






GRE、MGRE
VPN:
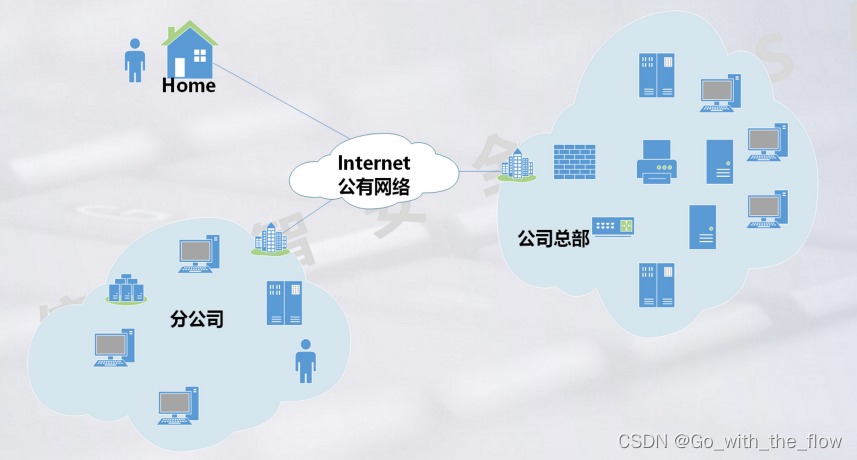
分公司、公司总部、home 都相当于私网,他们都需要连接到公网上
当其中两个私网中的私网IP想要访问对方时,比如所分公司的服务器想要访问公司总部的服务器时,这时候使用nat做端口映射就不行了。
两台服务器能供成功通讯的原因是:分公司的私网源IP和私网目标IP 转换为公网IP,发送到公有网络,然后再由其把公网源IP和公网目标IP转换为私网IP,发送到公司总部的服务器上。
因为nat技术只能把源IP从私网转换为公网或者把目标IP从公网转换为私网,nat技术不能同时转换源IP和目标IP,所以在此处想要让分公司的私网地址访问公司总部的私网地址,就不能直接使用nat技术。
但是可以直接把公司总部服务器的私网IP端口号做一个端口映射到公有网络中去,这样分公司去访问公网中的某一特定端口时,就可以访问到公司总部的服务器了。但是这种方法安全性不高,因为,当其他人也可以访问到公网中的这一端口号,这样就直接访问到了公司总部的服务器上了。
当分公司和公司总部或者个人和公司总部之间想要能够访问时,有两种方法:
1、建立物理专线
但是物理专线成本高,个人位置不确定
2、建立虚拟的专线
VPN—虚拟专用网—虚拟的专线
VPN—核心技术—是一种隧道技术—GRE
GRE :通用路由封装—创建一条点到点的隧道

隧道技术:在隧道的两端(实际是虚拟出来的一条链路的两个物理接口)通过封装以及解封装技术在公网上建立一条数据通道。使用这个数据通道进行数据传输。
注意:一旦隧道建立成功后,将会把两边的私网融合成一个私网。所以,在一开始分配私网网段的时候,就要考虑,避免网段冲突。(比如说一边的私网IP为192.168.1.X, 则另一边的私网IP就不能是192.168.1.X)
GRE的配置:
1、首先要创建隧道接口
[r1]int Tunnel 0/0/?
<0-511> Tunnel interface interface number
[r1]int Tunnel 0/0/0
[r1-Tunnel0/0/0]
2、隧道接口配置IP地址(两端配置的IP地址要在同一个网段)
[r1-Tunnel0/0/0]ip address 192.168.3.1 24 — 配置的要是个私网地址
3、定义封装的类型
[r1-Tunnel0/0/0]tunnel-protocol gre
4、定义封装内容
[r1-Tunnel0/0/0]source 12.0.0.1
[r1-Tunnel0/0/0]destination 23.0.0.2
5、将r1和r3上配置的私网路由写入到路由表中
这个私网路由是指192.168.1.1/24和192.168.2.1/24
[r1]ip route-static 192.168.2.0 24 192.168.3.2
[r3]ip route-static 192.168.1.0 24 192.168.3.1
下一跳是虚拟的隧道接口
[r1]ping -a 192.168.1.1 192.168.2.1
MGRE—多点通用路由封装技术
MGRE要解决的问题在于tunnel建立之后,源可以确定但是无法确认目标是谁,而且互联网是无法依靠组播和广播去寻找目标的,在解决这个问题的时候MGRE借鉴了ARP的方法,ARP就是拿广播一个个询问下一跳来找到到达目标的路径,并将ip和mac映射记录下来,参考ARP,MGRE技术使用了类似的技术,叫做NHRP(下一跳解析协议),来完成公网地址和tunnel的映射,通过逻辑的确定一个中心,让其他需要建立tunnel的设备加入到这个组当中,这样就可以减少建立tunnel的数量。
把私网的IP地址写在公网的路由表中
想要去往的私网IP-----隧道接口—实际的物理接口
NHRP协议—下一跳解析协议—自动学习隧道地址和物理地址(学习物理接口,从而学习到物理IP地址)的对应关系的一种方法。
原理:需要在私网中选出一个物理接口不会发生变化的作为AHRP的中心(NHS–下一跳服务器)。剩下的分支都需要知道中心的隧道IP和物理接口IP,他们需要将自己的物理接口IP和隧道IP发送给中心(如果分支的物理接口的IP地址发生变化,则需要立即将对应关系重新发送)。这样,NHS将会收集所有分支的地址映射关系。之后需要通讯时,查看对应关系,封装对应的接口IP地址即可。分支之间需要进行通讯,则先将数据发给中心,由中心进行转发。-----这种中心站点到分支站点的架构—HUB-SPOKE架构
因为MAGRE搭建的逻辑拓扑是一个多节点的网络,但是,发送信息时依然是点到点的发送,无法使用广播或者组播行为(因为R1如果想要和多个私网通讯,只能单独给每个私网发送一个数据包,不能通过泛洪的方式只发送一次。),所以,这样的网络我们可以称为NBMA网络。(他属于逻辑上搭建出的NBMA网络,真正意义上物理设备搭建出的NBMA网络是帧中继。)
MGRE的配置过程:
给中心站点进行配置(边界路由器出接口的公网IP地址不会发生变化的的作为NHS,即中心站点)
[r1]int t 0/0/0 —创建隧道接口
[r1-Tunnel0/0/0]ip address 192.168.5.1 24 —配置隧道IP地址
[r1-Tunnel0/0/0]tunnel-protocol gre p2mp —选择封装类型----选择MGRE(gre p2mp 即选择了gre封装)
[r1-Tunnel0/0/0]source 15.0.0.1 —定义源IP地址
[r1-Tunnel0/0/0]nhrp network-id 100—创建NHRP域(所有加入这个NHRP域的私网都会向中心站点汇报隧道地址和出接口物理地址的对应关系。)
NHRP 的network id具有全局意义,在整个网络中都遵循
给分支站点进行配置
[r2]int t 0/0/0
[r2-Tunnel0/0/0]ip address 192.168.5.2 24
[r2-Tunnel0/0/0]tunnel-protocol gre p2mp
[r2-Tunnel0/0/0]source GigabitEthernet 0/0/1—以接口作为封装源,以应对IP地址的变化
[r2-Tunnel0/0/0]nhrp network-id 100—加入NHRP域,必须是和中心站点创建相同的域
[r2-Tunnel0/0/0]nhrp entry 192.168.5.1 15.0.0.1 register—找中心站点进行注册(entry 加入 register 注册)
中心站点的 : 隧道地址 物理接口地址
display nhrp peer all —可以查看NHRP信息收集情况
但是此时R1的私网IP还是不能ping通其他R2、R3、R4上的私网IP地址,
解决方法:
方法一:写入静态路由信息(写的是私网的IP地址,下一跳是隧道接口)
当写入静态路由后再ping,就会执行MGRE的配置过程了。
方法二:是可以通过动态路由来获取(通过RIP协议)
[r1]rip 1
[r1-rip-1]version 2
[r1-rip-1]network 192.168.1.0 (只宣告内网网段,不宣告公网网段)
[r1-rip-1]network 192.168.5.0 (同时也要宣告隧道接口地址的网段,激活隧道接口)
[r2]rip 1
[r2-rip-1]version 2
[r2-rip-1]network 192.168.2.0
[r2-rip-1]network 192.168.5.0
[r3]rip 1
[r3-rip-1]version 2
[r3-rip-1]network 192.168.3.0
[r3-rip-1]network 192.168.5.0
[r4]rip 1
[r4-rip-1]version 2
[r4-rip-1]network 192.168.4.0
[r4-rip-1]network 192.168.5.0
通过RIP获取路由信息有以下问题:
1、中心站点可以收到分支的数据包,但是,分支不能收到中心站点的数据报—MGRE环境下不支持广播或者组播行为
解决方法:
在中心站点开启伪广播—分别给所有节点发送单播以达到广播的效果
[r1-Tunnel0/0/0]nhrp entry multicast dynamic —开启中心站点伪广播
entry multicast dynamic:进入多播动态
2、开启伪广播后,分支站点只能收到中心站点的路由信息,却不能收到其他分支站点的路由信息。—RIP水平分割导致(从哪个接口学习到的信息,就不从哪个接口发出去了)
[r1-Tunnel0/0/0]undo rip split-horizon —关闭接口水平分割功能
1、中心站点R1想要和R3通讯时,发送的数据包:
SIP:15.0.0.1 目标IP:35.0.0.1 真实的SIP:192.168.1.1 真实的目标IP:192.168.3.2
2、R3给中心站点R1回复数据包:
SIP:35.0.0.1 目标IP:15.0.0.1 真实的SIP:192.168.3.1 真实的目标IP:192.168.1.1
3、R3给R2发送数据包:
SIP:35.0.0.1 目标IP:15.0.0.1 真实的SIP:192.168.3.1 真实的目标IP:192.168.2.1
OSPF:开放式最短路径优先协议
选路佳,收敛少速度快,占用资源
收敛:基于拓扑变化而自动更新加载到路由表的过程
收敛速度的快慢取决于计时器
RIP传递的路由信息,单个数据包里携带的路由信息(目标网段和开销值),单个数据包占用资源较少,但是RIP协议有30s的周期更新,这样传递的数据包多,占用资源就多了
OSPF传递的是拓扑信息(将拓扑结构收集齐,拼在一起构成一个网络结构)
OSPF的传递时间是30Min
RIP存在三个版本
RIPV1,RIPV2----主要运行在IPV4
RIPNG----主要运行在IPV6
OSPF也存在三个版本
OSPFV1(在实验室阶段已经夭折了),OSPFV2—IPV4
OSPFV3—IPV6
RIPV2和OSPFV2的异同点:
相同点:
1、RIPV2和OSPFV2一样,都是无类别的路由协议(传递路由信息时携带子网掩码),都支持VLSM和CIDR
2、OSPFV2和RIPV2(224.0.0.9)都是以组播的形式传递息。—224.0.0.5/224.0.0.6
3、OSPFV2和RIPV2都支持等开销负载均衡。
不同点:
OSPF和RIP 不同,RIP要求仅适用于中小型的网络环境中,OSPF可以应用于中大型的网络环境中。
OSPF未来适应中大型网络环境,需要进行结构化部署。—区域划分
当网络规模不大时,我们也可以将OSPF网络划分在一个区域内,这样的OSPF网络,称为 单区域OSPF网络。
如果,一个OSPF网络当中包含多个OSPF区域,称为多区域OSPF网络。
单区域OSPF网络:是区域多少都无所谓。
区域划分的主要目的:
区域内部传递拓扑信息,区域之间传递路由信息(链路状态下距离矢量特征)(这样才能达到占用资源少的目的)
区域边界路由器:ABR (连接两个OSPF协议中间的路由器,同时处于多个区域,并且一个接口对应一个区域)—至少有一个接口属于骨干区域。
区域之间可以存在多个ABR,一个ABR也可以对应多个区域。
区域划分的要求:
1、区域之间必须存在ABR
2、区域划分必须按照星型拓扑结构划分:所有区域需要连接在中心区域上,这个中心我们称之为骨干区域。
为了方便各个区域进行区分和管理,我们给每个区域设计一个编号—区域ID(area ID)—由32位二进制构成—可以通过点分十进制的形式来表示,也可以直接使用十进制来进行表示—规定,骨干区域的区域ID必须是0.
RIP传递的是路由信息
OSPF传递的是拓扑信息(要知道每台路由器在哪)
LSA信息:是拓扑信息
OSPF:
1、OSPF的数据包
OSPF一共存在五种数据包
hello包 : 用来周期发现,建立和保活邻居关系
hello包的周期发送时间是10秒(30秒)(在不同的网络类型下,时间不同)
死亡时间: dead time ,是四倍的hello时间—40s(120s)
因为OSPF传递的是拓扑信息,需要将所有路由器的位置关系表示清楚,所以,需要有一个参数对所有的路由器进行区分和标定,我们引入RID来完成这个工作。
RID需要满足的条件:1、确保唯一性(全OSPF网络内部唯一即可) 2、格式统一----由32位二进制构成,采用IP地址的格式。(例如2.2.2.2)
RID的获取方法:(两种)
1、手工配置:仅需满足以上两点要求即可
2、自动获取:如果是自动获取,设备将会在自己环回接口的IP地址中选择最大的作为自己的RID(单纯的数字最大)。如果没有环回接口,则将在自己的物理接口上选择IP地址最大的作为RID(数值最大)。
hello包中会携带这个RID.
DBD包 : 数据库描述报文(告诉对端有什么LSA)----携带的是数据库(LSDB—存放LSA信息的数据库)的目录信息。
LSR包 : 链路状态请求报文—基于DBD包去请求未知的LSA信息(自己本地没有的LSA信息)
LSU包 : 链路状态更新报文—真正携带LSA信息的数据包。
LSACK包: 链路状态确认报文—确认包
OSPF存在每30min一次的周期更新
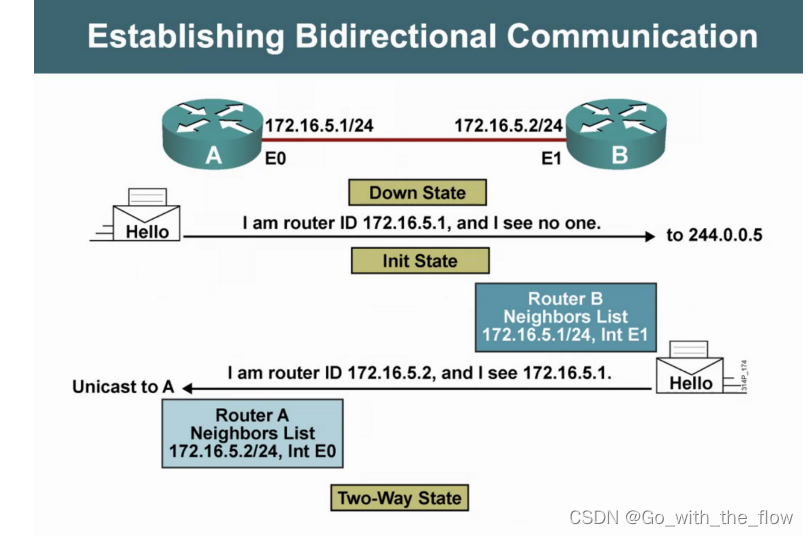
Two-way—标志着邻居关系的建立
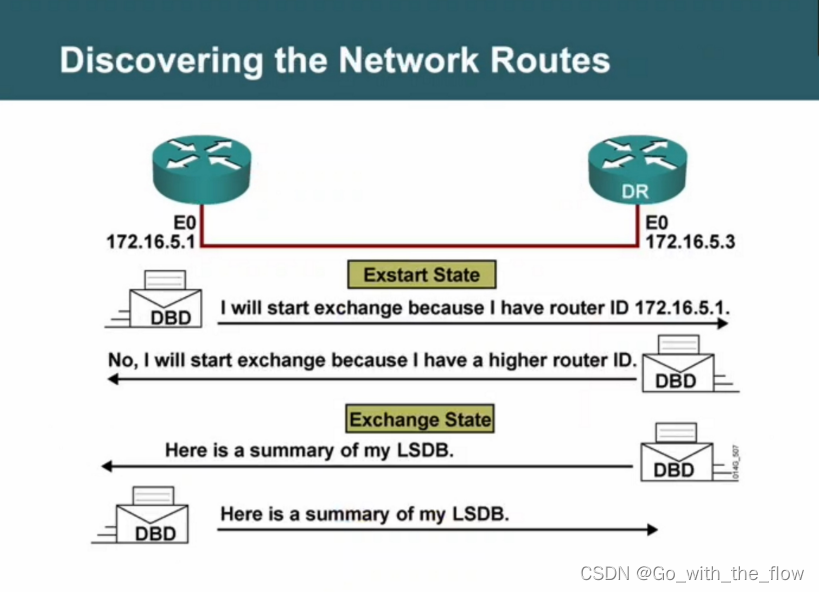
Exstart状态: 主从关系选举—使用未携带数据的DBD包(主要是为了和之前的邻居关系进行区分),通过比较RID大小进行主从关系选举,RID大的为主,可以优先进入下一个阶段
所有的DBD包都是通过隐形确认来确认的,不是通过ACK来确认的。
主从关系确认之后,可以进行隐形确认。
显性确认:回复ACK包就是显性确认。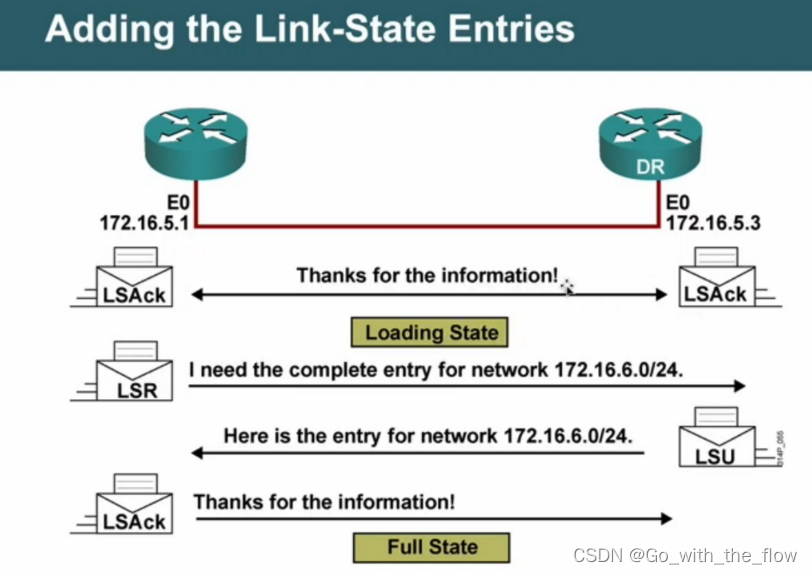
FULL状态—标志着邻接关系的建立(条件匹配成功)。—邻接关系主要是为了和之前邻居关系进行区分。
邻居关系仅能使用hello包进行周期保活,只有邻接关系,可以去交换LSA信息。
总结:
down状态:启动OSPF之后,发出hello包进入下一个状态
init(初始化)状态:hello包中包含本地的RID时进入下一状态
Two-way(双向通讯)状态: 标志着邻居关系的建立
条件匹配:条件匹配成功,则进入下一个状态;否则,只能停留在邻居关系,靠hello包进行周期保活。
Exstart(预启动)状态:使用未携带数据的DBD包进行主从关系的选举,比较RID,RID大的为主,可以优先进入下一个状态。
exchange(准交换)状态:使用携带数据的DBD包进行数据库目录摘要的共享。
loading(加载)状态:查看对端的DBD包中的信息和本地的LSDB数据库目录信息进行对比,基于未知的LSA信息发送LSR包,对端回复LSU包,需要LSACK进行确认。
FULL状态—标志着邻接关系的建立
3、OSPF工作过程
启动配置完成后,OSPF向本地所有运行OSPF协议的接口以组播224.0.0.5发hello包。Hello包中携带本地的RID以及本地已知邻居的RID。之后,将收集到的邻居关系记录在一张表中—邻居表。
邻居表建立之后,将进行条件匹配;失败则将停留在邻居关系,仅使用hello包进行周期保活。
匹配成功,则开始建立邻接关系。首先使用未携带数据的DBD包进行主从关系选举。之后,使用携带数据的DBD包进行数据库目录的共享。之后,本地使用LSR/LSU/LSACK数据包来获取未知的LSA信息;完成本地数据库的建立。—LSDB(链路状态数据库)—生成数据库表。
最后,基于本地的链路状态数据库,生成有向图,之后,通过SPF算法将有向图转换成最短路径树。之后,计算本地到达未知网段的路由信息,将路由信息添加到路由表中。
收敛完成后,hello包依然需要进行10S(30S)一次的周期保活,没30MIN进行一次周期更新。
网络结构突变
1、增加一个网段:触发更新,直接通过LSU包将变更信息发送,需要ACK确认。
2、断开一个网段:触发更新,直接通过LSU包将变更信息发送,需要ACK确认。
3、无法沟通:死亡时间—40S(120S)
4、OSPF的基本配置
1、启动OSPF进程
[r1]ospf 1 router-id 1.1.1.1 —1 进程号,仅具有本地意义
手工配置RID在启动进程时完成
[r1-ospf-1]
2、创建区域[r1-ospf-1]area 0[r1-ospf-1-area-0.0.0.0]
3、宣告
宣告的目的:
1、激活接口—只有激活的接口才能收发OSPF的数据
2、发布路由—只有激活接口对应网段信息才能发布出去
[r1-ospf-1-area-0.0.0.0]network 12.0.0.0 0.0.0.255—反掩码—由连续的0和连续的1组成(0对应的位不可变,1对应位可变)
[r1]display ospf peer —查看OSPF的邻居表
[r1]display ospf peer brief ----查看邻居关系的简表
[r1]display ospf lsdb —查看数据库表
[r1]display ospf lsdb router 2.2.2.2—展开一跳LSA信息
华为设备给OSPF定义的默认优先级为10。
OSPF是以带宽作为开销值的----COST = 参考带宽/ 真实带宽—华为设备OSPF默认的参考带宽是100Mbps
OSPF开销值为小数时的处理逻辑,当该数值为大于1的小数,则将直接舍弃小数部分取整即可;如果是小于1的小数,则将直接设置为1。
[r1-ospf-1]bandwidth-reference 1000 —修改参考带宽值
注意,参考带宽修改,则所有设备上都需要改成相同的。















 184
184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









