是:T+1
数据库和数据仓库的区别

1、数据库面向业务,面向客户,就是OLTP(On-Line Transaction Processing联机事务处理过程)
2、数据仓库面向分析,面向内部开发人员,就是OLAP(Online Analytical Processing 联机分析处理)
数据仓库的分层
1、数仓的分层是数仓的数据从进来到出去整个数据流向在不同阶段的称呼。
2、每一家公司在数仓分层是不一样的,也没有统一的标准,分层只要适合自己就好
3、分层的好处是在不同的阶段做不同的事情,可以进行明确的阶段分工,提供数据的复用性
4、一般在业界有一个通用的分层标准:
ODS层:存放采集后原始结构化数据
DW层: 存放对ODS层处理后的数据
DWD层:数据拉链表
DWB层:降维
DWS层:初级聚合
APP层:一般存放用于第三方应用的数据
ETL操作
Hive框架-基础
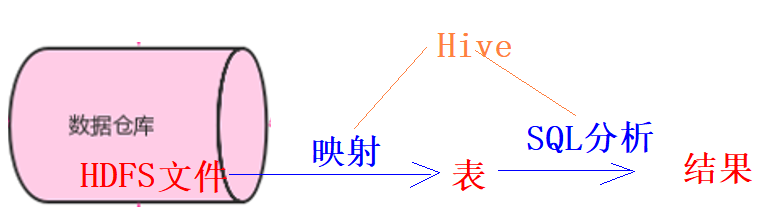
1、Hive是一个数仓管理工具
2、Hive可以替换掉MapReduce对数仓的数据进行分析
3、Hive有两个功能: 第一个是将数仓的结构化数据映射成一张张的表,第二个是提供类SQL语句对表数据进行分析
4、Hive提供的SQL称为HQL,和普通的SQL的功能类似,但是本质完全不同,底层默认就是MapReduce,但是底层也可以改成其他的计算引擎(Tez,Spark)
5、Hive的表数据是存储在HDFS上
6、Hive本身不存任何数据,Hive只是一个工具
#了解:
1)Hive是美国的FaceBook公司研发,Presto也是FaceBook研发
架构
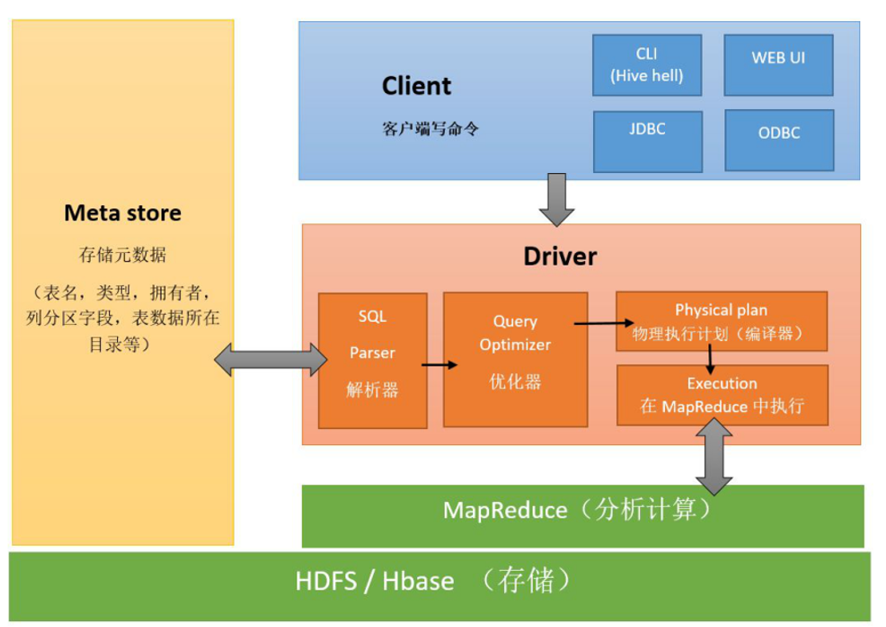
1、Hive将HDFS上的结构化数据文件映射成一张张的表,哪个文件对应哪张表,每张表的表结构信息这些数据被称为元数据MetaData,都需要保存起来,而Hive本身是不存任何数据的,这些数据在本课程中都由第三方数据库MySQL存储。
2、MetaData元数据由Hive的元数据管理器MateStore服务来负责,负责元数据的读取和写入到MySQL
2、HiveSQL底层是MapReduce,而MapReduce的运行必须由Yarn提供资源调度
3、结论:如果你要运行Hive,则必须先启动Hadoop

#HiveSQL的执行过程
(0) HiveSQL被提交给客户端
(1) 解释器将HiveSQL语句转换为抽象语法树(AST)
(2) 编译器将抽象语法树编译为逻辑执行计划
(3) 优化器对逻辑执行计划进行优化
(4) 执行器将逻辑计划切成对应引擎的可执行物理计划
(5) 优化器对物理执行计划进行优化
(6) 物理执行计划交给执行引擎执行
Hive的安装

Hive的交互方式
方式1:
#在命令行输入hive命令
hive
show databases;方式2:
#不进入hive,执行HiveSQL(HQL)命令
hive -e "show databases;"
#不进入hive,执行HiveSQL(HQL)脚本 !!!!!! 生产环境
hive -f /root/test/demo.sql方式3:
#使用Hive第二代客户端来访问
[root@node3 ~]# beeline
Beeline version 2.1.0 by Apache Hive
beeline> !connect jdbc:hive2://node3:10000
Connecting to jdbc:hive2://node3:10000
Enter username for jdbc:hive2://node3:10000: root
Enter password for jdbc:hive2://node3:10000:123456Hive一键启动脚本
这里,我们写一个expect脚本,可以一键启动beenline,并登录到hive。*expect*是建立在tcl基础上的一个自动化交
互套件, 在一些需要交互输入指令的场景下, 可通过*脚本*设置自动进行交互通信。
1、安装expect
yum -y install expect
2、 创建脚本
cd /export/server/hive-3.1.2/bin
vim beenline.exp
#!/bin/expect
spawn beeline
set timeout 5
expect "beeline>"
send "!connect jdbc:hive2://node3:10000\r"
expect "Enter username for jdbc:hive2://node3:10000:"
send "root\r"
expect "Enter password for jdbc:hive2://node3:10000:"
send "123456\r"
interact
3、修改脚本权限
chmod 777 beenline.exp
4、启动脚本
expect beenline.exp
5、退出beeline
0: jdbc:hive2://node3:10000> !quit
6、创建shell脚本
vim /export/server/hive-3.1.2/bin/beeline2
#!/bin/bash
expect /export/server/hive-3.1.2/bin/beeline.exp
chmod 777 /export/server/hive-3.1.2/bin/beeline2
7、最终调用
beeline2方式4:
使用DataGrip连接Hive















 656
656











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









