







 本文介绍了Stacking集成学习方法,通过使用单个和多个机器学习模型进行stacking,结合交叉验证和模型融合,提升模型性能。文章详细讲解了stacking的原理,并提供了Python代码实现,包括基本实现和配合grid search进行超参数调整。
本文介绍了Stacking集成学习方法,通过使用单个和多个机器学习模型进行stacking,结合交叉验证和模型融合,提升模型性能。文章详细讲解了stacking的原理,并提供了Python代码实现,包括基本实现和配合grid search进行超参数调整。
Stacking集成学习在各类机器学习竞赛当中得到了广泛的应用,尤其是在结构化的机器学习竞赛当中表现非常好。今天我们就来介绍下stacking这个在机器学习模型融合当中的大杀器的原理。并在博文的后面附有相关代码实现。
总体来说,stacking集成算法主要是一种基于“标签”的学习,有以下的特点:
用法:模型利用交叉验证,对训练集进行预测,从而实现二次学习
优点:可以结合不同的模型
缺点:增加了时间开销,容易造成过拟合
关键点:模型如何进行交叉训练?
下面我们来看看stacking的具体原理是如何进行实现的,stacking又是如何实现交叉验证和训练的。
一.使用单个机器学习模型进行stacking
第一种stacking的方法,为了方便大家理解,因此只使用一个机器学习模型进行stacking。stacking的方式如下图所示:

我们可以边看图边理解staking过程。我们先看training data,也就是训练数据(训练集)。我们使用同一个机器学习model对训练数据进行了5折交叉验证(当然在实际进行stacking的时候,你也可以使用k折交叉验证,k等于多少都可以,看你自己,一般k=5或者k=10,k=5就是五折交叉验证),也就是每次训练的时候,将训练数据拆分成5份。其中四份用于训练我们的模型,另外剩下的一份将训练好的模型,在这部分上对数据进行预测predict出相应的label。由于使用了5折交叉验证,这样不断训练,一共经过5次交叉验证,我们就产生了模型对当前训练数据进行预测的一列label。而这些label也可以当作我们的新的训练特征,将预测出来的label作为一列新的特征插入到我们的训练数据当中。
插入完成后,将我们新的tranning set再次进行训练,得到我们新,也是最后的model,也就是图中的model6。这样就完成了第一次stacking,对于testing set而言,我们使用model 1/2/3/4/5分别对图中下面所对应的testing data进行预测,然后得到testing set的新的一列feature,或者称之为label。
这样,我们就完成了一次stacking的过程。
然而,我们不仅可以stacking仅仅一次,我们还可以对当前训练出来的模型再次进行stacking,也就是重复刚才的过程,这样我们的训练集又会多出一个新的一列,每stacking一次,数据就会多出一列。但是如果仅仅用一个模型进行stakcing,效果往往没有那么好,因为这样我们的数据和模型并不具备多样性,也就无法从数学上保证我们数据的“独立性”,树模型比如bagging能够达到很好的效果,包括我们的stacking,模型的多样性越大,差异越大,集成之后往往会得到更好的收益,这个在数学上有严格的证明的,可以通过binomial distribution的方法来证明,大家了解即可。
因此这里介绍,如何使用多个机器学习模型进行stacking,这种方法在机器学习竞赛当中也更加常见。
二.使用多个机器模型进行stacking
使用多个机器学习模型进行stacking其实就是每使用一个模型进行训练,就多出一个训练集的feature,也就是将训练集多出一列。如下图所示:
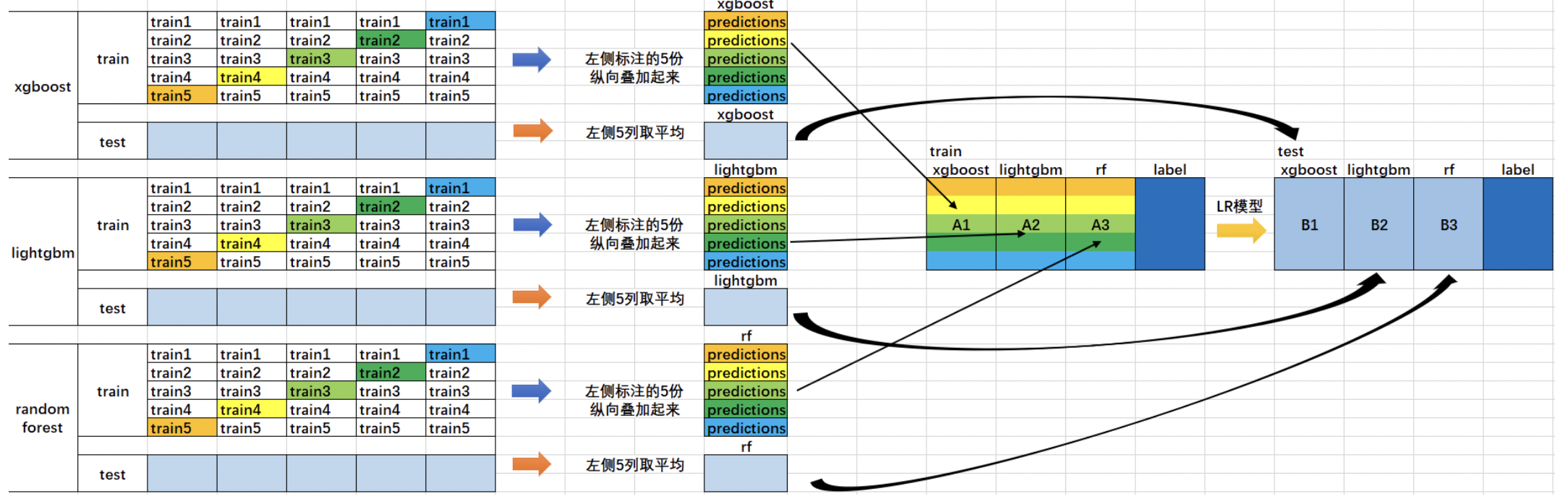
在这张图当中,我们使用了xgboost,lightgbm,random forest分别对同一个数据集做了训练,xgboost训练完后,trainning set多出一列,lightgbm训练完成后,又多出一列random forest训练完成后,又多出一列。因此我们的traning set一共多出了三列。这样我们再用多出这三列的数据重新使用新的机器学习模型进行训练,就可以得到一个更加完美的模型啦!这也就是多个不同机器学习模型进行stacking的原理。同时 ,我们也可以对多个机器学习模型进行多次堆叠,也就是进行多次stakcing的操作。
三.stacking模型代码实现(基本实现)
由于sklearn并没有直接对Stacking的方法,因此我们需要下载mlxtend工具包(pip install mlxtend)
# 1. 简单堆叠3折CV分类,默认为3,可以使用cv=5改变为5折cv分类
from sklearn import datasets
iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingCVClassifier
RANDOM_SEED = 42
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=RANDOM_SEED)
clf3 = GaussianNB()
lr = LogisticRegression()
# Starting from v0.16.0, StackingCVRegressor supports
# `random_state` to get deterministic result.
sclf = StackingCVClassifier(classifiers=[clf1, clf2, clf3], # 第一层分类器
meta_classifier=lr, # 第二层分类器,并非表示第二次stacking,而是通过logistic regression对新的训练特征数据进行训练,得到predicted label
random_state=RANDOM_SEED)
print('3-fold cross validation:\n')
for clf, label in zip([clf1, clf2, clf3, sclf], ['KNN', 'Random Forest', 'Naive Bayes','StackingClassifier']):
scores = cross_val_score(clf, X, y, cv=3, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))
输出:
3-fold cross validation:
Accuracy: 0.91 (+/- 0.01) [KNN]
Accuracy: 0.95 (+/- 0.01) [Random Forest]
Accuracy: 0.91 (+/- 0.02) [Naive Bayes]
Accuracy: 0.93 (+/- 0.02) [StackingClassifier]
画出决策边界:
# 我们画出决策边界
from mlxtend.plotting import plot_decision_regions
import matplotlib.gridspec as gridspec
import itertools
gs = gridspec.GridSpec(2, 2)
fig = plt.figure(figsize=(10,8))
for clf, lab, grd in zip([clf1, clf2, clf3, sclf],
['KNN',
'Random Forest',
'Naive Bayes',
'StackingCVClassifier'],
itertools.product([0, 1], repeat=2)):
clf.fit(X, y)
ax = plt.subplot(gs[grd[0], grd[1]])
fig = plot_decision_regions(X=X, y=y, clf=clf)
plt.title(lab)
plt.show()

如果想要更加清楚地指定,我们的多个机器学习学到的数据输出的概率(假设我们的label为概率),是否会被平均,按照多个模型的平均值来变成我们的训练数据的列(个人不太推荐这么干,因为一旦平均之后,其实就缺失了一些模型差异性的信息和特征,这样在某些情况下反而得不太好的结果)。因此我们使用以下的代码:
# 使用概率作为元特征
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
lr = LogisticRegression()
sclf = StackingCVClassifier(classifiers=[clf1, clf2, clf3],
use_probas=True,
average_probas = False,
meta_classifier=lr,
random_state=42)
#average_probas = False 表示不对概率进行平均
print('3-fold cross validation:\n')
for clf, label in zip([clf1, clf2, clf3, sclf],
['KNN',
'Random Forest',
'Naive Bayes',
'StackingClassifier']):
scores = cross_val_score(clf, X, y,
cv=3, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label))
输出:
3-fold cross validation:
Accuracy: 0.91 (+/- 0.01) [KNN]
Accuracy: 0.95 (+/- 0.01) [Random Forest]
Accuracy: 0.91 (+/- 0.02) [Naive Bayes]
Accuracy: 0.95 (+/- 0.02) [StackingClassifier]
四.Stacking配合grid search网格搜索实现超参数调整
# 3. 堆叠5折CV分类与网格搜索(结合网格搜索调参优化)
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from mlxtend.classifier import StackingCVClassifier
# Initializing models
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=RANDOM_SEED)
clf3 = GaussianNB()
lr = LogisticRegression()
sclf = StackingCVClassifier(classifiers=[clf1, clf2, clf3],
meta_classifier=lr,
random_state=42)
params = {'kneighborsclassifier__n_neighbors': [1, 5],
'randomforestclassifier__n_estimators': [10, 50],
'meta_classifier__C': [0.1, 10.0]}
grid = GridSearchCV(estimator=sclf,
param_grid=params,
cv=5,
refit=True)
grid.fit(X, y)
cv_keys = ('mean_test_score', 'std_test_score', 'params')
for r, _ in enumerate(grid.cv_results_['mean_test_score']):
print("%0.3f +/- %0.2f %r"
% (grid.cv_results_[cv_keys[0]][r],
grid.cv_results_[cv_keys[1]][r] / 2.0,
grid.cv_results_[cv_keys[2]][r]))
print('Best parameters: %s' % grid.best_params_)
print('Accuracy: %.2f' % grid.best_score_)
输出:
0.947 +/- 0.03 {'kneighborsclassifier__n_neighbors': 1, 'meta_classifier__C': 0.1, 'randomforestclassifier__n_estimators': 10}
0.933 +/- 0.02 {'kneighborsclassifier__n_neighbors': 1, 'meta_classifier__C': 0.1, 'randomforestclassifier__n_estimators': 50}
0.940 +/- 0.02 {'kneighborsclassifier__n_neighbors': 1, 'meta_classifier__C': 10.0, 'randomforestclassifier__n_estimators': 10}
0.940 +/- 0.02 {'kneighborsclassifier__n_neighbors': 1, 'meta_classifier__C': 10.0, 'randomforestclassifier__n_estimators': 50}
0.953 +/- 0.02 {'kneighborsclassifier__n_neighbors': 5, 'meta_classifier__C': 0.1, 'randomforestclassifier__n_estimators': 10}
0.953 +/- 0.02 {'kneighborsclassifier__n_neighbors': 5, 'meta_classifier__C': 0.1, 'randomforestclassifier__n_estimators': 50}
0.953 +/- 0.02 {'kneighborsclassifier__n_neighbors': 5, 'meta_classifier__C': 10.0, 'randomforestclassifier__n_estimators': 10}
0.953 +/- 0.02 {'kneighborsclassifier__n_neighbors': 5, 'meta_classifier__C': 10.0, 'randomforestclassifier__n_estimators': 50}
Best parameters: {'kneighborsclassifier__n_neighbors': 5, 'meta_classifier__C': 0.1, 'randomforestclassifier__n_estimators': 10}
Accuracy: 0.95
得到最后最好的参数如上。当然如果,你想要更好的搜索参数,可以使用贝叶斯搜索参数,或者随机参数搜索法,对参数进行搜索。
结语:在这篇博文当中,我论述了stacking的原理和python的代码实现,希望大家读完后会有收获。如果觉得看了有收获的同学,请在下方点个赞,推荐一下,谢谢啦!
参考文献:
1.https://github.com/Geeksongs/ensemble-learning/blob/main/CH5-%E9%9B%86%E6%88%90%E5%AD%A6%E4%B9%A0%E4%B9%8Bblending%E4%B8%8Estacking/Stacking.ipynb
2.https://www.cnblogs.com/Christina-Notebook/p/10063146.html


















 3867
3867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









