






随机梯度下降(SGD) 是一种简单但又非常高效的方法,主要用于凸损失函数下线性分类器的判别式学习,例如(线性) 支持向量机 和 Logistic 回归 。 尽管 SGD 在机器学习社区已经存在了很长时间, 但是最近在 large-scale learning (大规模学习)方面 SGD 获得了相当大的关注。
SGD 已成功应用于在文本分类和自然语言处理中经常遇到的大规模和稀疏的机器学习问题。对于稀疏数据,本模块的分类器可以轻易的处理超过 105 的训练样本和超过 105 的特征。
Stochastic Gradient Descent (随机梯度下降法)的优势:
- 高效。
- 易于实现 (有大量优化代码的机会)。
Stochastic Gradient Descent (随机梯度下降法)的劣势:
- SGD 需要一些超参数,例如 regularization (正则化)参数和 number of iterations (迭代次数)。
- SGD 对 feature scaling (特征缩放)敏感。
class sklearn.linear_model.SGDClassifier(loss='hinge', penalty='l2', alpha=0.0001, l1_ratio=0.15, fit_intercept=True, n_iter=5, shuffle=True, verbose=0, epsilon=0.1, n_jobs=1, random_state=None, learning_rate='optimal', eta0=0.0, power_t=0.5, class_weight=None, warm_start=False, average=False)
loss="hinge": (soft-margin) linear Support Vector Machine ((软-间隔)线性支持向量机),loss="modified_huber": smoothed hinge loss (平滑的 hinge 损失),loss="log": logistic regression (logistic 回归),- and all regression losses below(以及所有的回归损失)。
SGD 支持以下 penalties(惩罚):
loss=”hinge”: (soft-margin) 线性SVM.
loss=”modified_huber”: 带平滑的hinge loss.
loss=”log”: logistic 回归
通过penalty参数,可以设置对应的惩罚项。SGD支持下面的罚项:
penalty=”l2”: 对coef_的L2范数罚项
penalty=”l1”: 对coef_的L1范数罚项
penalty=”elasticnet”: L2和L1的convex组合; (1 - l1_ratio) * L2 + l1_ratio * L1
基于学习的模型调用decision_function之后,获取是[some_digit]所有的标签到超平面的距离.
from sklearn.linear_model import SGDClassifier
X = [[0., 0.], [1., 1.]]
y = [0, 1]
clf = SGDClassifier(loss="hinge", penalty="l2")
clf.fit(X, y)
clf.predict([[2., 2.]])clf.coef_clf.intercept_ clf.decision_function([[2., 2.]]) decision_function代表的是参数实例到各个类所代表的超平面的距离;在梯度下滑里面特有的(随机森林里面没有decision_function),这个返回的距离,或者说是分值。通过decision_function可以获得一种"分值",这个分值的几何意义就是当前点到超平面(hyperplane)的距离
使用 loss="log" 或者 loss="modified_huber" 来启用 predict_proba 方法, 其给出每个样本 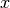 的概率估计
的概率估计 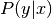 的一个向量:
的一个向量:
clf = SGDClassifier(loss="log").fit(X, y)
clf.predict_proba([[1., 1.]])
多分类
SGDClassifier 通过利用 “one versus all” (OVA)方法来组合多个二分类器,从而实现多分类。对于每一个 K类, 可以训练一个二分类器来区分自身和其他 K-1个类。在测试阶段,我们计算每个分类器的 confidence score(置信度分数)(也就是与超平面的距离),并选择置信度最高的分类。
在 multi-class classification (多类分类)的情况下, coef_ 是 shape=[n_classes, n_features] 的一个二维数组, intercept_ 是 shape=[n_classes] 的一个一维数组。 coef_ 的第 i 行保存了第 i 类的 OVA 分类器的权重向量;类以升序索引 (参照属性 classes_ )。 注意,原则上,由于它们允许创建一个概率模型,所以 loss="log" 和 loss="modified_huber"更适合于 one-vs-all 分类。

















 1981
1981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









