






Deep Crossing模型是由微软提出,在微软的搜索引擎bing的搜索广告场景当中,用户除了会返回相关的结果,还会返回相应的广告,因此尽可能的增加广告的点击率,是微软所考虑的重中之重。
因此才设计出了Deep Crossing模型来解决这个问题。这个模型的结构如下所示:
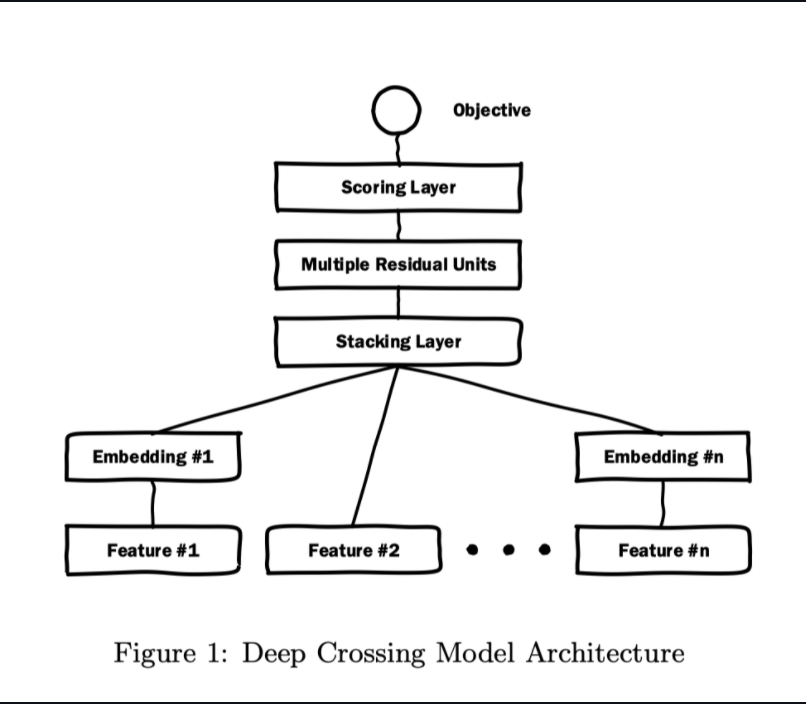
最下面的各种feature是我们输入层,表示了针对特定的应用背景,微软使用的特征如下:
- Query(搜索):用户搜索的关键词;
- Keyword(广告关键词):广告商对自己的产品广告打的标签,用于匹配用户的搜索词;
- Title(标题):广告的标题;
- Landing Page(落地网页):点击广告后跳转的网页;
- Match Type(匹配类型):广告商可选择的关键字与用户查询的匹配程度,通常有四种:精确匹配、短语匹配、宽泛匹配和上下文相关匹配;
- Campaign(广告计划):广告商投放的计划;
- Imression(曝光样例):记录了该广告实际曝光场景的相关信息;
- Click(点击样例):记录了该广告实际点击场景的相关信息;
- Click Through Rate(点击率):广告的历史点击率
- click prediction(预估点击率):另一个CTR模型的预估值;
Embedding层
几乎所有基于深度学习的推荐、CTR预估模型都离不开Embedding层,它的作用是将离散高维的稀疏特征转化为低维的密集型特征。Embedding矩阵的参数通过神经网络的反向传播进行训练。在模型结构中发现Feature #2并没有使用Embedding,因为文章提到“维度小于256的特征“不需要进行Embedding转化。
Stacking层
Stacking层的工作特别简单,就是将所有的Embedding向量、或者未进行Embedding操作的原生特征进行拼接。
Multiple Residual Units层
Deep Crossing模型中的Crossing就是多个残差单元层来实现。该层使用了残差网络的基本单元。也就是我们通常所说的ResNet.
Scoring层
Scoring层就也是输出层。一般情况下对于CTR预估模型,往往是一个二分类问题,因此采用逻辑回归来对点击进行预测,正好逻辑回归模型将我们的CTR,也就是点击率,投射到一个从0-1的空间内,形成一个概率,其意义正好和CTR相同。如果要考虑是一个多分类问题,则可以使用softmax进行预测。
代码用tensorflow2实现如下:
1.model.py
import tensorflow as tf
from tensorflow.keras import Model
from tensorflow.keras.regularizers import l2
from tensorflow.keras.layers import Embedding, Dense, Dropout, Input
from modules import Residual_Units
class Deep_Crossing(Model):
def __init__(self, feature_columns, hidden_units, res_dropout=0., embed_reg=1e-6):
"""
Deep&Crossing
:param feature_columns: A list. sparse column feature information.
:param hidden_units: A list. Neural network hidden units.
:param res_dropout: A scalar. Dropout of resnet.
:param embed_reg: A scalar. The regularizer of embedding.
"""
super(Deep_Crossing, self).__init__()
self.sparse_feature_columns = feature_columns
self.embed_layers = {
'embed_' + str(i): Embedding(input_dim=feat['feat_num'],
input_length=1,
output_dim=feat['embed_dim'],
embeddings_initializer='random_uniform',
embeddings_regularizer=l2(embed_reg))
for i, feat in enumerate(self.sparse_feature_columns)
}
# the total length of embedding layers
embed_layers_len = sum([feat['embed_dim'] for feat in self.sparse_feature_columns])
self.res_network = [Residual_Units(unit, embed_layers_len) for unit in hidden_units]
self.res_dropout = Dropout(res_dropout)
self.dense = Dense(1, activation=None)
def call(self, inputs):
sparse_inputs = inputs
sparse_embed = tf.concat([self.embed_layers['embed_{}'.format(i)](sparse_inputs[:, i])
for i in range(sparse_inputs.shape[1])], axis=-1)
r = sparse_embed
for res in self.res_network:
r = res(r)
r = self.res_dropout(r)
outputs = tf.nn.sigmoid(self.dense(r))
return outputs
def summary(self):
sparse_inputs = Input(shape=(len(self.sparse_feature_columns),), dtype=tf.int32)
Model(inputs=sparse_inputs, outputs=self.call(sparse_inputs)).summary()
2.modules.py
import tensorflow as tf
from tensorflow.keras.layers import Dense, ReLU, Layer
class Residual_Units(Layer):
"""
Residual Units
"""
def __init__(self, hidden_unit, dim_stack):
"""
:param hidden_unit: A list. Neural network hidden units.
:param dim_stack: A scalar. The dimension of inputs unit.
"""
super(Residual_Units, self).__init__()
self.layer1 = Dense(units=hidden_unit, activation='relu')
self.layer2 = Dense(units=dim_stack, activation=None)
self.relu = ReLU()
def call(self, inputs, **kwargs):
x = inputs
x = self.layer1(x)
x = self.layer2(x)
outputs = self.relu(x + inputs)
return outputs
3.train.py
import tensorflow as tf
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.losses import binary_crossentropy
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.metrics import AUC
from model import Deep_Crossing
from data_process.criteo import create_criteo_dataset
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
if __name__ == '__main__':
# =============================== GPU ==============================
# gpu = tf.config.experimental.list_physical_devices(device_type='GPU')
# print(gpu)
# If you have GPU, and the value is GPU serial number.
os.environ['CUDA_VISIBLE_DEVICES'] = '4'
# ========================= Hyper Parameters =======================
# you can modify your file path
file = '../dataset/Criteo/train.txt'
read_part = True
sample_num = 5000000
test_size = 0.2
embed_dim = 8
dnn_dropout = 0.5
hidden_units = [256, 128, 64]
learning_rate = 0.001
batch_size = 4096
epochs = 10
# ========================== Create dataset =======================
feature_columns, train, test = create_criteo_dataset(file=file,
embed_dim=embed_dim,
read_part=read_part,
sample_num=sample_num,
test_size=test_size)
train_X, train_y = train
test_X, test_y = test
# ============================Build Model==========================
mirrored_strategy = tf.distribute.MirroredStrategy()
with mirrored_strategy.scope():
model = Deep_Crossing(feature_columns, hidden_units)
model.summary()
# =========================Compile============================
model.compile(loss=binary_crossentropy, optimizer=Adam(learning_rate=learning_rate),
metrics=[AUC()])
# ============================model checkpoint======================
# check_path = 'save/deep_crossing_weights.epoch_{epoch:04d}.val_loss_{val_loss:.4f}.ckpt'
# checkpoint = tf.keras.callbacks.ModelCheckpoint(check_path, save_weights_only=True,
# verbose=1, period=5)
# ===========================Fit==============================
model.fit(
train_X,
train_y,
epochs=epochs,
callbacks=[EarlyStopping(monitor='val_loss', patience=2, restore_best_weights=True)], # checkpoint
batch_size=batch_size,
validation_split=0.1
)
# ===========================Test==============================
print('test AUC: %f' % model.evaluate(test_X, test_y, batch_size=batch_size)[1])















 2323
2323











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









