







Hadoop的分布式计算框架(MapReduce)-- 适合离线计算

核心思想: 移动计算而不移动数据。
MR是计算来自HDFS上的数据,可以看到,HDFS是大数据的存储,MR是大数据的计算。
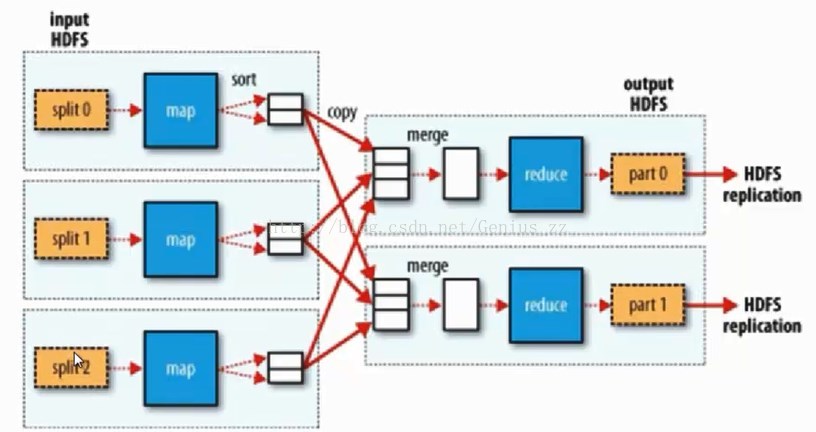
MapReduce流程:input->Splitting->Mapping->Shuffling->Reducing-> result
MapReduce程序读取的数据,都是存储在HDFS的数据,最后的结果,也是要保存在HDFS中,因此,MapReduce要解决的第一个问题就是数据的切分问题。
下面以wordcount为例:

Split大小的计算

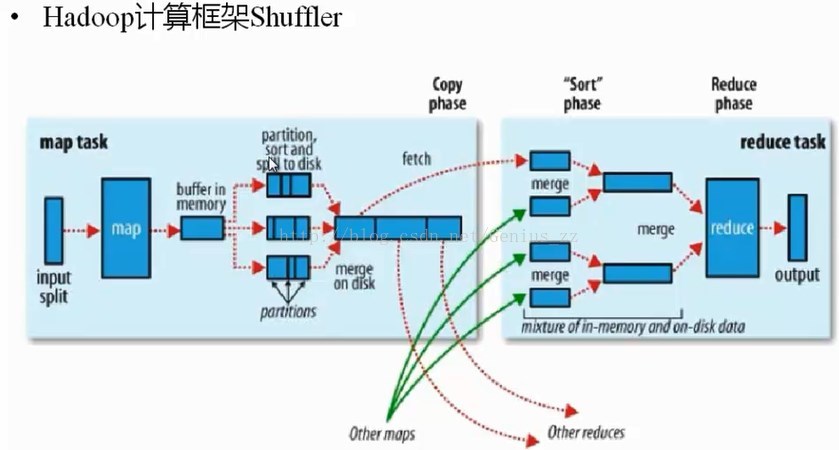
Hadoop计算框架Shuffle
处于map和reduce阶段之间。
其中,最重要的是Shuffle阶段,这个阶段也是最难理解的阶段,以下是官方对Shuffle过程的描述。
针对官方文档,更加细致的map段的描述如下:
(1)input
map task执行的时候,数据的来源是HDFS上的block,在MapReduce概念中,读取的是split,split和block是对应的。
(2)map阶段
经过自定义的map函数的处理后,结果将以key/value的形式输出,但是这些结果要送到以后的哪一个reduce去执行,需要partition来决定。
(3)partition
根据key或者value的值,以及reduce的数量,来决定当前的这对输出数据要交到那个reduce task去处理
默认方法: 对key hash以后再以reduce的数量取模。
也可以由程序员自定义Partition函数
partition只是对数据以后要被送到那个reduce去处理做了一个标注,而不是立马把数据进行分区。
数据倾斜和负载均衡:默认的partition是可能产生数据倾斜和负载均衡,如果产生数据倾斜,就需要重新定义partition的分区规则,就可以避免数据倾斜问题。
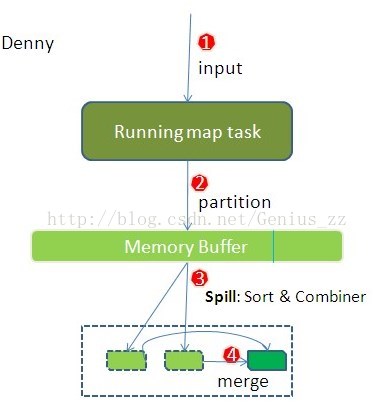
内存缓冲区的概念
每个map任务都有一个内存缓冲区,用于存储任务的输出,默认缓冲区的大小是100M,这个值是可以通过io.sort.mb来调整。由于缓冲区的空间大小有限,所以,当map task的输出结果很多的时候,内存缓冲区就装不下这么多的数据,也就需要将数据写到磁盘去。因此需要一个阈值(io.sort.spill.percent,默认是80%),当内存达到阈值以后,就会有一个单独的后台线程,负责将内存中的数据写到磁盘,这个过程叫做溢写,由于是由单独的线程来负责溢写,所以,溢写过程不会影响map结果的输出,但是,如果此期间缓冲区被写满,map就会阻塞知道写磁盘过程完成。
这里,就有两个过程,一个写内存的过程,另外一个是写磁盘的过程。
(4)sort
这里sort是按照字典顺序进行排序,而不是按照数值大小进行排序,举个栗子,就是说,a一定排在d的后面。
(5)combine
将排好序的数据,按照键相同的合并在一起的规则,进行值的合并。比如两个<aaa,1>合并以后,就编程了一个<aaa,2>。
map的输出结果在经过partition阶段的处理后,明确了要发给哪个reduce去做处理,当写入了内存后,需要将所有的键值对按照key进行sort,在sort的基础上,再对结果进行combine,最后,在写到磁盘文件上去。所以,在磁盘上的数据,是已经分好区的,并且已经排好序的。
溢写磁盘需要注意的地方:如果map的输出结果很大,有多次溢写发生的话,磁盘上就会存在多个溢写文件(每次溢写都会产生一个溢写文件),在map task真正的完成是时,会将所有的溢写文件都Merge到一个溢写文件中,这个过程就叫Merge。比如,从一个map读取过来的是<aaa, 5>,另外一个map读取的
是<aaa,8>。相同的key,就会merge成一个group{aaa,[5, 8...]},这个数组中的不同的值,就是从不同的溢写文件中读取过来的,然后把这些值加起来。
为什么要设置内存缓冲区?
批量收集map的结果,减少磁盘IO次数,提高效率。
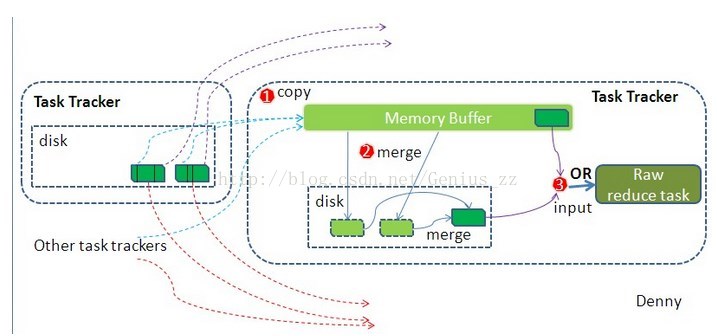
磁盘文件要写到哪里?
写磁盘将按照轮询方式写到mapred.local.dir属性指定的作业特定子目录的目录中。也就是存放在TaskTracker够得着的某个本地目录,每一个reduce task不断通过RPC从JobTracker中获取map task是否完成的信息,如果reduce task得到通知,获知某台TaskTracker上的map task完成,Shuffle的后半段就开始了。
所有的合并究竟是为了什么?
因为map节点和reduce节点之间的数据拷贝是通过网络进行拷贝的,数据量越小,拷贝的越快,相应的处理也就越快,那个,合并的目的就是减少map的输出数据量,是网络拷贝尽可能快。
需要特殊说明的是,以上的步骤,都是在本地机器上完成,并不需要通过网络进行数据的传输。
reduce段的Shuffle细节:
(1)
copy阶段
reduce进程启动一些数据的copy线程,这个线程叫做fetcher线程,通过http方式请求map task所在的TaskTracker,来获取map task的输出数据。
reduce拷贝数据,不是进行随意的拷贝,之前的partition,已经将数据分好区,reduce只是拷贝各个map上分割给自己的那一部分数据,拷贝到本地后,从每一个map上拷贝过来的数据都是一个小文件,也是需要对这些小文件进行合并的。合并以后,输出到reduce进行处理。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









