






❤️点击上方,选择星标或置顶,每天给你送上干货❤️
作者 | godweiyang
出品 | 公众号:算法码上来(ID:GodNLP)
- BEGIN -
什么技术呢?就是量化,别激动,不是量化交易,这里是指模型精度上的int8量化。
Transformer系列模型都在用吧?
Hugging Face都在用吧?
Fairseq都在用吧?
那你们训练和推理的时候没有觉得很慢吗?之前教过你们怎么用LightSeq来加速:
只用几行代码,我让模型训练加速了3倍
只用两行代码,我让模型推理加速了10倍
今天教你们一个更快的方法,用int8量化来进一步加速!
还是用一个有趣的GPT2文本生成模型来做例子,先来看一段AI生成的话解解闷(97-style,懂得都懂):
我有男朋友了,我们要是面基了,我会叫他们帮我介绍感情的,介绍不了,他们那些技术活,我不是很感兴趣呀,我都不想看他们那些,但是,我觉得有人靠得住,就不会被气着,但是,我不介意他们说我看不上他们,可能他们就是想我不错,然后我就不敢看他们了,我还有希望,一米八几的,我感觉搞金融的比做程序员有钱多了,因为我做金融的很多比我大很多,我不知道,然后每次听到他们讲什么,我就很想去学习

到底有多快?
废话不多说,先来看看到底有多快。
首先是在A100显卡上的训练总时间(秒):
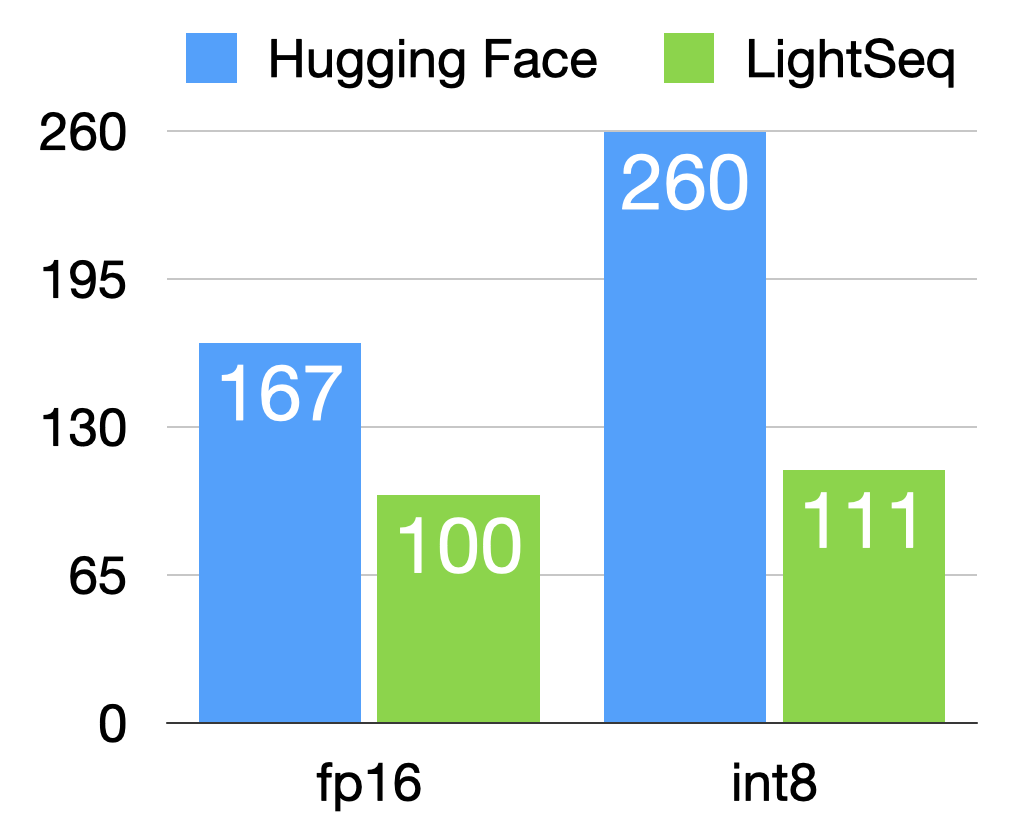
可以看出,Hugging Face的int8训练(实则是伪量化)太慢了,比fp16还慢。而LightSeq的fp16和int8时间差不多,int8能快个2.3倍左右。
可能这时候有人要问了,你这int8训练比fp16还慢,我干嘛用int8呢?别急,看看int8训练完之后,推理的速度到底有多快。
下面在T4显卡上生成长度500的一句话的推理时间(毫秒):
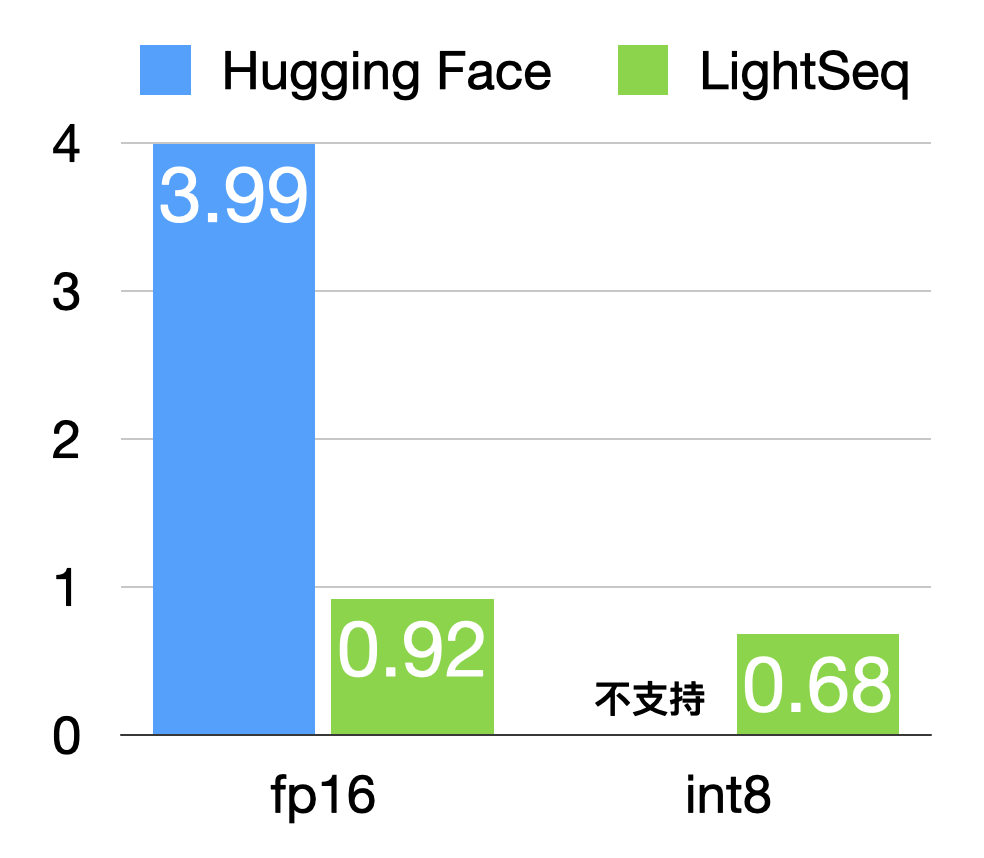
可以看出,Hugging Face根本就不支持int8推理!而LightSeq int8推理比fp16还能快1.35倍左右,比起Hugging Face的fp16更是不知道快到哪里去了,5.9倍妥妥的!

源代码
我将GPT2模型的训练、导出和推理代码都从LightSeq源码中抽离出来了,删除了冗余的部分,只留下了最最最精华的部分。数据和训好的模型也都开源了,具体运行命令我放在文章最后了:
https://github.com/godweiyang/ls-gpt2-demo
如果想学习完整的使用方法和LightSeq实现原理,还是建议直接去看LightSeq源码:
https://github.com/bytedance/lightseq
基本原理
int8为什么这么快?我不做过多细节的介绍,最近会发布详细的技术博客,这里只简单说几点基本原理:
int8的矩阵乘法更快。
int8的数据读写更快。
int8的参数存储更小。
所以LightSeq的int8训练和推理都非常快,但为啥Hugging Face的int8就这么慢呢?因为它不支持int8的矩阵乘法,只能用插入伪量化结点的方法来模拟int8量化,所以反而会更慢。
目前LightSeq的int8量化不仅速度更快,还做到了大部分任务上效果基本无损,用起来还非常简单!
运行命令
如果你说不在乎时间,不在乎显卡贵,就是有钱任性。那好,有本事直接用fp16,别用int8好了。

用fp16精度pretrain模型
训练数据train.txt里面,一行一段话,大概500字左右。也可以替换成你自己的语料,我这里是某知名水友的群聊语录。
python3 -m torch.distributed.launch \
--nproc_per_node=8 \
train.py \
--model_name_or_path uer/gpt2-chinese-cluecorpussmall \
--train_file data/train.txt \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 8 \
--num_train_epochs 150 \
--learning_rate 1.5e-4 \
--output_dir model/fp16 \
--overwrite_output_dir \
--fp16 \
--logging_steps 10 \
--enable_quant false导出fp16模型
这里-l可以指定生成的最大长度。
python3 export.py \
-m model/fp16/pytorch_model.bin \
-l 500用fp16模型生成句子
这里-p用来指定词表所在的路径。
python3 generate.py \
-m model/fp16/pytorch_model.hdf5 \
-i "我好难受" \
-p "uer/gpt2-chinese-cluecorpussmall"但是如果你没啥钱,就想快点训练和推理完,那就直接上int8量化吧!

用fp16精度pretrain模型
第一步跟刚刚fp16训练一样,先预训练一个fp16的模型,这样能避免int8效果损失。
python3 -m torch.distributed.launch \
--nproc_per_node=8 \
train.py \
--model_name_or_path uer/gpt2-chinese-cluecorpussmall \
--train_file data/train.txt \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 8 \
--num_train_epochs 150 \
--learning_rate 1.5e-4 \
--output_dir model/fp16 \
--overwrite_output_dir \
--fp16 \
--logging_steps 10 \
--enable_quant false用int8精度finetune模型
然后在刚刚预训练的fp16模型基础上,用int8再finetune一会儿。
python3 -m torch.distributed.launch \
--nproc_per_node=8 \
train.py \
--model_name_or_path uer/gpt2-chinese-cluecorpussmall \
--train_file data/train.txt \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 8 \
--num_train_epochs 200 \
--learning_rate 5e-6 \
--output_dir model/int8 \
--overwrite_output_dir \
--resume_from_checkpoint model/fp16 \
--fp16 \
--logging_steps 10 \
--enable_quant true导出int8模型
导出int8模型,-q指定导出的是int8模型。
python3 export.py \
-m model/int8/pytorch_model.bin \
-l 500 \
-q用int8模型生成句子
这里-q指定用int8模型来推理。
python3 generate.py \
-m model/int8/pytorch_model.hdf5 \
-i "我好难受" \
-p "uer/gpt2-chinese-cluecorpussmall" \
-q- END -
我是godweiyang,字节跳动算法工程师,华师计算机本硕均专业第一。秋招斩获三家大厂SSP offer,擅长算法、模型优化和机器翻译。
回复【算法】
获取我面试时写过的100多道算法题解,刷完进大厂没问题。
回复【CUDA】
获取我为新手准备的CUDA入门系列教程。
回复【内推】
内推字节,通过率高,加我微信可随时查催进度、咨询问题。
回复【加群】
进我的技术交流(聊天)群和内推群,群内有字节HR答疑。

求求兄弟们点个在看吧,今天的阅读量靠你们了👇















 1915
1915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











