






目录
前言
化妆品作为最基础的颜值消费品之一,正处于一个大规模普及使用的时代。化妆品是“颜值经济”的六大领域之一,其他还包括健身、医疗美容、美颜摄影、美颜饮食、服装及配饰。据微热点统计,2021年8月,“化妆”以96.11热度指数位于第二位,仅次于“健身”且与其热度指数相差较小。
在化妆品细分产品分类中(主要分为护肤类化妆品和彩妆类化妆品),护肤品是化妆品中的肤用化妆品子类,主要具有清洁皮肤及补充皮肤养分等功能,如洗面奶、面霜、面膜等。护肤品作为化妆品行业最大的一个子行业,更受舆论关注。在统计时间段内,护肤品的全网信息量为1851.4万,位于化妆品子行业首位;彩妆紧随其后,全网信息量为1483.1万;香氛和美发护发分别以570.5万和105.9万信息量位于第三、第四。
因此,本文基于上述市场现状,聚焦于我国护肤品市场的销售情况,本文利用网络爬虫的技术,爬取了淘宝网中,2021年双十二期间对于关键词“护肤品”的4100条产品数据及其销量,旨在分析出影响产品销量的因素以及建立预测销量模型,方便商家与消费者更好地做出决策。
下面不多废话,直接上代码
一、数据说明
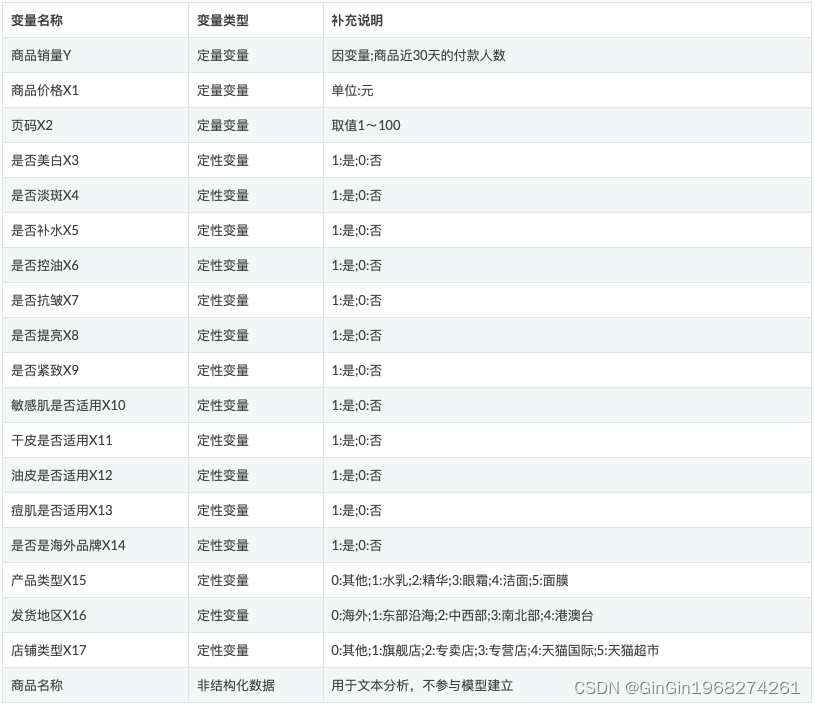
二、描述统计
1.词云图
首先,本文对4095个样本对应的产品名称进行文本合并,经过分词和停用词处理后,生成产品信息语料库,并根据语料库中各词语的词频,取出词频最高的150个词绘制出词云图,如下图所示。由词云图可见商品名称中补水、保湿、套装、护肤品以及正品出现频率较高。并且可见滋润、修复、紧致、控油、美白等功效字样出现频率也较高。
##加载程序包
library(jiebaR) #用于分词
library(wordcloud2) #用于绘制词云
#读取数据
data=read.csv("护肤品.csv",header = TRUE,stringsAsFactors = F)
data=na.omit(data)
####前期处理:选择分词引擎,读入自定义词典
#初始化分词工具
seg=worker(bylines = T)
#数据文本化进行分词
data$name=as.character(data$商品名称)
name_seg=segment(data$name,seg)
########画词云图
#利用词云图展现不同级别分类体系下商品名称分词结果(生鲜为例)
#建立分词后词频数据库
name_seg_df=data.frame(table(unlist(name_seg)))
#对词频进行降序处理,找到高频词
name_df=name_seg_df[order(name_seg_df$Freq,decreasing = T),]
#对前150个词构建词云图
wordcloud2(name_df[1:150,],size=1,shape = 'star')
2.因变量
本文采用绘制概率直方图及概率密度曲线的方式对商品销量进行分析,可以由图中看出销量分布极不均匀,呈现右偏分布,大部分集中在5000件以下,且最大值为100000件。因此为了解决数据偏态问题,本文采取对因变量取对数的方法。
library(ggplot2)
binsize <- diff(range((data$商品销量)))/100
ggplot(data,aes(x=商品销量)) +
geom_histogram(aes(y=..density..),binwidth = binsize, fill="steelblue")+#绘制直方图
geom_density(colour="blue",size=1)+ #正态分布拟合曲线
theme(text=element_text(family="Songti SC"))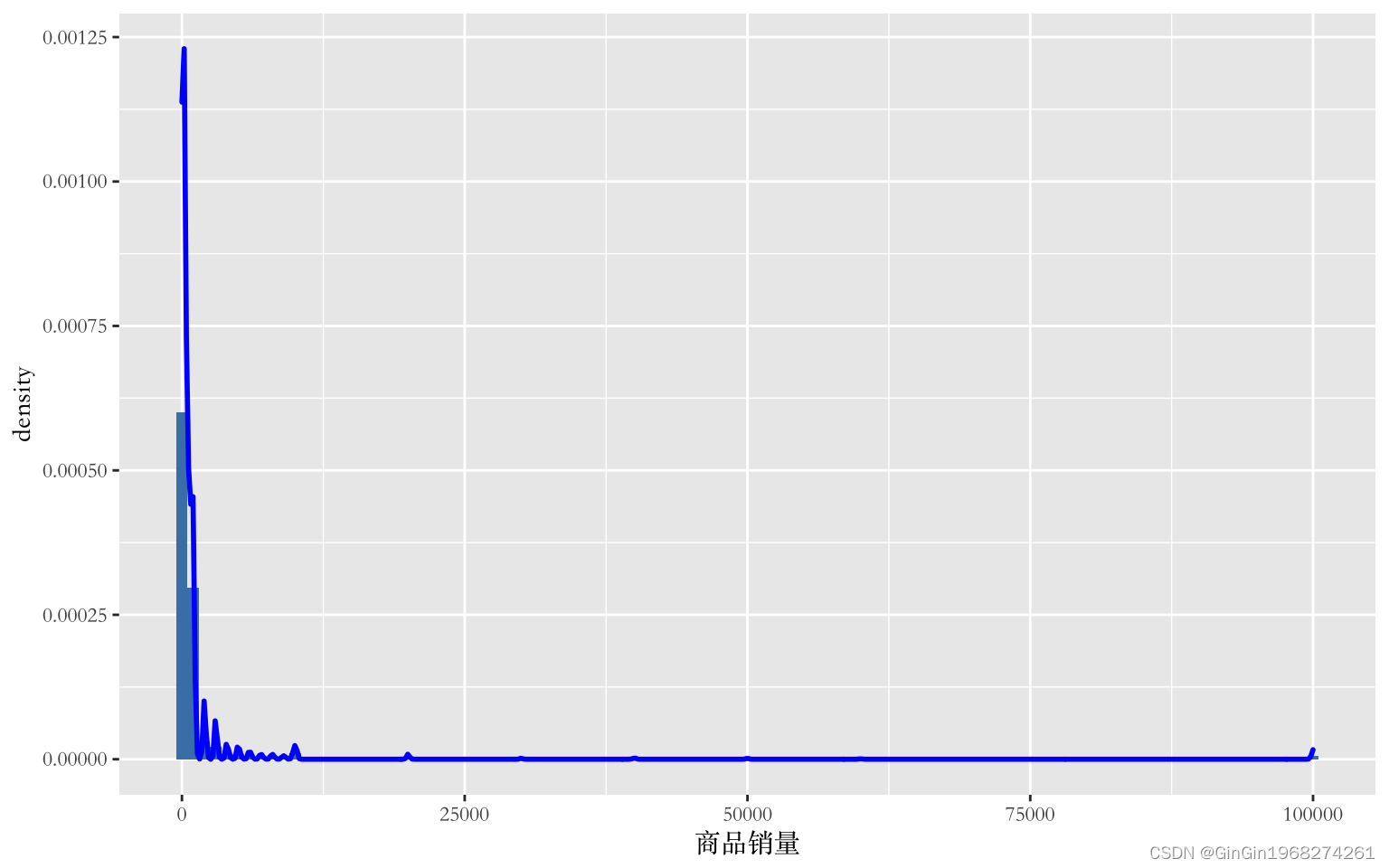
3.对数因变量
为解决数据偏态问题,对商品销量取对数,创建一个新因变量:对数销量。并且绘制对数销量的概率直方图及概率密度曲线,结果如下图所示。由下图可以看出对数销量数据分布较均匀,成功解决商品销量的偏态问题。因此为提高模型的精确率和稳定性,最后选择以对数销量为因变量进行建模。
data$对数销量=log(data$商品销量)
binsize <- diff(range((data$对数销量)))/100
ggplot(data,aes(x=对数销量)) +
geom_histogram(aes(y=..density..),binwidth = binsize, fill="steelblue")+#绘制直方图
geom_density(colour="blue",size=1)+ #正态分布拟合曲线
theme(text=element_text(family="Songti SC"))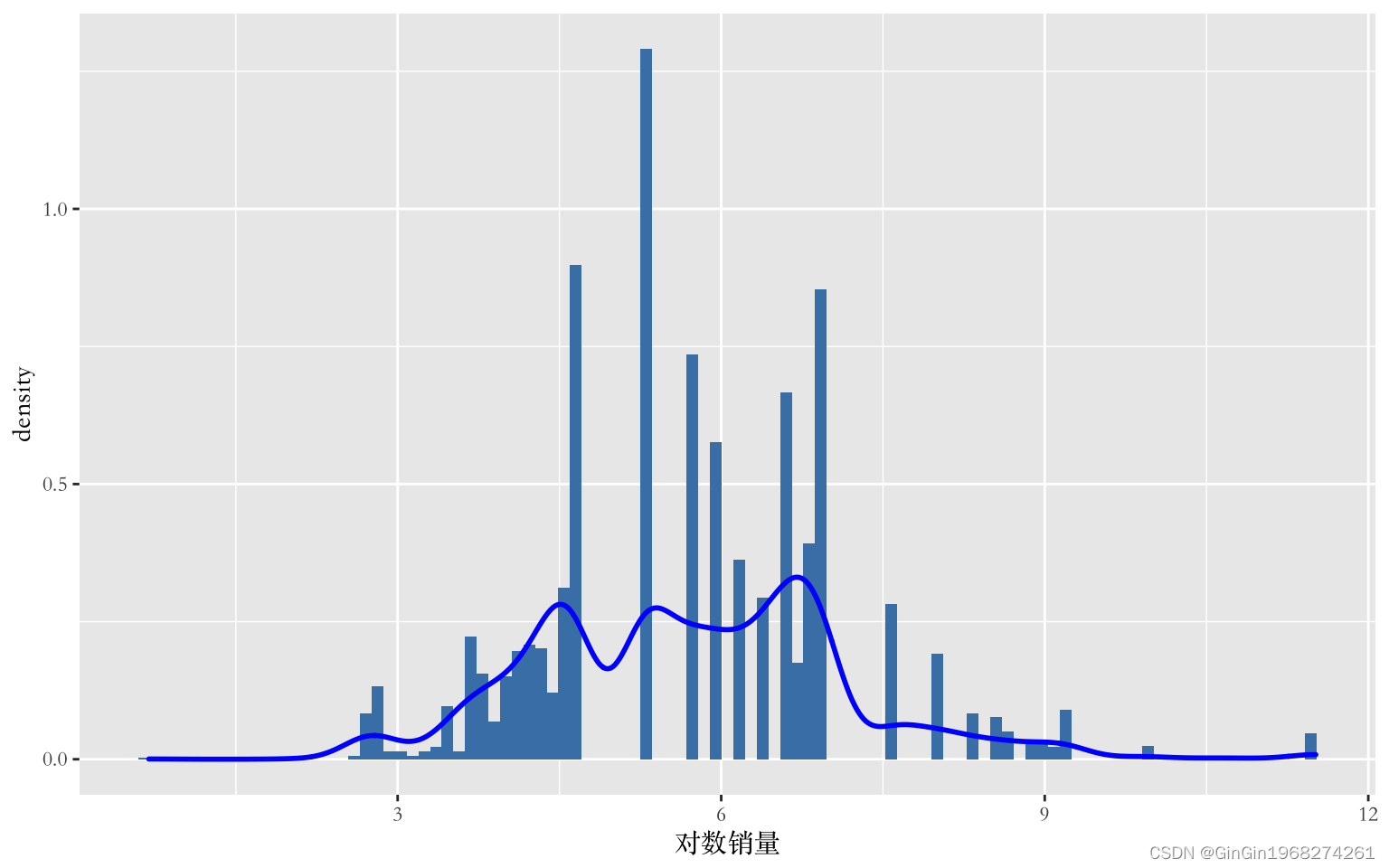
3.自变量
1.多分类变量
自变量就po一部分吧,太多了。
library(ggridges)
data$发货地区=as.factor(data$发货地区)
ggplot(data,
aes(x = 对数销量,
y = 发货地区,
fill=发货地区)) +
geom_density_ridges() +
theme_ridges() +
theme(legend.position = "none",text=element_text(family="Songti SC"))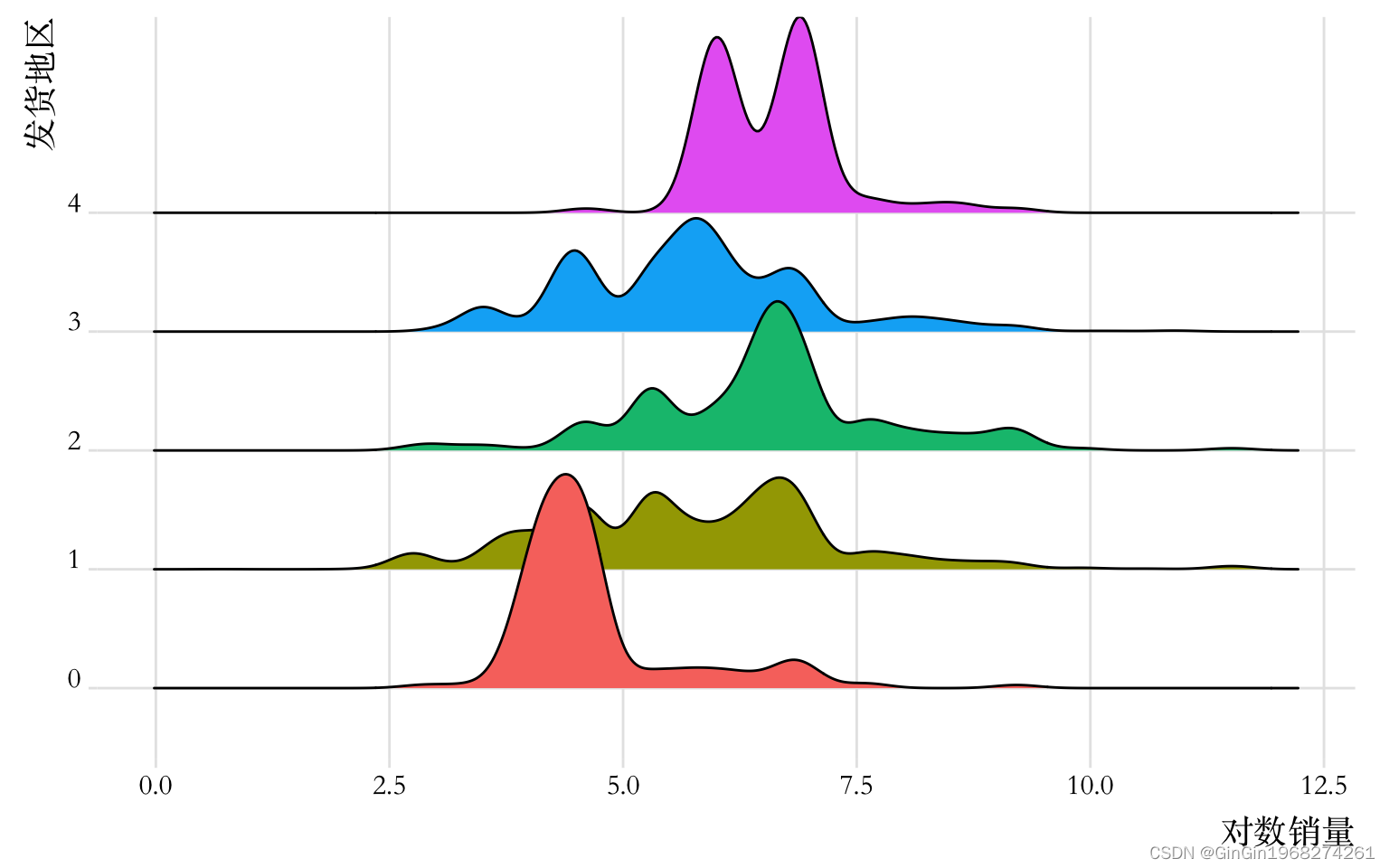
data$店铺类型=as.factor(data$店铺类型)
ggplot(data,
aes(x = 店铺类型,
y = 对数销量)) +
geom_boxplot(fill=brewer.pal(6, "Blues")) +
theme(text=element_text(family="Songti SC"))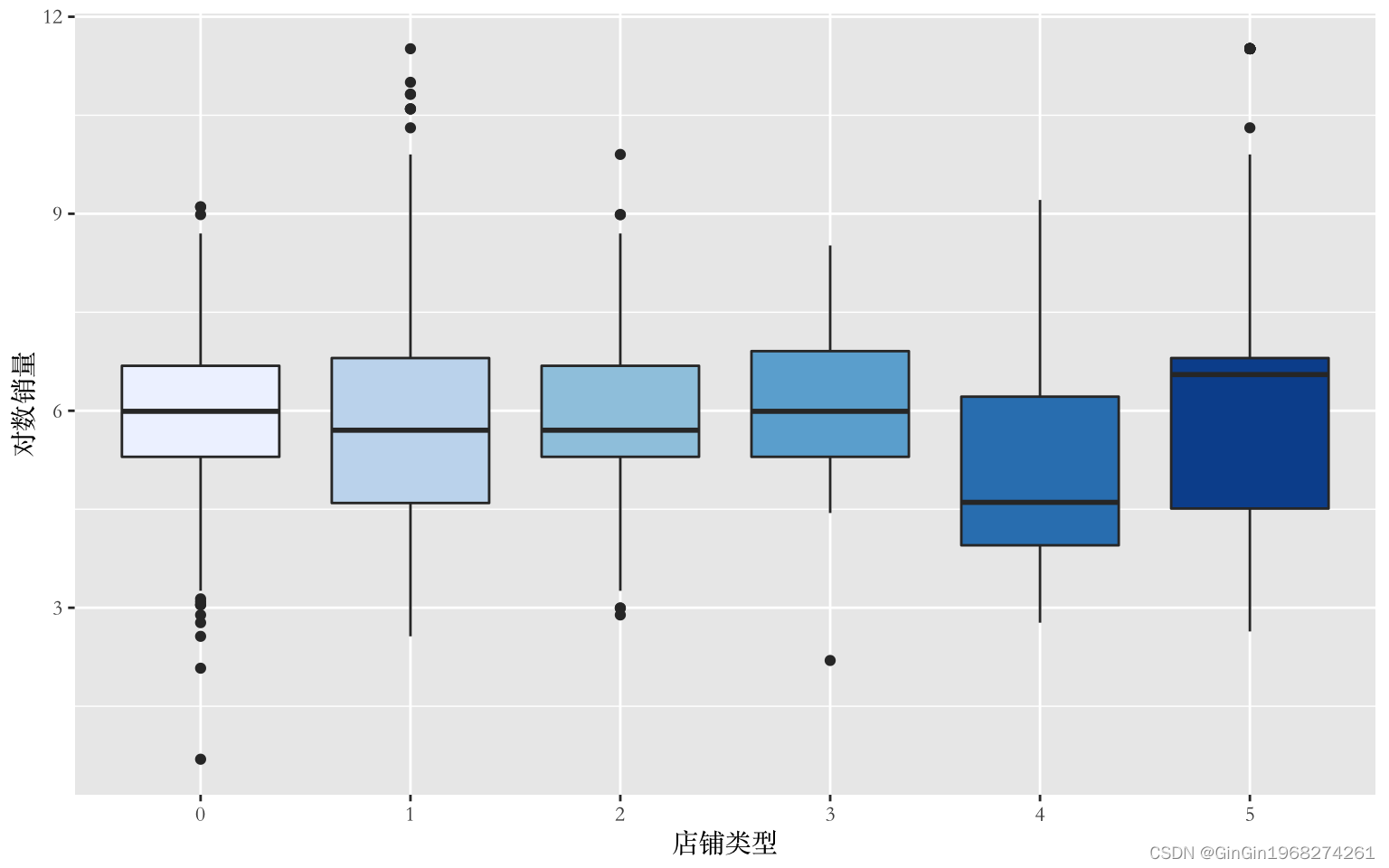
三、建模分析
1.决策树
通过下图可得到该决策树具有14个决策节点和15个叶节点。训练集的样本按照从根结点到叶节点的顺序,根据经过节点的决策条件,分配到符合条件的下一节点,最终落入其预测叶节点,样本的预测值即为该叶节点中所有训练样本的均值。越靠近根节点的变量对模型预测影响越大,节点出现的次数越多越重要。而商品价格和页码出现次数最多,因此认为这两个变量对决策有重要影响。
#回归树
par(family="Songti SC")
library(rattle)
library(rpart)
tree.sale=rpart(对数销量~.,data=mydata,subset = train)
fancyRpartPlot(tree.sale)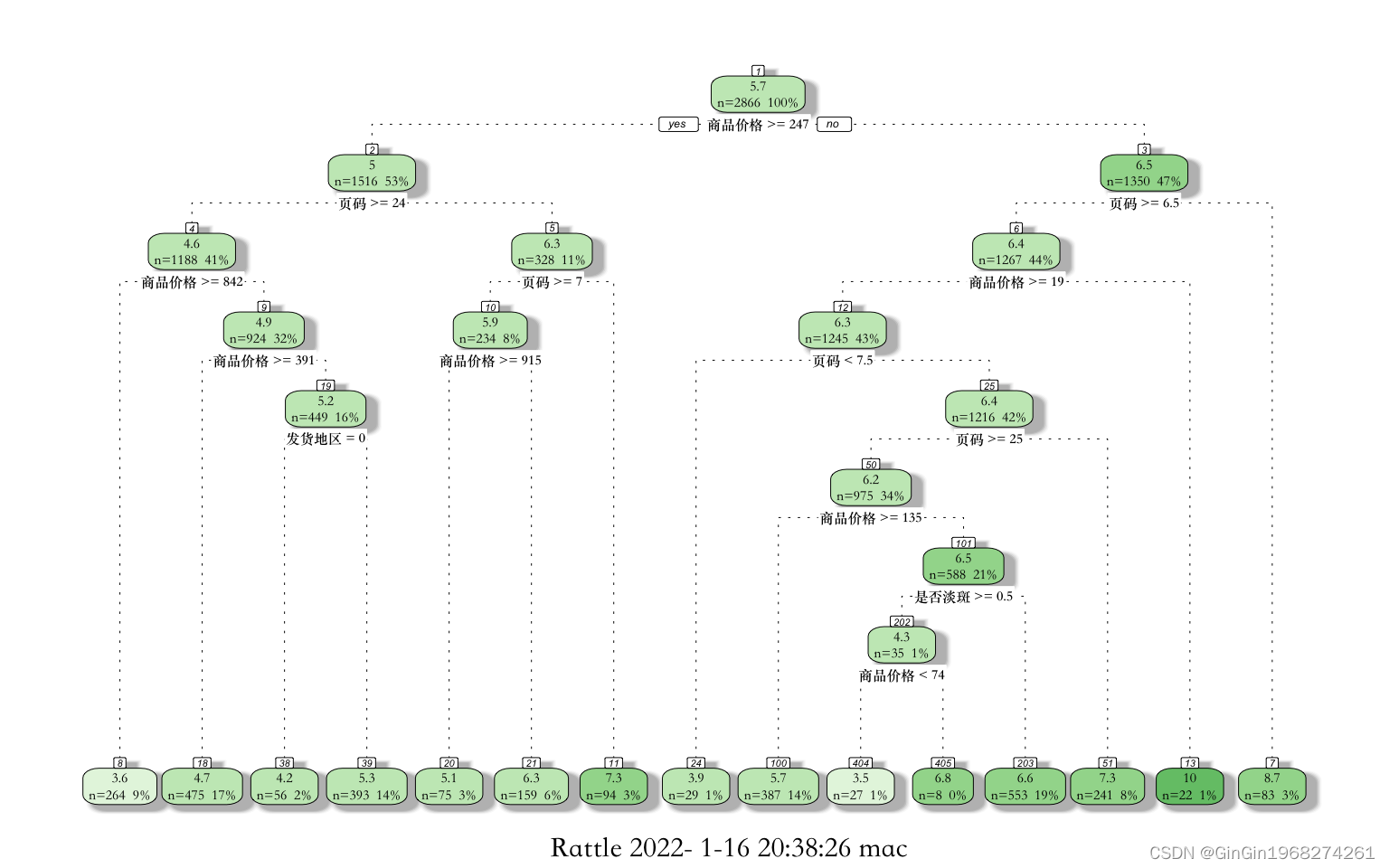
2.随机森林
对于因变量对数销量,本文建立包含500棵回归树的随机森林模型。由于模型由多棵形状差异巨大的决策树构成,可视化、可解读性都很差,因此通过对模型中解释变量的重要程度进行可视化分析来体现整体模型情况。
依变量重要性可以看出,商品价格是影响商品销量最重要的变量,用户对价格低的护肤品需求高,而页码是第二重要的变量,用户往往希望出现在较前位置搜索页的商品是热销的,也可能是商品因为被推到较前页才变得热销,两者相关性强。其余变量的重要程度差异不大,而重要性最小的变量是干皮是否适用,可见人们对干皮适用产品需求较低。
#随机森林
par(family="Songti SC")
library(randomForest)
rf.sale=randomForest(对数销量~.,data = mydata,subset = train,importance=T,mtry=6,ntree=500)
#绘制变量重要性图
varImpPlot(rf.sale,main="变量重要性")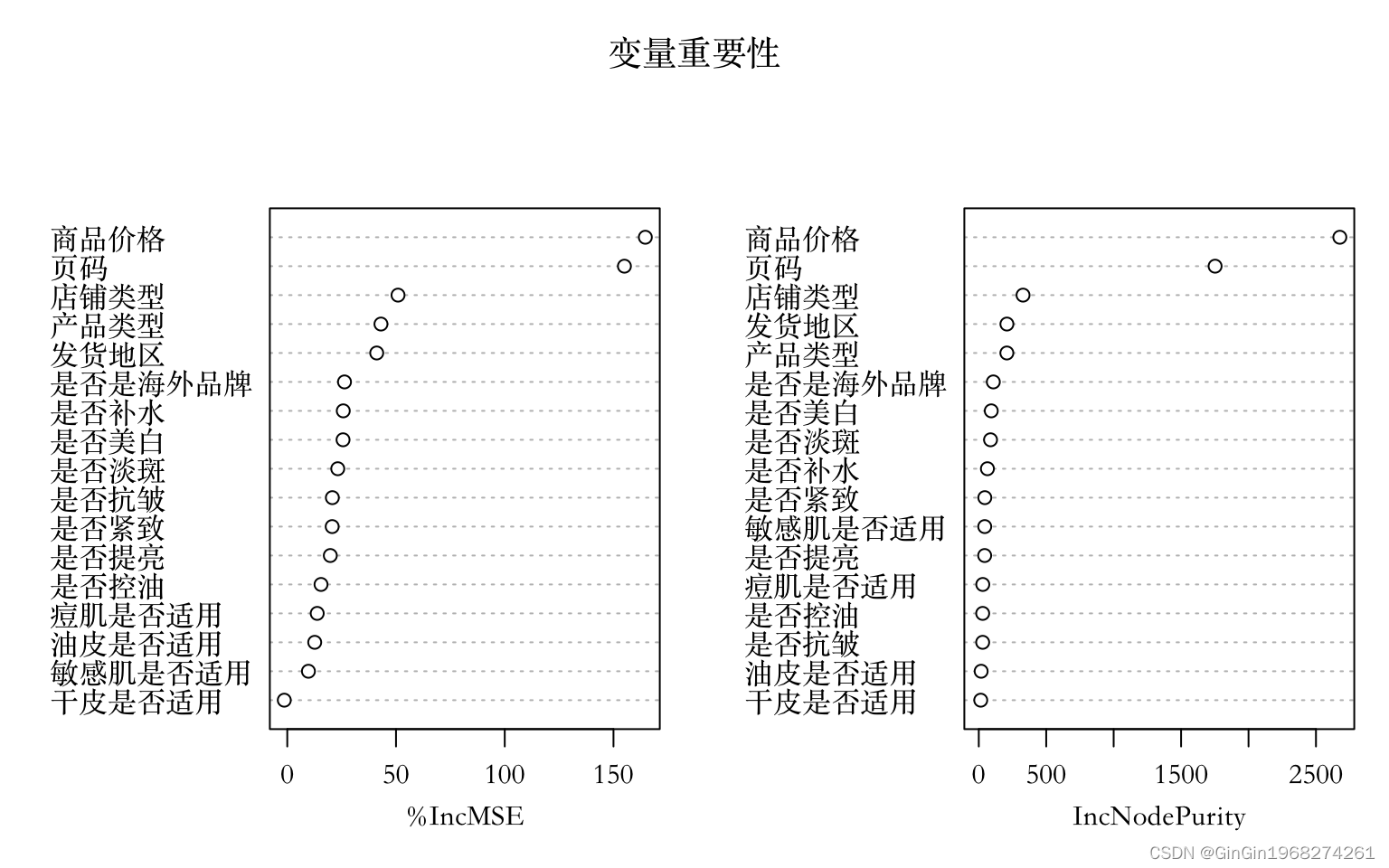
3.梯度提升树
本次模型采取以平方误差为损失函数,由于收缩参数控制提升学习的速率,降低收缩系数能改善结果,但需要更多的树,因此为了提高计算效率,本次设置的收缩参数是0.01,并拟合出20000棵提升树共同做出回归决策。
#梯度提升树
par(family="Songti SC")
library(gbm)
gbm.sale = gbm(对数销量~.,data=mydata[train,],shrinkage=0.01,
distribution='gaussian',cv.folds=3,
n.trees=20000,verbose=F)4.支持向量回归
#支持向量回归SVR
library(e1071)
svr.sale = svm(formula = 对数销量 ~ .,data = mydata,subset=train,type = 'eps-regression',kernel = 'radial')
summary(svr.sale)
四、结论
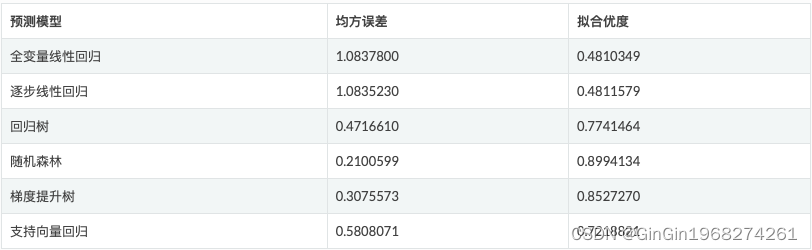
本文对于模型评价预测能力的指标有均方误差以及拟合优度,因此整合上述6个预测模型在测试集上的预测均方误差,可以得到结果如下表所示。因此在6个模型中,均方误差最低及拟合优度最高的模型是随机森林,其次是梯度提升树,模型预测能力最差的是全变量线性回归。

















 2465
2465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









