






查询语法
[WITH CommonTableExpression (,CommonTableExpression)*]
SELECT [ALL | DISTINCT]select_expr, select_expr,...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list]]
[LIMIT [offset,] rows];
语法顺序
select .. distinct .. from .. where .. group by .. having .. order by .. limit
执行顺序
from .. where .. group by .. select .. having .. distinct .. order by .. limit
Map阶段
1.执行 from,进行表的查找与加载;
2.执行 where 谓词下推
3.执行 join 操作
4.执行输出列的数据 select 字段 和分组字段
5.map端哈希分组 输出
reduce阶段
1.执行reduce端合并分组
2.执行select
3.执行having过滤
注意:
(1)SQL 语言大小写不敏感。
(2)SQL 可以写在一行或者多行
(3)关键字不能被缩写也不能分行
(4)各子句一般要分行写。
(5)使用缩进提高语句的可读性。
基础查询回顾
准备数据
1,联想,5000,c001
2,海尔,3000,c001
3,雷神,5000,c001
4,JACK JONES,800,c002
5,真维斯,200,c002
6,花花公子,440,c002
7,劲霸,2000,c002
8,香奈儿,800,c003
9,相宜本草,200,c003
10,面霸,5,c003
11,好想你枣,56,c004
12,香飘飘奶茶,1,c005
13,果9,1
创建表
create table t_product(
pid int,
pname string,
price double,
cid string
)row format delimited fields terminated by ",";
load data local inpath "/root/product.txt" into table t_product;
简单查询
-- 查询常量值
SELECT 100;
SELECT 'hello';
-- 查询表达式
SELECT 100%98;
-- 查询函数
SELECT `current_date`();
SELECT VERSION();
-- 两个操作数都为数值型,则做加法运算
SELECT 100+90;
-- 只要其中一方为字符型,试图将字符型数值转换成数值型 如果转换成功,则继续做加 法运算
SELECT '123'+90;
-- 如果转换失败,则将字符型数值转换成null
SELECT 'hello'+90;
-- 只要其中一方为NULL,则结果肯定为NULL
SELECT NULL+10;
-- 连接字符串
SELECT CONCAT('a','b','c');
-- 查询所有的商品.开发时尽量别写 *
select * from t_product;
-- 查询商品名和商品价格.
select pname,price from t_product;
-- 别名查询.使用的关键字是as(as可以省略的).表别名:
select * from t_product as p;
-- 别名查询.使用的关键字是as(as可以省略的).列别名:
select pname pn from t_product;
-- 去掉重复值.
select distinct price from t_product;
-- 查询结果是表达式(运算查询):将所有商品的价格+10元进行显示.
select pname,price+10 from t_product;
条件查询
-- 查询商品名称为“花花公子”的商品所有信息:
SELECT * FROM t_product WHERE pname = '花花公子';
-- 查询价格为800商品
SELECT * FROM t_product WHERE price = 800;
-- 查询价格不是800的所有商品
SELECT * FROM t_product WHERE price != 800;
SELECT * FROM t_product WHERE price <> 800;
SELECT * FROM t_product WHERE NOT(price = 800);
-- 查询商品价格大于60元的所有商品信息
SELECT * FROM t_product WHERE price > 60;
-- 查询商品价格在200到1000之间所有商品
SELECT * FROM t_product WHERE price >= 200 AND price <=1000;
SELECT * FROM t_product WHERE price BETWEEN 200 AND 1000;
-- 查询商品价格是200或800的所有商品
SELECT * FROM t_product WHERE price = 200 OR price = 800;
SELECT * FROM t_product WHERE price IN (200,800);
-- 查询含有'霸'字的所有商品
SELECT * FROM t_product WHERE pname LIKE '%霸%';
-- 查询以'香'开头的所有商品
SELECT * FROM t_product WHERE pname LIKE '香%';
-- 查询第二个字为'想'的所有商品
SELECT * FROM t_product WHERE pname LIKE '_想%';
-- rlike后面跟正则表达式
select * from t_product where pname rlike "茶$";
select 'footbar' rlike '^f.*r$';
select '123456' rlike '^\\d+$';
-- 商品没有分类的商品
SELECT * FROM t_product WHERE cid is null;
-- 查询有分类的商品
SELECT * FROM t_product WHERE cid IS NOT NULL;
聚合函数
-- 查询商品的总条数
SELECT COUNT(*) FROM t_product;
-- 查询价格大于200商品的总条数
SELECT COUNT(*) FROM t_product WHERE price > 200;
-- 查询分类为'c001'的所有商品的总和
SELECT SUM(price) FROM t_product WHERE cid = 'c001';
-- 查询分类为'c002'所有商品的平均价格
SELECT AVG(price) FROM t_product WHERE cid = 'c002';
-- 查询商品的最大价格和最小价格
SELECT MAX(price),MIN(price) FROM t_product;
分组
having与where的区别:
- having是在分组后对数据进行过滤.
where是在分组前对数据进行过滤
- having后面可以使用分组函数(统计函数)
where后面不可以使用分组函数。
-- 统计各个分类商品的个数
SELECT category_id ,COUNT(*) FROM t_product GROUP BY category_id ;
-- 统计各个分类商品的个数,且只显示个数大于1的信息
SELECT cid ,COUNT(*) FROM t_product GROUP BY cid HAVING COUNT(*) > 1;
-- 这种更好一些 having后直接得出结果 避免2次计算
SELECT cid ,COUNT(*) productcount FROM t_product GROUP BY cid HAVING productcount > 1;
分页
-- 0索引开始 取两条
select * from t_product limit 0,2;
select * from t_product limit 2;
-- 2索引开始取两条
select * from t_product limit 2,2;
(当前页-1)*pageSize
union / union all
-- union去重
select * from t_product where pid <=2
union
select * from t_product where pid <= 3 ;
-- union all不去重
select * from t_product where pid <=2
union all
select * from t_product where pid <= 3 ;
排序
全局排序
- order by 会对输入做全局排序,因此只有一个reducer,会导致当输入规模较大时,需要较长的计算时间
- 使用 order by子句排序 :ASC(ascend)升序(默认)| DESC(descend)降序
- order by放在结尾 有null的时候 可以使用nulls last ,nulls first指定null值的位置
select * from t_product order by cid nulls first ;
select * from t_product order by cid nulls last ;
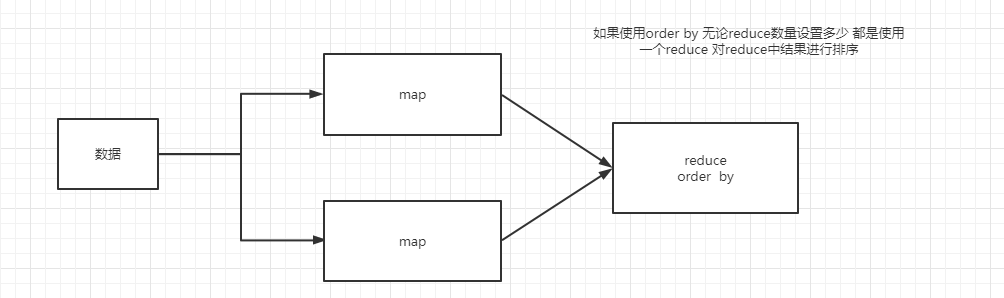
-- 设置reduce个数为2个
set mapreduce.job.reduces = 2;
-- 查询每个分类的最高价格是多少 将结果导入到 hdfs文件夹中 不排序
INSERT overwrite directory "/pro" select cid,max(price) from t_product group by cid ;

-- 设置reduce个数为2个
set mapreduce.job.reduces = 2;
-- 查询每个分类的最高价格是多少 将结果导入到 hdfs文件夹中 使用order by 全局排序 最终产生1个文件
INSERT overwrite directory "/pro" select cid,max(price) from t_product group by cid order by max(price) ;

局部排序
- Sort by为每个reducer产生一个排序文件。每个Reducer内部进行排序.
- 如果用sort by进行排序,并且设置mapred.reduce.tasks>1,则sort by 只保证每个reducer的输出
有序,不保证全局有序。
-- 设置reduce个数为2个
set mapreduce.job.reduces = 2;
select * from t_product sort by price;
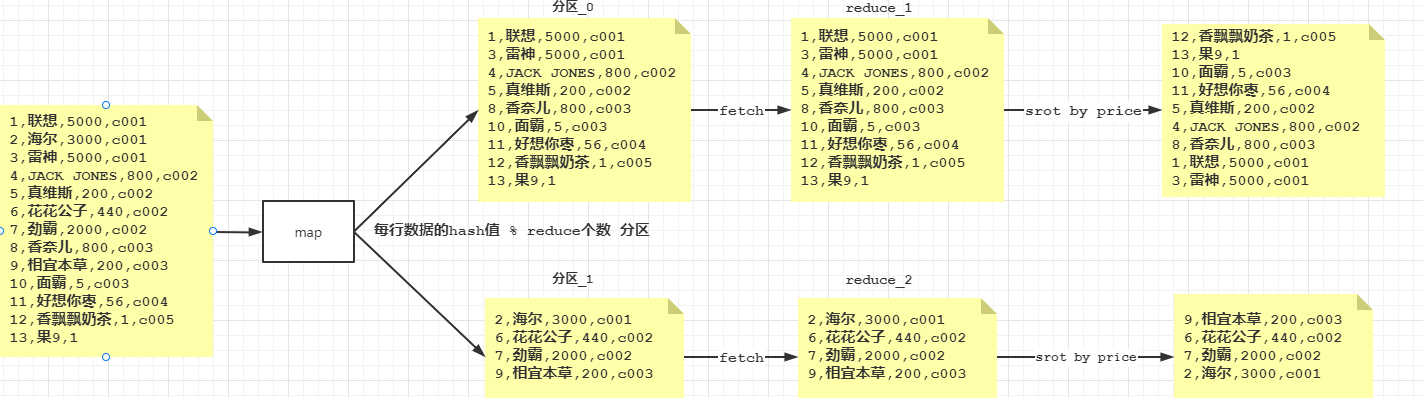
- distribute by(字段)根据指定的字段将数据分到不同的reducer.如果不指定默认按照每行的hash值分区.
- 类似MR中partition,进行分区,结合sort by使用。(注意:distribute by 要在sort by之前)
set mapreduce.job.reduces = 2;
select * from t_product distribute by pid sort by price;

- cluster by(字段)除了具有distribute by的功能外,还会对该字段进行排序
- 当distribute by(字段) 和sort by(字段) 是同一个字段时,可以直接使用cluster by(字段) 并且只能是升序.
set mapreduce.job.reduces = 2;
select * from t_product cluster by pid;
select * from t_product distribute by pid sort by price;
多表查询
关联查询复习
category.txt
c001,家电
c002,服饰
c003,化妆品
c004,零食
c005,奶茶
c006,蔬菜
create table t_category(
cid string,
cname string
)row format delimited fields terminated by ",";
load data local inpath "/root/category.txt" into table t_category;
select * from t_category;
交叉查询
--交叉查询取的是两张表的笛卡尔积
select * from t_category,t_product;
select * from t_category cross join t_product;
内连接
--内连接查询的是两张表的交集
-- 隐式内连接
select p.*,c.cname from t_category c,t_product p where c.cid = p.cid;
-- 显示内连接
select p.*,c.cname from t_category c inner join t_product p on c.cid = p.cid;
select p.*,c.cname from t_category c join t_product p on c.cid = p.cid;
外连接
-- 左外连接 以左表为基准 左表有的都查询出来 右表没有 显示null值
select * from t_category c left join t_product p on c.cid = p.cid;
-- 左外连接 查询左表有 右表没有的记录
select * from t_category c left join t_product p on c.cid = p.cid where p.cid is null;
-- 右外连接 以右表为基准 右表有的内容都查询出来 左表没有 显示null值
select * from t_category c right join t_product p on c.cid = p.cid ;
-- 右外连接 查询右表有 但是左表没有的数据
select * from t_category c right join t_product p on c.cid = p.cid where c.cid is null;
全外连接
-- 查询两张表的并集
select * from t_category c full join t_product p on c.cid = p.cid;
-- 查询张表不相交的 A表有B表没有 B表有A表没有
select * from t_category c full outer join t_product p on c.cid = p.cid where c.cid is null
or p.cid is null;
**左半开连接 **
左半开连接(left semi join) 会返回左表的记录,前提是其记录对于右表满足on语句的判定条件
相当于 inner join后值返回左表的结果
select * from t_category c left semi join t_product p on c.cid = p.cid;
特点
1.JOIN 子句中右边的表只能在 ON 子句中设置过滤条件,在 WHERE 子句、SELECT 子句或其他地方过滤都不行select * from t_category c left semi join t_product p on c.cid = p.cid where p.price>1000; -- 报错--正确 select * from t_category c left semi join t_product p on c.cid = p.cid and p.price>1000;2.最后 select 的结果只许出现左表。
-- 报错 不能查询右表信息 select p.* from t_category c left semi join t_product p on c.cid = p.cid;3.遇到右表重复记录,左表会跳过,而 join 则会一直遍历。这就导致右表有重复值得情况下 left semi join 只产生一条,join 会产生多条,也会导致 left semi join 的性能更高。
select * from t_category c left semi join t_product p on c.cid = p.cid ; -- 效率高 去重 select c.* from t_category c inner join t_product p on c.cid = p.cid ;-- 效率低 不去重
join查询注意事项
-
允许使用复杂的连接表达式,支持非等值查询
select a.* from a left join b on a.id <> b.id; -
同一查询可以连接2个以上的表
select a.val,b.val,c.val from a join b on a.key = b.key1 join c on c.key = b.key2 -
如果每个表在连接子句中使用相同的列,则Hive将多个表上的连接转为单个mr作业
-- 由于联接中仅涉及b的key1列 因此转换为1个MR作业执行 select a.val,b.val,c.val from a join b on a.key = b.key1 join c on c.key = b.key1; -- 会转换为两个mr作业 第一个mr作业 a与b连接 将结果与c连接到第二个mr作业中 select a.val,b.val,c.val from a join b on a.key = b.key1 join c on c.key = b.key2; -
join时会缓冲表,因此,将大表放置在最后有助于减少reducer阶段缓存数据所需要的内存.
子查询复习
Hive当下版本支持子查询,支持在where后子查询,也可以在from后的子查询.但是不支持在select后的子查询.
-- 一条语句的查询结果 作为另一条语句的查询条件 where后的子查询
-- 查询化妆品的记录
select * from t_product where cid = (select cid from t_category where cname = '化妆品' );
select * from t_product where cid in (select cid from t_category where cname = '服饰' or cname="家电" );
-- 将一条语句的查询结果 作为一张伪表 from后的子查询
select p.* from
(select * from t_category where cname = '化妆品') c
inner join t_product p
on c.cid = p.cid;
hive支持相关子查询
先执行主查询,再针对主查询返回的每一行数据执行子查询,如果子查询能够返回行,则这条记录就保留,否则就不保留。
-- 非相关子查询 非相关子查询执行顺序是先执行子查询,再执行主查询。
select * from t_product where cid in (select cid from t_category where cname = '化妆品' );
--相关子查询
select * from t_product p where exists (select * from t_category c where c.cid = p.cid and c.cname ='化妆品' );
-- 如果查询数量比较小时:非相关子查询比相关子查询效率高。
-- 如果查询数量比较大时:一般不建议使用in,因为in的效率比较低,我们可以使用相关子查询。
CTE表达式
公用表表达式(CTE )是一个临时结果集∶该结果集是从WITH子句中指定的简单查询派生而来的,紧接在SELECT或INSERT关键字之前。CTE仅在单个语句的执行范围内定义。
CTE可以在SELECT,INSERT,CREATE TABLE AS SELECT或CREATE VIEW AS SELECT语句中使用。
-- 在商品表中查询分类为c001的商品 将查询结果看做成一张伪表 在这张伪表的基础上查询pid和pname
with t1 as (select * from t_product where cid = 'c001')
select pid, pname
from t1;
-- from风格
with t1 as (select * from t_product where cid = 'c001')
from t1
select pid, pname;
-- 链式
with t1 as (select * from t_category where cname = '化妆品'),
t2 as (select cid from t1)
select *
from t_product
inner join t2 on t_product.cid = t2.cid;
-- union
with t1 as (select * from t_product where price between 200 and 1000),
t2 as (select * from t_product where price > 3000)
select *
from t1
union
select *
from t2;
--建表
create table p1 like t_product;
insert overwrite table p1
select *
from t_product
where price > 3000;
with t1 as (select * from t_product where price > 3000)
insert
overwrite
table
p1
select *
from t1;
create table p2 as
with t1 as (select * from t_product where price > 3000)
select *
from t1;
case when语法
case 字段
when 值 then
when 值 then
when 值 then
else
end as 别名
case
when expr1 and/or expr2 then
when expr1 and/or expr2 then
when expr1 and/or expr2 then
else
end as 笔名
select *, `if`(sex == '男', 'man', 'woman')
from t_user;
-- 第一种格式
select *,
case sex
when '男' then 'man'
when '女' then 'woman'
else 'other' end as english_sex
from t_user;
-- 第二种格式
select *,
case
when sex == '男' then 'man'
when sex == '女' then 'woman'
else 'other'
end as english_sex
from t_user;
select *,
`if`(age >= 10 and age < 20, '10~20',
`if`(age >= 20 and age < 30, '20~30', `if`(age > 30 and age < 40, '30~40', 'other')))
from t_user;
select *,
case
when age >= 10 and age < 20 then '10~20'
when age >= 20 and age < 30 then '20~30'
when age >= 30 and age < 40 then '30~40'
else 'other' end as age_stage
from t_user;















 4270
4270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











