







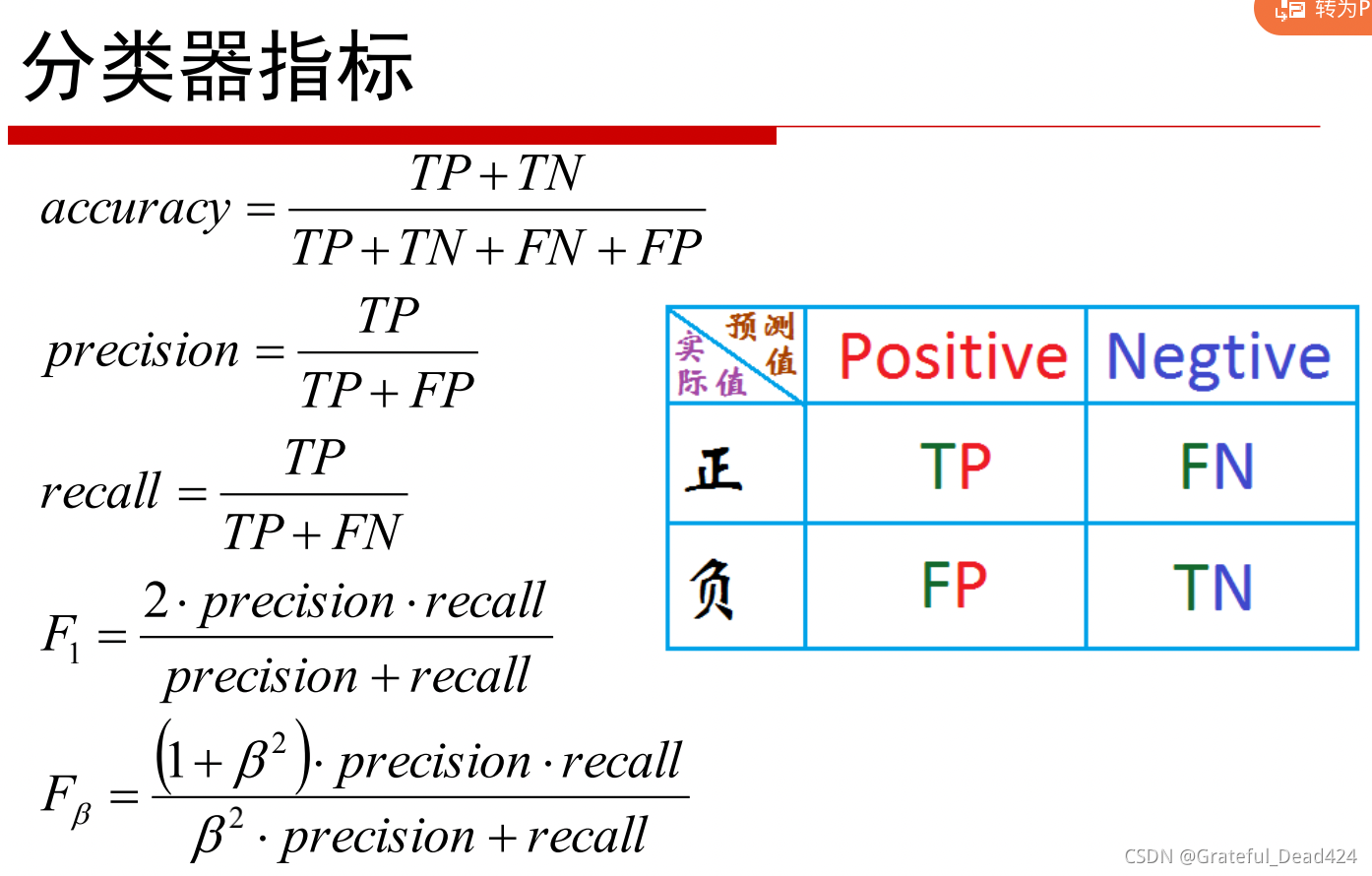
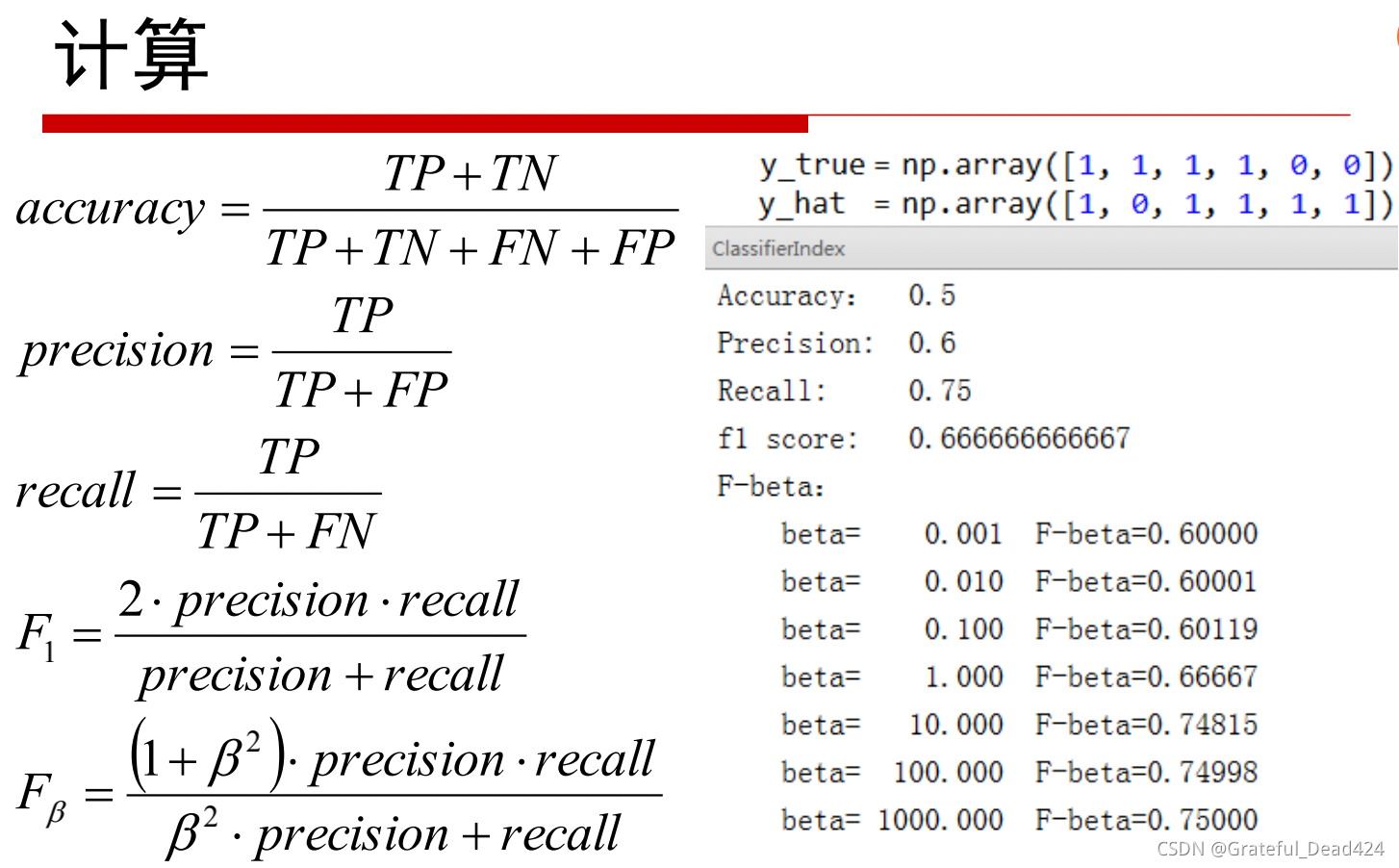

首选——高斯核函数




import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 'sepal length', 'sepal width', 'petal length', 'petal width'
iris_feature = u'花萼长度', u'花萼宽度', u'花瓣长度', u'花瓣宽度'
if __name__ == "__main__":
path = '/Users/zhucan/Desktop/iris.csv' # 数据文件路径
data = pd.read_csv(path, header=None)
x, y = data[range(4)], data[4]
#字符串映射为0,1,2三个类别
y = pd.Categorical(y).codes
x = x[[0, 1]]
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1, train_size=0.6)
# 分类器 SVC classification ovr用若干个二分类得到一个三分类
clf = svm.SVC(C=0.1, kernel='linear', decision_function_shape='ovr')
# clf = svm.SVC(C=0.8, kernel='rbf', gamma=20, decision_function_shape='ovr')
clf.fit(x_train, y_train.ravel())
# 准确率
print(clf.score(x_train, y_train)) # 精度
print('训练集准确率:', accuracy_score(y_train, clf.predict(x_train)))
print(clf.score(x_test, y_test))
print('测试集准确率:', accuracy_score(y_test, clf.predict(x_test)))
# decision_function
print('decision_function:\n', clf.decision_function(x_train))
print('\npredict:\n', clf.predict(x_train))
0.8777777777777778
训练集准确率: 0.8777777777777778
0.7377049180327869
测试集准确率: 0.7377049180327869
到三个分类器的距离
decision_function:
[[ 0.77012025 2.22752333 3.25141611 -0.24994564]
[ 0.72449894 2.2375207 3.27995319 -0.24915267]
[ 3.25675197 2.19909745 0.78766834 -0.25165556]
[ 3.2365702 2.22433941 0.80405863 -0.25157315]
[ 0.82102496 2.23135422 3.21875372 -0.25038056]
[ 3.24340533 2.14809174 0.89650978 -0.25114765]
[ 0.82696908 3.23547716 2.20967506 -0.25046731]
[ 0.77046828 2.18930222 3.26499186 -0.24959236]
[ 1.11964505 3.23028535 2.06731009 -0.25098136]
[ 0.78502606 2.23589281 3.23544913 -0.25020768]]
predict:
[2 2 0 0 2 0 1 2 1 2 2 2 0 1 1 2 1 1 1 0 0 0 1 0 1 2 1 0 0 1 0 2 1 2 2 2 2
2 1 0 1 0 1 2 0 2 0 0 2 2 1 0 0 1 0 2 0 2 2 0 1 0 1 0 1 1 3 0 2 0 1 1 0 1
1 1 0 2 0 0 1 1 2 2 1 2 2 1 2 0] 高斯核——γ高斯分布的精度,γ越大,高斯分布精度越大
高斯核——γ高斯分布的精度,γ越大,高斯分布精度越大
import numpy as np
from sklearn import svm
from sklearn.model_selection import GridSearchCV # 0.17 grid_search
import matplotlib.pyplot as plt
if __name__ == "__main__":
N = 50
np.random.seed(0)
x = np.sort(np.random.uniform(0, 6, N), axis=0)
y = 2*np.sin(x) + 0.1*np.random.randn(N)
x = x.reshape(-1, 1)
print('x =\n', x)
print('y =\n', y)
model = svm.SVR(kernel='rbf')
c_can = np.logspace(-2, 2, 10)
gamma_can = np.logspace(-2, 2, 10)
svr = GridSearchCV(model, param_grid={'C': c_can, 'gamma': gamma_can}, cv=5)
svr.fit(x, y)
print('验证参数:\n', svr.best_params_)x =
[[0.1127388]
[0.12131038]
[0.36135283]
[0.42621635]
[0.5227758 ]
[0.70964656]
[0.77355779]
[0.86011972]
[1.26229537]
[1.58733367]
[1.89257011]
[2.1570474 ]
[2.18226463]]
y =
[ 0.05437325 0.43710367 0.65611482 0.78304981 0.87329469 1.38088042
1.23598022 1.49456731 1.81603293 2.03841677 1.84627139 1.54797796
1.63479377 1.53337832 1.22278185 1.15897721 0.92928812 0.95065638
0.72022281 0.69233817 -0.06030957 -0.23617129 -0.23697659 -0.34160192
-0.69007014 -0.48527812 -1.00538468 -1.00756566 -0.98948253 -1.05661601
-1.17133143 -1.46283398 -1.47415531 -1.61280243 -1.7131299 -1.78692494
-1.85631003 -1.98989791 -2.11462751 -1.90906396 -1.95199287 -2.14681169
-1.77143442 -1.55815674 -1.48840245 -1.35114367 -1.27027958 -1.04875251
-1.00128962 -0.67767925]
验证参数:
{'C': 35.93813663804626, 'gamma': 0.5994842503189409}














 2568
2568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









