



 本文介绍如何优化Mobilenet-SSD模型在特定硬件上的运行效率,特别是针对深度可分离卷积(DW)层的参数调整,以及如何在RuyiStudio中正确配置模型,确保检测结果的准确性。
本文介绍如何优化Mobilenet-SSD模型在特定硬件上的运行效率,特别是针对深度可分离卷积(DW)层的参数调整,以及如何在RuyiStudio中正确配置模型,确保检测结果的准确性。
我之前用的mobilenet-ssd模型中深度可分离卷积(dw)的prototxt如下
通过group来实现(代码中就是输入的8个featuremap经过分8组,每组各和一个卷积核做卷积运算,最后运算输出还是8个featuremap)
layer {
name: "conv1/dw"
type: "Convolution"
bottom: "conv0"
top: "conv1/dw"
convolution_param {
num_output: 8
pad: 1
kernel_size: 3
group: 8
engine: CAFFE
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
但是在NNIE中dw层是通过开源工程来重新定义过的,所以上面的prototxt是不符合nnie规范的,会有参数读不出来,导致后续计算出现没有检测结果的情况。
Depthwise Convolution 层,参考设计为Xeption网络,开源工程地址为
https://github.com/fchollet/keras/blob/master/keras/applications/xception.py。
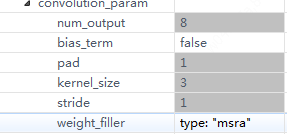
修改后DW层的描述如下,之后再在ruyi studio看,dw层参数就正常了。
layer {
name: "conv1/dw"
type: "Convolution"
bottom: "conv0"
top: "conv1/dw"
convolution_param {
num_output: 8
bias_term: false
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "msra"
}
}
}
1210更新 前面描述有误,nnie只是不支持dw层但可以用group的形式代替,
下面附一份ssd在ruyi上转化的代码,其中后处理priorbox的部分需要在cpu上实现计算,目前nnie不支持这块的加速(已用#部分),其余部分为nnie支持。
name: "MobileNet-SSD"
input: "data"
input_shape {
dim: 1
dim: 3
dim: 224
dim: 224
}
layer {
name: "conv0"
type: "Convolution"
bottom: "data"
top: "conv0"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 8
pad: 1
kernel_size: 3
stride: 2
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv0/relu"
type: "ReLU"
bottom: "conv0"
top: "conv0"
}
layer {
name: "conv1/dw"
type: "Convolution"
bottom: "conv0"
top: "conv1/dw"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 8
pad: 1
kernel_size: 3
group: 8
engine: CAFFE
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv1/dw/relu"
type: "ReLU"
bottom: "conv1/dw"
top: "conv1/dw"
}
layer {
name: "conv1"
type: "Convolution"
bottom: "conv1/dw"
top: "conv1"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 16
kernel_size: 1
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv1/relu"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "conv2/dw"
type: "Convolution"
bottom: "conv1"
top: "conv2/dw"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 16
pad: 1
kernel_size: 3
stride: 2
group: 16
engine: CAFFE
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv2/dw/relu"
type: "ReLU"
bottom: "conv2/dw"
top: "conv2/dw"
}
layer {
name: "conv2"
type: "Convolution"
bottom: "conv2/dw"
top: "conv2"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 32
kernel_size: 1
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv2/relu"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "conv3/dw"
type: "Convolution"
bottom: "conv2"
top: "conv3/dw"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 32
pad: 1
kernel_size: 3
group: 32
engine: CAFFE
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv3/dw/relu"
type: "ReLU"
bottom: "conv3/dw"
top: "conv3/dw"
}
layer {
name: "conv3"
type: "Convolution"
bottom: "conv3/dw"
top: "conv3"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 32
kernel_size: 1
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv3/relu"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "conv4/dw"
type: "Convolution"
bottom: "conv3"
top: "conv4/dw"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 32
pad: 1
kernel_size: 3
stride: 2
group: 32
engine: CAFFE
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv4/dw/relu"
type: "ReLU"
bottom: "conv4/dw"
top: "conv4/dw"
}
layer {
name: "conv4"
type: "Convolution"
bottom: "conv4/dw"
top: "conv4"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 64
kernel_size: 1
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv4/relu"
type: "ReLU"
bottom: "conv4"
top: "conv4"
}
layer {
name: "conv5/dw"
type: "Convolution"
bottom: "conv4"
top: "conv5/dw"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
group: 64
engine: CAFFE
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv5/dw/relu"
type: "ReLU"
bottom: "conv5/dw"
top: "conv5/dw"
}
layer {
name: "conv5"
type: "Convolution"
bottom: "conv5/dw"
top: "conv5"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 64
kernel_size: 1
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv5/relu"
type: "ReLU"
bottom: "conv5"
top: "conv5"
}
layer {
name: "conv6/dw"
type: "Convolution"
bottom: "conv5"
top: "conv6/dw"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
stride: 2
group: 64
engine: CAFFE
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv6/dw/relu"
type: "ReLU"
bottom: "conv6/dw"
top: "conv6/dw"
}
layer {
name: "conv6"
type: "Convolution"
bottom: "conv6/dw"
top: "conv6"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 64
kernel_size: 1
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv6/relu"
type: "ReLU"
bottom: "conv6"
top: "conv6"
}
layer {
name: "conv7/dw"
type: "Convolution"
bottom: "conv6"
top: "conv7/dw"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
group: 64
engine: CAFFE
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv7/dw/relu"
type: "ReLU"
bottom: "conv7/dw"
top: "conv7/dw"
}
layer {
name: "conv7"
type: "Convolution"
bottom: "conv7/dw"
top: "conv7"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 64
kernel_size: 1
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv7/relu"
type: "ReLU"
bottom: "conv7"
top: "conv7"
}
layer {
name: "conv8/dw"
type: "Convolution"
bottom: "conv7"
top: "conv8/dw"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
group: 64
engine: CAFFE
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv8/dw/relu"
type: "ReLU"
bottom: "conv8/dw"
top: "conv8/dw"
}
layer {
name: "conv8"
type: "Convolution"
bottom: "conv8/dw"
top: "conv8"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 64
kernel_size: 1
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv8/relu"
type: "ReLU"
bottom: "conv8"
top: "conv8"
}
layer {
name: "conv9/dw"
type: "Convolution"
bottom: "conv8"
top: "conv9/dw"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
group: 64
engine: CAFFE
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv9/dw/relu"
type: "ReLU"
bottom: "conv9/dw"
top: "conv9/dw"
}
layer {
name: "conv9"
type: "Convolution"
bottom: "conv9/dw"
top: "conv9"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 64
kernel_size: 1
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv9/relu"
type: "ReLU"
bottom: "conv9"
top: "conv9"
}
layer {
name: "conv10/dw"
type: "Convolution"
bottom: "conv9"
top: "conv10/dw"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
group: 64
engine: CAFFE
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv10/dw/relu"
type: "ReLU"
bottom: "conv10/dw"
top: "conv10/dw"
}
layer {
name: "conv10"
type: "Convolution"
bottom: "conv10/dw"
top: "conv10"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 64
kernel_size: 1
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv10/relu"
type: "ReLU"
bottom: "conv10"
top: "conv10"
}
layer {
name: "conv11/dw"
type: "Convolution"
bottom: "conv10"
top: "conv11/dw"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
group: 64
engine: CAFFE
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv11/dw/relu"
type: "ReLU"
bottom: "conv11/dw"
top: "conv11/dw"
}
layer {
name: "conv11"
type: "Convolution"
bottom: "conv11/dw"
top: "conv11"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 64
kernel_size: 1
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv11/relu"
type: "ReLU"
bottom: "conv11"
top: "conv11"
}
layer {
name: "conv12/dw"
type: "Convolution"
bottom: "conv11"
top: "conv12/dw"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
stride: 2
group: 64
engine: CAFFE
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv12/dw/relu"
type: "ReLU"
bottom: "conv12/dw"
top: "conv12/dw"
}
layer {
name: "conv12"
type: "Convolution"
bottom: "conv12/dw"
top: "conv12"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 128
kernel_size: 1
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv12/relu"
type: "ReLU"
bottom: "conv12"
top: "conv12"
}
layer {
name: "conv13/dw"
type: "Convolution"
bottom: "conv12"
top: "conv13/dw"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 128
pad: 1
kernel_size: 3
group: 128
engine: CAFFE
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv13/dw/relu"
type: "ReLU"
bottom: "conv13/dw"
top: "conv13/dw"
}
layer {
name: "conv13"
type: "Convolution"
bottom: "conv13/dw"
top: "conv13"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 128
kernel_size: 1
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv13/relu"
type: "ReLU"
bottom: "conv13"
top: "conv13"
}
#========================================================
#========================================================
#========================================================
layer {
name: "conv10_mbox_loc"
type: "Convolution"
bottom: "conv10"
top: "conv10_mbox_loc"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 12
kernel_size: 1
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv10_mbox_loc_perm"
type: "Permute"
bottom: "conv10_mbox_loc"
top: "conv10_mbox_loc_perm"
permute_param {
order: 0
order: 2
order: 3
order: 1
}
}
# layer {
# name: "conv10_mbox_loc_flat"
# type: "Flatten"
# bottom: "conv10_mbox_loc_perm"
# top: "conv10_mbox_loc_flat"
# flatten_param {
# axis: 1
# }
# }
layer {
name: "conv10_mbox_conf_new"
type: "Convolution"
bottom: "conv10"
top: "conv10_mbox_conf"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output: 18
kernel_size: 1
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv10_mbox_conf_perm"
type: "Permute"
bottom: "conv10_mbox_conf"
top: "conv10_mbox_conf_perm"
permute_param {
order: 0
order: 2
order: 3
order: 1
}
}
# layer {
# name: "conv10_mbox_conf_flat"
# type: "Flatten"
# bottom: "conv10_mbox_conf_perm"
# top: "conv10_mbox_conf_flat"
# flatten_param {
# axis: 1
# }
# }
# layer {
# name: "conv10_mbox_priorbox"
# type: "PriorBox"
# bottom: "conv10"
# bottom: "data"
# top: "conv10_mbox_priorbox"
# prior_box_param {
# min_size: 22.4
# max_size: 35.84
# aspect_ratio: 3.0
# flip: false
# clip: false
# variance: 0.1
# variance: 0.1
# variance: 0.2
# variance: 0.2
# offset: 0.5
# }
# }
layer {
name: "conv11_mbox_loc"
type: "Convolution"
bottom: "conv11"
top: "conv11_mbox_loc"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 12
kernel_size: 1
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv11_mbox_loc_perm"
type: "Permute"
bottom: "conv11_mbox_loc"
top: "conv11_mbox_loc_perm"
permute_param {
order: 0
order: 2
order: 3
order: 1
}
}
# layer {
# name: "conv11_mbox_loc_flat"
# type: "Flatten"
# bottom: "conv11_mbox_loc_perm"
# top: "conv11_mbox_loc_flat"
# flatten_param {
# axis: 1
# }
# }
layer {
name: "conv11_mbox_conf_new"
type: "Convolution"
bottom: "conv11"
top: "conv11_mbox_conf"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output: 18
kernel_size: 1
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv11_mbox_conf_perm"
type: "Permute"
bottom: "conv11_mbox_conf"
top: "conv11_mbox_conf_perm"
permute_param {
order: 0
order: 2
order: 3
order: 1
}
}
# layer {
# name: "conv11_mbox_conf_flat"
# type: "Flatten"
# bottom: "conv11_mbox_conf_perm"
# top: "conv11_mbox_conf_flat"
# flatten_param {
# axis: 1
# }
# }
# layer {
# name: "conv11_mbox_priorbox"
# type: "PriorBox"
# bottom: "conv11"
# bottom: "data"
# top: "conv11_mbox_priorbox"
# prior_box_param {
# min_size: 35.84
# max_size: 49.28
# aspect_ratio: 3.0
# flip: false
# clip: false
# variance: 0.1
# variance: 0.1
# variance: 0.2
# variance: 0.2
# offset: 0.5
# }
# }
layer {
name: "conv13_mbox_loc"
type: "Convolution"
bottom: "conv13"
top: "conv13_mbox_loc"
param {
lr_mult: 0.1
decay_mult: 0.1
}
param {
lr_mult: 0.2
decay_mult: 0.0
}
convolution_param {
num_output: 12
kernel_size: 1
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv13_mbox_loc_perm"
type: "Permute"
bottom: "conv13_mbox_loc"
top: "conv13_mbox_loc_perm"
permute_param {
order: 0
order: 2
order: 3
order: 1
}
}
# layer {
# name: "conv13_mbox_loc_flat"
# type: "Flatten"
# bottom: "conv13_mbox_loc_perm"
# top: "conv13_mbox_loc_flat"
# flatten_param {
# axis: 1
# }
# }
layer {
name: "conv13_mbox_conf_new"
type: "Convolution"
bottom: "conv13"
top: "conv13_mbox_conf"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output: 18
kernel_size: 1
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv13_mbox_conf_perm"
type: "Permute"
bottom: "conv13_mbox_conf"
top: "conv13_mbox_conf_perm"
permute_param {
order: 0
order: 2
order: 3
order: 1
}
}
# layer {
# name: "conv13_mbox_conf_flat"
# type: "Flatten"
# bottom: "conv13_mbox_conf_perm"
# top: "conv13_mbox_conf_flat"
# flatten_param {
# axis: 1
# }
# }
# layer {
# name: "conv13_mbox_priorbox"
# type: "PriorBox"
# bottom: "conv13"
# bottom: "data"
# top: "conv13_mbox_priorbox"
# prior_box_param {
# min_size: 49.28
# max_size: 62.72
# aspect_ratio: 3.0
# flip: false
# clip: false
# variance: 0.1
# variance: 0.1
# variance: 0.2
# variance: 0.2
# offset: 0.5
# }
# }
# layer {
# name: "mbox_loc"
# type: "Concat"
# bottom: "conv10_mbox_loc_flat"
# bottom: "conv11_mbox_loc_flat"
# bottom: "conv13_mbox_loc_flat"
# top: "mbox_loc"
# concat_param {
# axis: 1
# }
# }
# layer {
# name: "mbox_conf"
# type: "Concat"
# bottom: "conv10_mbox_conf_flat"
# bottom: "conv11_mbox_conf_flat"
# bottom: "conv13_mbox_conf_flat"
# top: "mbox_conf"
# concat_param {
# axis: 1
# }
# }
# layer {
# name: "mbox_priorbox"
# type: "Concat"
# bottom: "conv10_mbox_priorbox"
# bottom: "conv11_mbox_priorbox"
# bottom: "conv13_mbox_priorbox"
# top: "mbox_priorbox"
# concat_param {
# axis: 2
# }
# }
# layer {
# name: "mbox_conf_reshape"
# type: "Reshape"
# bottom: "mbox_conf"
# top: "mbox_conf_reshape"
# reshape_param {
# shape {
# dim: 0
# dim: -1
# dim: 6
# }
# }
# }
# layer {
# name: "mbox_conf_softmax"
# type: "Softmax"
# bottom: "mbox_conf_reshape"
# top: "mbox_conf_softmax"
# softmax_param {
# axis: 2
# }
# }
# layer {
# name: "mbox_conf_flatten"
# type: "Flatten"
# bottom: "mbox_conf_softmax"
# top: "mbox_conf_flatten"
# flatten_param {
# axis: 1
# }
# }
# layer {
# name: "detection_out"
# type: "DetectionOutput"
# bottom: "mbox_loc"
# bottom: "mbox_conf_flatten"
# bottom: "mbox_priorbox"
# top: "detection_out"
# include {
# phase: TEST
# }
# detection_output_param {
# num_classes: 6
# share_location: true
# background_label_id: 0
# nms_param {
# nms_threshold: 0.45
# top_k: 10
# }
# code_type: CENTER_SIZE
# keep_top_k: 1
# confidence_threshold: 0.01
# }
# }

















 35
35

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









