







引言
Mahout包含一个推荐引擎,其中有几种类型实际来自于传统的基于用户和基于物品的推荐程序。它也包含了其他几个算法实现,但是现在我们先看一个简单的基于用户的推荐程序。
目录
- 创建输入
- 创建一个推荐程序
- 分析输出
- 评估一个推荐程序
- 训练数据与评分
- 运行RecommenderEvaluator
- 评估结果
- 评估查准率和查全率
- 运行RecommenderIRStatsEvaluator
- 评估GroupLens数据集
1、创建输入
推荐程序需要有输入——构成推荐的基础数据。在Mahout语言中,数据是以偏好(preference)的形式来表达的。因为最常见的推荐引擎总是把项目推荐给用户,所以谈论偏好最简便的方法是建立从用户到物品的关联,尽管如前所述,这些用户和物品是可以任意指定的。一个偏好包含一个用户ID、一个物品ID,通常还有一个表达用户对物品的偏好程度的数值。实际上,Mahout中的ID通常也为数字——整数。偏好值(preference value)可任意设定,只需保证更大的值代表更强的正向偏好。例如,这些可能按1到5来定级,其中1表示用户非常不喜欢该物品·,而5表示物品是用户的挚爱。
复制下面的示例到一个文件中并将之保存为为intro.csv:
代码清单 推荐程序的输入文件intro.csv:
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.02、创建一个推荐程序
那么,可以为用户1推荐什么书呢?不是101、102和103,因为用户1显然已经知道这些书了,而推荐是用来发现新事物的。直观看,既然用户4和用户5与用户1类似,那么把用户4或用户5喜欢的东西推荐给用户1是个好主意。这样一来,可能的推荐结果就是书104、105和106。
现在,运行如下代码:
package com.jay.mahoutinaction;
import java.io.File;
import java.util.List;
import org.apache.mahout.cf.taste.impl.model.file.FileDataModel;
import org.apache.mahout.cf.taste.impl.neighborhood.NearestNUserNeighborhood;
import org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender;
import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.neighborhood.UserNeighborhood;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.cf.taste.recommender.Recommender;
import org.apache.mahout.cf.taste.similarity.UserSimilarity;
class RecommenderIntro {
private RecommenderIntro(){
}
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
//装载数据文件
DataModel model=new FileDataModel(new File("d:\\intro.csv"));
UserSimilarity similarity=new PearsonCorrelationSimilarity(model);
UserNeighborhood neighborhood=new NearestNUserNeighborhood(2,similarity,model);
//生成推荐引擎
Recommender recommender=new GenericUserBasedRecommender(model,neighborhood,similarity);
List<RecommendedItem> recommendations =recommender.recommend(1,1);//为用户1推荐物品1
for(RecommendedItem recommendation:recommendations)
System.out.println(recommendation);
}
}
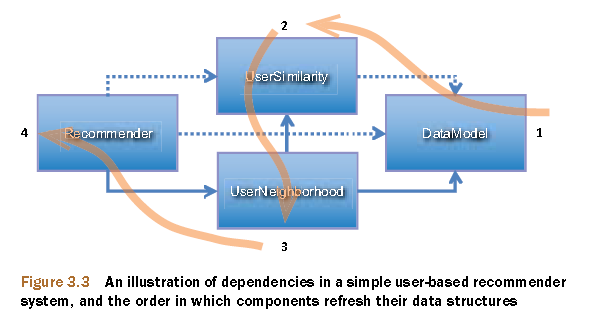
现在对每个组件的角色做个概览。DataModel实现存储并为计算机提供其所需要的偏好、用户和物品数据。UserSimilarity实现给出两个用户之间的相似度,可从多个可能度量或计算中选出一种来作为依据。UserNeighborhood实现明确了与给定用户最相似的一组用户,最后,Recommender实现合并所有这些组件为用户推荐物品。
3、分析输出
我的IDE(集成开发环境)输出如下结果:
15/04/19 23:08:56 INFO file.FileDataModel: Creating FileDataModel for file d:\intro.csv
15/04/19 23:08:57 INFO file.FileDataModel: Reading file info...
15/04/19 23:08:57 INFO file.FileDataModel: Read lines: 21
15/04/19 23:08:57 INFO model.GenericDataModel: Processed 5 users
RecommendedItem[item:104, value:4.257081]
从数据中不能一眼看出答案,但是推荐引擎找到了它的踪迹,并返回一个合理的答案。这个简单的程序找到了一个不易发现的有用结果,如果你为此感到欢欣鼓舞,那就表示机器学习的世界很适合我!
对于干净的小数据集,生成推荐结果就像前面的示例一样简单。但是现实中,数据集往往非常庞大,而且其中很多信息没有价值。例如,假设一个受欢迎的新闻网站要为读者推荐新闻文章。可以根据文章点击率推断出偏好,但也可能会产生很多假的偏好——或许读者点击了并不喜欢的文章,或错误地点击了一个故事。或许很多点击发生在未登录的状态下,因而不能与某个用户进行对应。再试想一下数据的大小——也许每个月的点击量有几十亿次。
要在数据之上快速生成准确的推荐结果并不简单。后面的案例研究中,我将使用Mahout提供的工具解决一组这样的问题。他们会为你呈现标准的方法会如何导致糟糕的推荐结果,或是耗费大量的内存和CPU时间,同时展示如何配置和定制Mahout来提高性能。
4、评估一个推荐程序
推荐引擎是一种工具,一种解决问题的手段。“什么是对用户最好的推荐?”最佳的推荐程序应该就像一个“巫师”,它能够在你行动之前设法准确地获得你喜欢的每一种可能的物品,而且这些物品是你尚未见过或没有对其表达喜好意见的。能够准确预测你所有喜好和行为的推荐程序还应该按您未来的喜好把物品进行排队。最优的潜在推荐结果应该是这样的。
而实际上,大多数推荐引擎仅会试图给出某些或其他所有物品的估计评分。由此,一种评分推荐程序推荐结果的方法是评估其估计偏好值的质量——即评估所估计的偏好在多大程度上与实际偏好相匹配的。
5、训练数据与评分
但是,没有现成的实际偏好值可用。没有人能够确切知道你将来有多喜欢某些东西(包括你自己)。在推荐引擎中,这可以通过提取一小段真实数据作为测试数据来仿真。这些用来测试的偏好不会作为训练数据导入到被评估的推荐引擎。相反,推荐程序需要为这些缺失的测试数据估计出偏好,然后估计结果用于与真实值进行对照。进而,我们可以为推荐程序做出一种评分。例如,可以计算出在估计和实际偏好之间的平均差值。在这种评分中,值越低越好,因为值越低意味着估计值和实际值之间的差别越小。有时,会使用差值的均方根:计算出实际偏好值与估计值之间的差值之后,先进行平方再求其均值的平方根。
6、运行RecommenderEvaluator
配置并评估一个推荐程序:
package com.jay.mahoutinaction;
import java.io.File;
import org.apache.mahout.cf.taste.common.TasteException;
import org.apache.mahout.cf.taste.eval.RecommenderBuilder;
import org.apache.mahout.cf.taste.eval.RecommenderEvaluator;
import org.apache.mahout.cf.taste.impl.eval.AverageAbsoluteDifferenceRecommenderEvaluator;
import org.apache.mahout.cf.taste.impl.model.file.FileDataModel;
import org.apache.mahout.cf.taste.impl.neighborhood.NearestNUserNeighborhood;
import org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender;
import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.neighborhood.UserNeighborhood;
import org.apache.mahout.cf.taste.recommender.Recommender;
import org.apache.mahout.cf.taste.similarity.UserSimilarity;
import org.apache.mahout.common.RandomUtils;
class EvaluatorIntro {
private EvaluatorIntro() {
}
public static void main(String[] args) throws Exception {
RandomUtils.useTestSeed();
DataModel model = new FileDataModel(new File("d:\\intro.csv"));
RecommenderEvaluator evaluator =
new AverageAbsoluteDifferenceRecommenderEvaluator();
// Build the same recommender for testing that we did last time:
RecommenderBuilder recommenderBuilder = new RecommenderBuilder() {
public Recommender buildRecommender(DataModel model) throws TasteException {
UserSimilarity similarity = new PearsonCorrelationSimilarity(model);
UserNeighborhood neighborhood =
new NearestNUserNeighborhood(2, similarity, model);
return new GenericUserBasedRecommender(model, neighborhood, similarity);
}
};
// Use 70% of the data to train; test using the other 30%.
double score = evaluator.evaluate(recommenderBuilder, null, model, 0.7, 1.0);
System.out.println(score);
}
}
输出结果:
15/04/20 08:37:30 INFO file.FileDataModel: Creating FileDataModel for file d:\intro.csv
15/04/20 08:37:30 INFO file.FileDataModel: Reading file info...
15/04/20 08:37:30 INFO file.FileDataModel: Read lines: 21
15/04/20 08:37:30 INFO model.GenericDataModel: Processed 5 users
15/04/20 08:37:30 INFO eval.AbstractDifferenceRecommenderEvaluator: Beginning evaluation using 0.7 of FileDataModel[dataFile:d:\intro.csv]
15/04/20 08:37:30 INFO model.GenericDataModel: Processed 5 users
15/04/20 08:37:30 INFO eval.AbstractDifferenceRecommenderEvaluator: Beginning evaluation of 3 users
15/04/20 08:37:30 INFO eval.AbstractDifferenceRecommenderEvaluator: Starting timing of 3 tasks in 4 threads
15/04/20 08:37:30 INFO eval.AbstractDifferenceRecommenderEvaluator: Average time per recommendation: 54ms
15/04/20 08:37:30 INFO eval.AbstractDifferenceRecommenderEvaluator: Approximate memory used: 6MB / 30MB
15/04/20 08:37:30 INFO eval.AbstractDifferenceRecommenderEvaluator: Unable to recommend in 6 cases
15/04/20 08:37:30 INFO eval.AbstractDifferenceRecommenderEvaluator: Evaluation result: 1.0
1.0
分析:大多数行为发生在evaluate()中:RecommenderEvaluator将数据分为训练集和测试集,构建一个新训练的DataModel与Recommender用于测试,并将估计的偏好值与实际测试数据进行比较。
注意:传递给evaluate()的参数中没有Recommender。这是因为在该方法中,Recommender是有新训练的DataModel来构建的。该方法的调用者必须提供一个对象——RecommenderBuilder,可以使用DataModel构建出Recommender。这里,该方法所用的是和之前所述相同的实现。
7、评估结果
一个显示Recommender表现如何的分数。在这个例子中,你会看到1.0这个值。即使evaluator在选择测试数据时引入许多随机量,结果仍是相同的,因为对RandomUtils.useTestSeed()调用会强制每次选择相同的随机量。这仅仅是为了获得可重复的结果,而被用在这样的示例或单元测试中。请不要在实际代码中这样用!!!
这个分值的意义取决于所采取的实现方法,这里是AverageAbsoluteDifferenceRecommenderEvaluator。在该实现中分值是1.0,这意味着平均而言推荐程序所给出的估计值与实际值的偏差为1.0。
在从1到5的区间中,1.0这个值不大,但我们这里只采用了非常少的数据。你来执行时所获得的结果也许会不同,因为对数据集的分片是随机的,而且程序每次运行所用的训练集和测试集也不可能一样。
这个技术可以应用与任何Recommender和DataModel。如果要使用均方根来评分,可以用RMSRecommenderEvaluator取代AverageAbsoluteDiffercenceRecommenderEvaluator。
你可以选择不向evaluate()传递null(空)参数,而是传递DataModelBuilder的一个实例(instance),它可以用于控制如何从训练数据中生成DataModel。通常默认为传空参数就够了,除非你使用了一个特殊的DataModel实现——一个你希望插入到评估过程中的DataModelBuilder。
最后传递给evaluate()参数1.0用来控制总共使用多少输入数据的。这里,它是指100%的数据。这个参数可用于仅通过庞大数据集中的很小部分数据,来生成一个精度较低但更快的评估。例如,0.1代表使用10%的数据,而90%的数据被忽略。当你希望快速测试Recommender中一些小的更改时这个参数会很有用的。
8、评估查准率和查全率
我们还应该更全面地看待推荐问题:通过估计偏好值来生成推荐结果并非绝对必要。给出一个从优到劣排列的推荐列表对于许多场景都够用了,而不必包含估计的偏好值。事实上,有时精确的列表顺序也不要那么重要——有几个好的推荐结果就可以了。
从这种更普遍的视角,我们可以运用经典的信息检索(information retrieval)度量标准来评估推荐程序:查准率(precision)和查全率(recall)。这些术语通常用在像搜素引擎这样的系统中,即从许多可能的搜素结果中返回一组最佳结果。
搜索引擎应该避免在top结果中返回无关信息, 而应竭力返回尽可能相关的结果。在一些对“相关”的定义中,查准率是指在top结果中相关结果的比例。Precision at 10(推荐10个结果时的查准率)是指这个比例来自对前10个top结果的判定。查全率是指所有相关结果包含在top结果中的比例。
这些术语很容易用在推荐程序中:查准率是top推荐中间有“好”结果的比例,而查全率是“好”结果出现在top推荐中的比例。
运行ReommenderIRStatsEvaluator
Mahout同样提供了一个相对简单的方法,为Recommender计算出这些值,如下面的代码:
package com.jay.mahoutinaction;
import java.io.File;
import org.apache.mahout.cf.taste.common.TasteException;
import org.apache.mahout.cf.taste.eval.IRStatistics;
import org.apache.mahout.cf.taste.eval.RecommenderBuilder;
import org.apache.mahout.cf.taste.eval.RecommenderIRStatsEvaluator;
import org.apache.mahout.cf.taste.impl.eval.GenericRecommenderIRStatsEvaluator;
import org.apache.mahout.cf.taste.impl.model.file.FileDataModel;
import org.apache.mahout.cf.taste.impl.neighborhood.NearestNUserNeighborhood;
import org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender;
import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.neighborhood.UserNeighborhood;
import org.apache.mahout.cf.taste.recommender.Recommender;
import org.apache.mahout.cf.taste.similarity.UserSimilarity;
import org.apache.mahout.common.RandomUtils;
class IREvaluator {
private IREvaluator(){
}
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
RandomUtils.useTestSeed();
DataModel model=new FileDataModel(new File("d:\\intro.csv"));
RecommenderIRStatsEvaluator evaluator=new GenericRecommenderIRStatsEvaluator();
RecommenderBuilder recommenderBuilder =new RecommenderBuilder(){
public Recommender buildRecommender(DataModel model) throws TasteException{
UserSimilarity similarity =new PearsonCorrelationSimilarity(model);
UserNeighborhood neighborhood=
new NearestNUserNeighborhood(2,similarity,model);
return
new GenericUserBasedRecommender(model,neighborhood,similarity);
}
};
IRStatistics stats=evaluator.evaluate(recommenderBuilder, null, model, null, 2, GenericRecommenderIRStatsEvaluator.CHOOSE_THRESHOLD, 1.0);
System.out.println(stats.getPrecision());
System.out.println(stats.getRecall());
}
}
输出结果:
15/04/20 10:10:32 INFO file.FileDataModel: Creating FileDataModel for file d:\intro.csv
15/04/20 10:10:32 INFO file.FileDataModel: Reading file info...
15/04/20 10:10:32 INFO file.FileDataModel: Read lines: 21
15/04/20 10:10:32 INFO model.GenericDataModel: Processed 5 users
15/04/20 10:10:32 INFO model.GenericDataModel: Processed 5 users
15/04/20 10:10:33 INFO eval.GenericRecommenderIRStatsEvaluator: Evaluated with user 2 in 21ms
15/04/20 10:10:33 INFO eval.GenericRecommenderIRStatsEvaluator: Precision/recall/fall-out/nDCG: 1.0 / 1.0 / 0.0 / 1.0
15/04/20 10:10:33 INFO model.GenericDataModel: Processed 5 users
15/04/20 10:10:33 INFO eval.GenericRecommenderIRStatsEvaluator: Evaluated with user 4 in 1ms
15/04/20 10:10:33 INFO eval.GenericRecommenderIRStatsEvaluator: Precision/recall/fall-out/nDCG: 0.75 / 1.0 / 0.08333333333333333 / 1.0
0.75
1.010、评估GroupLens数据集
GroupLens(http://goruplens.org)是一个研究项目,提供多个大小不同的数据集,每个都来自真实用户对电影的评分。它是几个可用的大规模真实数据集中的一个,以后还会给你介绍更多的数据集。
在GroupLens网站上,将下载的文件解压,在其中找到名为ua.base的文件。这是一个 以制表符(tab)分隔的文件,包含用户ID、物品ID、评分(偏好值),以及一些附加信息。
这个文件的字段用制表符分隔,而不是逗号,结尾还包含一个额外的信息字段。它可用吗?是的,这个文件可用于FileDataModel。回到运行RecommenderEvaluator的程序代码,创建一个RecommenderEvaluator,然后把ua.base的位置传递给他,而不是传递一个小数据文件。再次运行,这次评估会花上几分钟,因为现在是基于100 000个偏好值,而不是少数几个。
最终,你会得到一个大约为0.9的值。
修改运行RecommenderEvaluator的下面代码段:
DataModel model = new FileDataModel(new File("d:\\ua.base"));运行输出结果:
15/04/20 10:54:08 INFO file.FileDataModel: Creating FileDataModel for file d:\ua.base
15/04/20 10:54:08 INFO file.FileDataModel: Reading file info...
15/04/20 10:54:09 INFO file.FileDataModel: Read lines: 90570
15/04/20 10:54:09 INFO model.GenericDataModel: Processed 943 users
15/04/20 10:54:09 INFO eval.AbstractDifferenceRecommenderEvaluator: Beginning evaluation using 0.7 of FileDataModel[dataFile:d:\ua.base]
15/04/20 10:54:09 INFO model.GenericDataModel: Processed 943 users
15/04/20 10:54:09 INFO eval.AbstractDifferenceRecommenderEvaluator: Beginning evaluation of 939 users
15/04/20 10:54:09 INFO eval.AbstractDifferenceRecommenderEvaluator: Starting timing of 939 tasks in 4 threads
15/04/20 10:54:09 INFO eval.AbstractDifferenceRecommenderEvaluator: Average time per recommendation: 91ms
15/04/20 10:54:09 INFO eval.AbstractDifferenceRecommenderEvaluator: Approximate memory used: 36MB / 56MB
15/04/20 10:54:09 INFO eval.AbstractDifferenceRecommenderEvaluator: Unable to recommend in 348 cases
15/04/20 10:54:23 INFO eval.AbstractDifferenceRecommenderEvaluator: Evaluation result: 0.9041450777202074
0.9041450777202074















 1569
1569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









