







一、Hadoop的三大发行版本
* Apache
在企业实际应用中,并不多,是最原始(最基础版本)。
* Cloudera impala
flume,hue,
1. Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要包括支持、咨询服务、培训。
2. 之后Hadoop的创始人Doug Cutting也加盟Cloudera公司,Cloudera产品主要有CDH,Cloudera Manager,Cloudera Support
3. CDH 4.x 是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性、安全性、稳定性上有所增强
4. Cloudera Manager 集群的软件分发以及管理监控平台
* Hortonworks
HDP(Hortonworks Data Platform)
二、Hive架构(面试时做好边讲边画)
背景:
*MapReduce成本比较高
*传统DBA要进行数据分析
Hive特点
*FaceBook开源
*本质是:将HQL转化为MapReduce程序
*使用HQL作为查询接口
*MapReduce计算(Map task,Reduce task),离线并行计算框架
*运行YARN平台(Resourcemanage,nodemanage)
*数据是存储在HDFS上的
*Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射成一张表,不是一个数据库。数据库是直接可以介入业务的,而数据仓库是一个逻辑表。
hive是用MapReduce封装可用于承载数据仓库的产品,自带了很多MapReduce程序,具有以下优势:
*用于解决海量结构化日志文件的统计工作,把它映射为一张表,就可以用SQL语句进行分析查询
*支持自定义UDF函数,比较灵活
*适合批量离线处理数据,不适合实时性要求比较高的场景
*主要用于数据分析
具体的Hive架构图见下表:
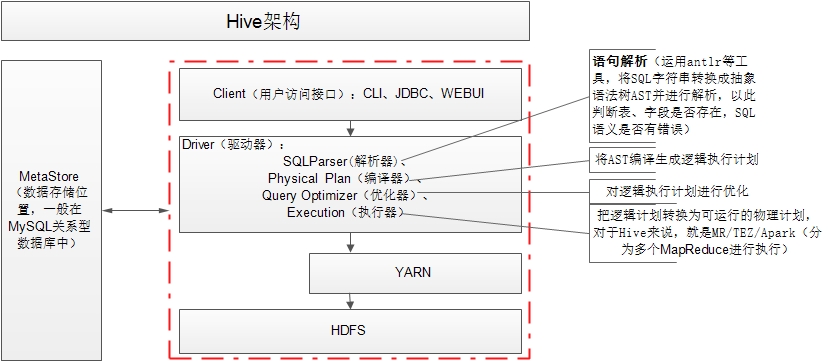
*用户接口:Client
CLI(hive shell)、JDBC/ODBC(java访问hive),WEBUI(浏览器访问hive)
*元数据:Metastore
元数据包括:表名、表所属的数据库、表的拥有者、列、分区字段、表的类型、表的数据所在目录
默认存储在自带的Derby数据库中,推荐使用MySQL存储Metastore;
*Hadoop
使用HDFS进行存储,使用MapReduce进行计算
*驱动器:Driver
包括:解析器、编译器、优化器、执行器。
解析器:语句解析(运用antlr等工具,将SQL字符串转换成抽象语法树AST并进行解析,以此判断表、字段是否存在,SQL语义是否有错误)
编译器:将AST编译生成逻辑执行计划
优化器:对逻辑执行计划进行优化
执行器:把逻辑计划转换为可运行的物理计划,对于Hive来说,就是MR/TEZ/Apark
三、hive的配置
1)启动HDFS和yarn
$sbin/start-dfs.sh
$sbin/start-yarn.sh
$sbin/hadoop-daemon.sh stop secondarynamenode
$sbin/mr-jobhistory-daemon.sh start historyserver(启动历史服务器)
2)解压hive的jar包并重命名
$tar -zxvf apache-hive-0.13.1-bin.tar.gz
$mv apache-hive-0.13.1-bin/ hive-0.13.1
3)配置
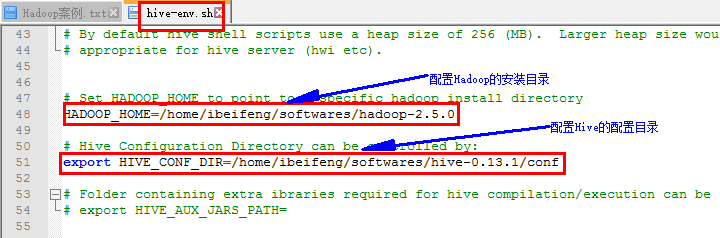
*配置hive-env.sh(重命名之后)
配置Hadoop的安装目录: HADOOP_HOME=/home/ibeifeng/softwares/hadoop-2.5.0
配置Hive的配置目录:
export HIVE_CONF_DIR=/home/ibeifeng/softwares/hive-0.13.1/conf
*在HDFS上创建目录 /tmp 和/user/hive/warehouse
查看HDFS上的目录
$bin/hdfs dfs -ls -R /
创建目录:
$ bin/hdfs dfs -mkdir -p /user/hive/warehouse
给所建立的目录赋予权限:
$bin/hdfs dfs -chmod g+w,g+x /tmp
$ bin/hdfs dfs -chmod g+w,g+x /user/hive/warehouse


4)Hive的基本命令
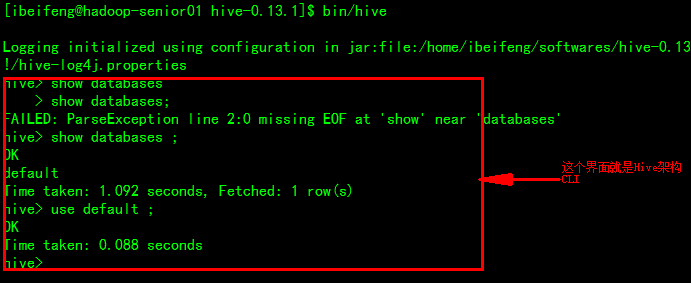
打开Hive的命令行:$bin/hive
显示有多少数据库:show databases ;(分号前要加空格)
使用默认数据库:use default ;
显示有多少张表: show tables ;
创建表:create table student(id int,name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’ ;用于字段与字段之间的限制
导入数据:load data local inpath ‘/home/ibeifeng/softwares/hadoop-2.5.0/datas/student.txt’ into table student ;
查询信息: select * from student ;
查询某个字段: select id from student ;(在MapReduce上运行)
5)安装MYSQL:
*解压zip安装包:
$unzip mysql-libs.zip
*查看系统有没有安装MySQL
$sudo rpm -qa|grep mysql
*卸载已经安装过的MYSQL
$sudo rpm -e –nodeps mysql-libs-5.1.66-2.el6_3.x86_64
*赋予mysql-libs文件夹下所有文件执行权限
$sudo chmod u+x ./*

*安装MYSQL
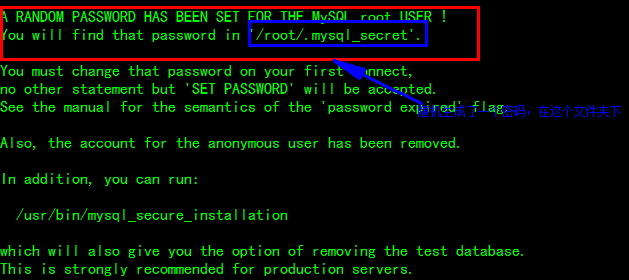
$ sudo rpm -ivh MySQL-server-5.6.24-1.el6.x86_64.rpm(会随机生成密码)
$ sudo cat /root/.mysql_secret (查看密码)
*启动MySQL
$ sudo service mysql start
*安装客户端
$sudo rpm -ivh MySQL-client-5.6.24-1.el6.x86_64.rpm
*进入MySQL,并设置密码
$ sudo mysql -uroot -ptRGlB2BC4jFSXH2o
mysql> SET PASSWORD=PASSWORD(‘123456’);在MySQL下设置密码
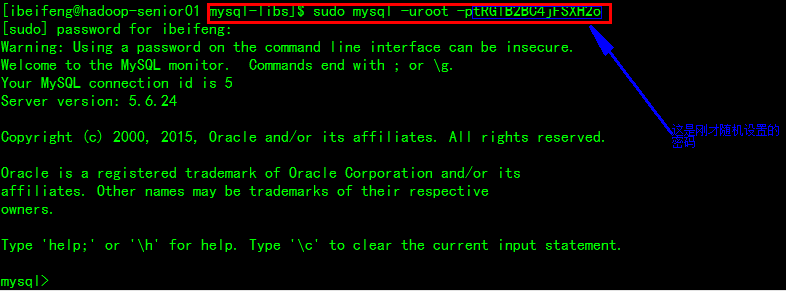
*登录并修改链接配置:$ mysql -uroot -p123456
进入mysql数据库的user表,删除修改用户

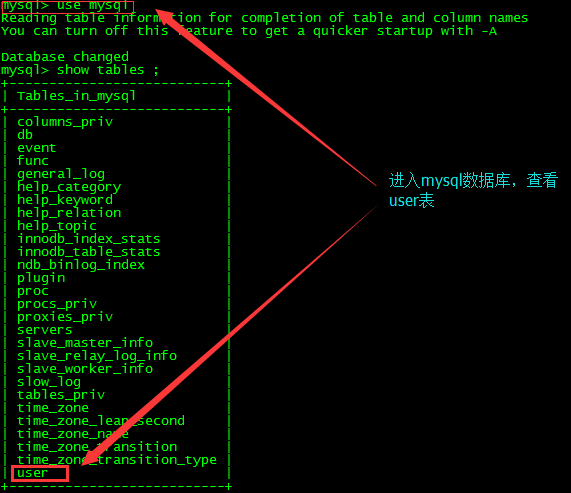
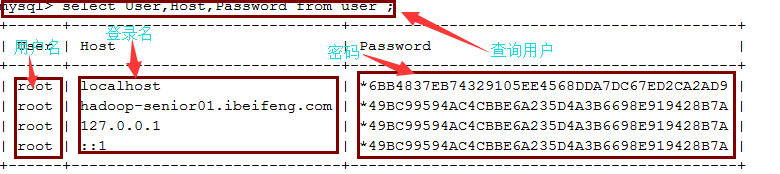
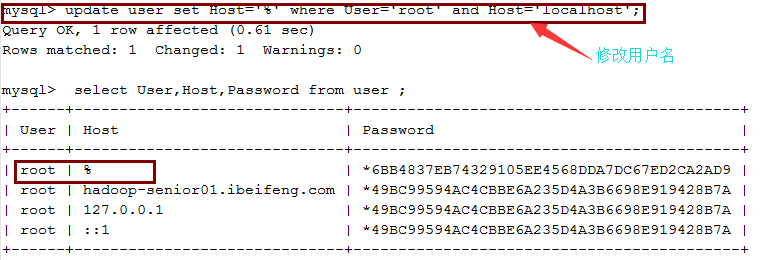
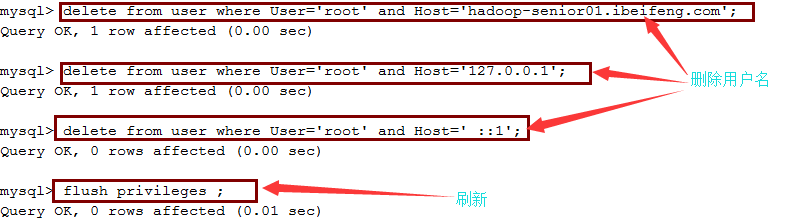
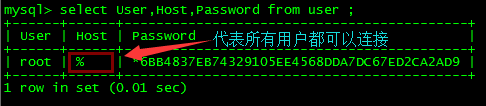
*安装驱动
解压tar包,并将其中的驱动包考到/home/ibeifeng/softwares/hive-0.13.1/lib文件下
$ cp mysql-connector-java-5.1.27-bin.jar /home/ibeifeng/softwares/hive-0.13.1/lib
*提示:ERROR 1044 (42000): Access denied for user ”@’localhost’ to database ‘mysql’。
*方法一:
1.关闭mysql
# service mysqld stop
2.屏蔽权限
# mysqld_safe –skip-grant-table
屏幕出现: Starting demo from …..
3.新开起一个终端输入
# mysql -u root mysql
mysql> UPDATE user SET Password=PASSWORD(‘newpassword’) where USER=’root’;
mysql> FLUSH PRIVILEGES;//记得要这句话,否则如果关闭先前的终端,又会出现原来的错误
mysql> \q
*方法二:
1.关闭mysql
# service mysqld stop
2.屏蔽权限
# mysqld_safe –skip-grant-table
屏幕出现: Starting demo from …..
3.新开起一个终端输入
# mysql -u root mysql
mysql> delete from user where USER=”;
mysql> FLUSH PRIVILEGES;//记得要这句话,否则如果关闭先前的终端,又会出现原来的错误
mysql> \q
6)配置Hive(配置网址: https://cwiki.apache.org/confluence/display/Hive/AdminManual+MetastoreAdmin)
*拷贝/home/ibeifeng/softwares/hive-0.13.1/conf文件下配置文件hive-default.xml.template,并修改名称为hive-site.xml
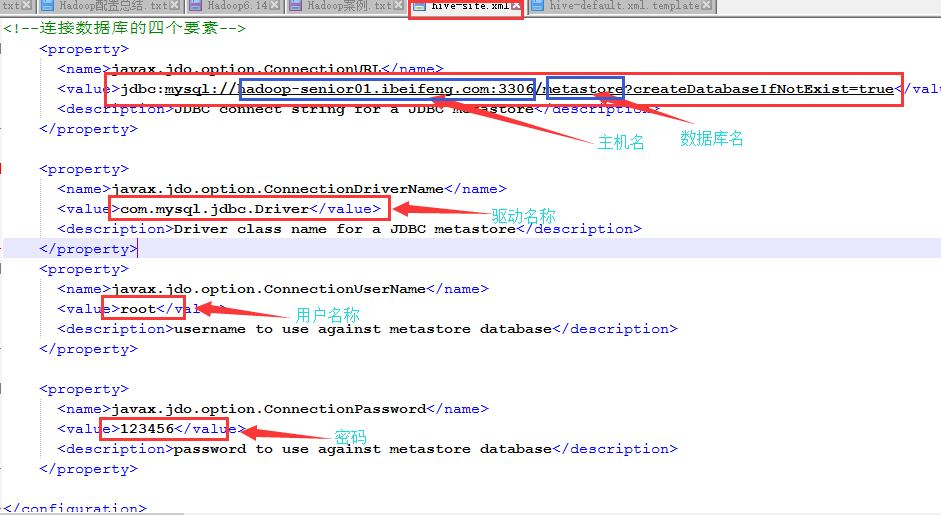
**查询时显示数据库名称和字段名
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>Whether to print the names of the columns in query output.</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>Whether to include the current database in the Hive prompt.</description>
</property>
*修改hive-log4j.properties.template文件名为 hive-log4j.properties(以便查询日志)
配置日志的路径:/home/ibeifeng/softwares/hive-0.13.1/logs
7)启动Hive:bin/hive(启动之前必须先启动Hadoop伪分布式服务器)
注意:配置的hive metastore
mysql
与我们hive安装在同一台机器上

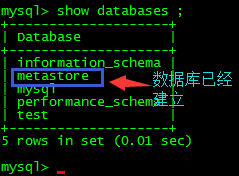
8)Hive基本操作
显示数据库:hive> show databases ;
创建数据库:hive> create database db_hive ;
进入数据库:hive> use db_hive ;
创建一张表:hive> create table student(id int,name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’ ;
显示表:hive> show tables ;
显示表的结构:hive> desc student ;
显示具体表的结构:hive> desc extended student ;
显示具体表的结构(格式化之后):hive> desc formatted student ;
上传当地的数据:hive> load data local inpath ‘/home/ibeifeng/softwares/hadoop-2.5.0/datas/student.txt’ into table db_hive.student ;
查询数据:hive> select count(*) from student ;(在MapReduce上运行)
显示hive的自带函数:hive> show functions ;
显示函数如何使用:desc function extended upper ;
例:hive> select id,upper(‘name’) uname from db_hive.student ;
显示当前用户的设置信息:set ;
删除dfs目录:hive (db_hive)> dfs -rm -R /user/hive/warehouse/bf_log ;
四、Hive常用属性配置
*Hive数据仓库位置的配置
default
/user/hive/warehouse
注意:
*在仓库目录下,没有对默认的数据库default创建文件夹
*如果某张表属于default数据库,直接在数据仓库目录下创建一个文件夹
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
同组用户给一个执行的权限(https://cwiki.apache.org/confluence/display/Hive/GettingStarted)
$ $HADOOP_HOME/bin/hadoop fs -mkdir /tmp
$ $HADOOP_HOME/bin/hadoop fs -mkdir /user/hive/warehouse
$ $HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp
$ $HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse
*hive运行日志信息位置
hive-log4j.properties
hive.log.dir=/home/ibeifeng/softwares/hive-0.13.1/logs
hive.log.file=hive.log
*指定hive运行时显示的log日志级别
hive-log4j.properties
hive.root.logger=INFO,DRFA
*在cli命令行上显示当前数据库,以及查询表的行头信息
hive-site.xml
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>Whether to print the names of the columns in query output.</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>Whether to include the current database in the Hive prompt.</description>
</property>
*在启动hive时设置配置属性信息
$bin/hive --hiveconf <property=value>
*查看当前的所有配置信息
hive (default)> set ;
查看当前属性的值:hive (default)> set system:user.name ;
设置当前属性的值:hive (default)> set system:user.name=*** ;
(此种方式设置属性的值仅仅在当前session会话中有效)















 1954
1954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









