







这篇是作为我的笔记,所以写的可能不易大家阅读。
这是我理解的Stacking方法
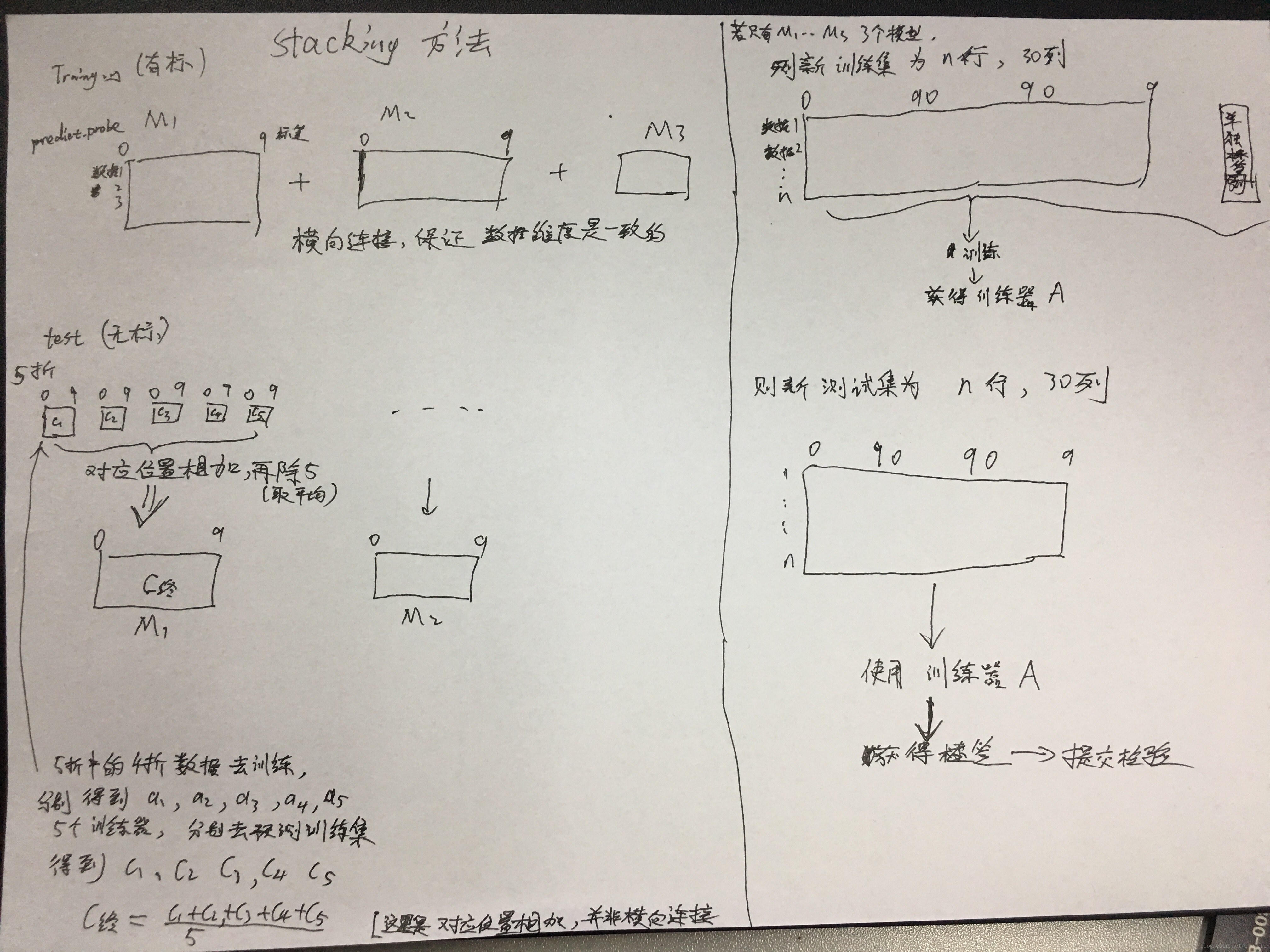
结合下面这张图一起来看
看懂这两张图,stacking就没啥问题了。
Training Data 是一个数据集分成5份(k份),拿其中4份(k-1份)训练Medel1,然后使用Model1预测剩下的1份,这样训练model1 5遍(k遍),可以组成一个包含所有样本的Prediction,这些作为新的训练集。
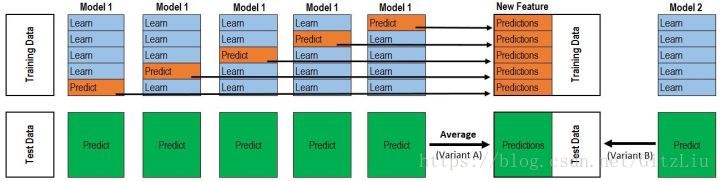
感觉正常情况下,stacking方法应该是很有效。
注意几点:
使用的是 predict_probe() 方法,而非 predict() 方法,因此,若model没有 predict_probe() 方法,则无法使用stacking进行模型融合。
在此,特别感谢柏宇同学的细心指导,让我对stacking有了深入的理解!
文献参考:
1、https://www.cnblogs.com/jiaxin359/p/8559029.html 这篇写的很不错,里面的图,非常有帮助。
2、http://blog.kaggle.com/2016/12/27/a-kagglers-guide-to-model-stacking-in-practice/
在titanic的比赛中,我在final_version 版本基础上,又尝试了下stacking的方法(参考其他的stacking方法)
这里我们使用了两层的模型融合,Level 1使用了:RandomForest、AdaBoost、ExtraTrees、GBDT、DecisionTree、KNN、SVM ,一共7个模型,Level 2使用了XGBoost使用第一层预测的结果作为特征对最终的结果进行预测。
Level 1:
Stacking框架是堆叠使用基础分类器的预测作为对二级模型的训练的输入。 然而,我们不能简单地在全部训练数据上训练基本模型,产生预测,输出用于第二层的训练。如果我们在Train Data上训练,然后在Train Data上预测,就会造成标签。为了避免标签,我们需要对每个基学习器使用K-fold,将K个模型对Valid Set的预测结果拼起来,作为下一层学习器的输入。
所以这里我们建立输出fold预测方法:
from sklearn.model_selection import KFold
# Some useful parameters which will come in handy later on
ntrain = X.shape[0] // X是处理好的 不带标签的 训练集样本;(as.matrix())
ntest = test.shape[0] # 处理好的训练集样本 (as.matrix())
SEED = 0 # for reproducibility
NFOLDS = 7 # set folds for out-of-fold prediction # 7 折
kf = KFold(n_splits = NFOLDS, random_state=SEED, shuffle=False)
def get_out_fold(clf, x_train, y_train, x_test):
oof_train = np.zeros((ntrain,))
oof_test = np.zeros((ntest,))
oof_test_skf = np.empty((NFOLDS, ntest))
for i, (train_index, test_index) in enumerate(kf.split(x_train)):
x_tr = x_train[train_index]
y_tr = y_train[train_index]
x_te = x_train[test_index]
clf.fit(x_tr, y_tr)
oof_train[test_index] = clf.predict(x_te)
oof_test_skf[i, :] = clf.predict(x_test)
oof_test[:] = oof_test_skf.mean(axis=0)
return oof_train.reshape(-1, 1), oof_test.reshape(-1, 1)
构建不同的基学习器,这里我们使用了RandomForest、AdaBoost、ExtraTrees、GBDT、DecisionTree、KNN、SVM 七个基学习器:(这里的模型可以使用如上面的GridSearch方法对模型的超参数进行搜索选择)
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.tree import DecisionTreeClassifier
rf = RandomForestClassifier(n_estimators=500, warm_start=True, max_features='sqrt',max_depth=6, min_samples_split=3, min_samples_leaf=2, n_jobs=-1, verbose=0)
ada = AdaBoostClassifier(n_estimators=500, learning_rate=0.1)
et = ExtraTreesClassifier(n_estimators=500, n_jobs=-1, max_depth=8, min_samples_leaf=2, verbose=0)
gb = GradientBoostingClassifier(n_estimators=500, learning_rate=0.008, min_samples_split=3, min_samples_leaf=2, max_depth=5, verbose=0)
dt = DecisionTreeClassifier(max_depth=8)
knn = KNeighborsClassifier(n_neighbors = 2)
svm = SVC(kernel='linear', C=0.025)
将pandas转换为arrays:
# Create Numpy arrays of train, test and target (Survived) dataframes to feed into our models
x_train = X # Creates an array of the train data X本身已经是array了
x_test = test # Creats an array of the test data test本身已经是array了
y_train = y y本身已经是array了 # y是前文处理好的 训练集的 标签列
# Create our OOF train and test predictions. These base results will be used as new features
rf_oof_train, rf_oof_test = get_out_fold(rf, x_train, y_train, x_test) # Random Forest
ada_oof_train, ada_oof_test = get_out_fold(ada, x_train, y_train, x_test) # AdaBoost
et_oof_train, et_oof_test = get_out_fold(et, x_train, y_train, x_test) # Extra Trees
gb_oof_train, gb_oof_test = get_out_fold(gb, x_train, y_train, x_test) # Gradient Boost
dt_oof_train, dt_oof_test = get_out_fold(dt, x_train, y_train, x_test) # Decision Tree
knn_oof_train, knn_oof_test = get_out_fold(knn, x_train, y_train, x_test) # KNeighbors
svm_oof_train, svm_oof_test = get_out_fold(svm, x_train, y_train, x_test) # Support Vector
print("Training is complete")
(4) 预测并生成提交文件
Level 2:
我们利用XGBoost,使用第一层预测的结果作为特征对最终的结果进行预测。
将第一层输出整理成新的 训练集 和测试集
x_train = np.concatenate((rf_oof_train, ada_oof_train, et_oof_train, gb_oof_train, dt_oof_train, knn_oof_train, svm_oof_train), axis=1)
x_test = np.concatenate((rf_oof_test, ada_oof_test, et_oof_test, gb_oof_test, dt_oof_test, knn_oof_test, svm_oof_test), axis=1)
使用xgboost 作为第二层训练器训练
from xgboost import XGBClassifier
gbm = XGBClassifier( n_estimators= 2000, max_depth= 4, min_child_weight= 2, gamma=0.9, subsample=0.8, colsample_bytree=0.8, objective= 'binary:logistic', nthread= -1, scale_pos_weight=1).fit(x_train, y_train)
predictions = gbm.predict(x_test)
将结果保存
StackingSubmission = pd.DataFrame({'PassengerId': data_test['PassengerId'].as_matrix(), 'Survived': predictions})
StackingSubmission.to_csv('StackingSubmission.csv',index=False,sep=',')
print ('done')
完成。














 5159
5159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









