







1.了解昇思MindSpore
昇思MindSpore是一个全场景深度学习框架,旨在实现易开发、高效执行、全场景统一部署三大目标。其中,易开发表现为API友好、调试难度低;高效执行包括计算效率、数据预处理效率和分布式训练效率;全场景则指框架同时支持云、边缘以及端侧场景。
昇思MindSpore总体架构如下图所示:
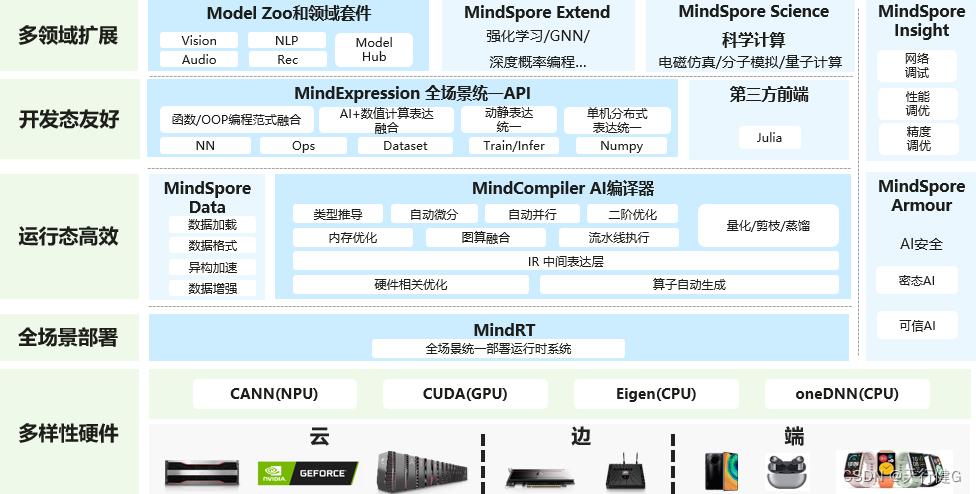
具体介绍可见:MindSpore
2.快速入门
基础知识:了解python,对人工智能有一定了解
2.1 搭建基础环境
平台:MindSpore
2.1.1引入基本类
import mindspore
from mindspore import nn
from mindspore.dataset import vision, transforms
from mindspore.dataset import MnistDataset
2.1.2处理数据集
MindSpore提供基于Pipeline的数据引擎,通过数据集(Dataset)和数据变换(Transforms)实现高效的数据预处理。在本教程中,我们使用Mnist数据集,自动下载完成后,使用mindspore.dataset提供的数据变换进行预处理
下载代码如下:
# Download data from open datasets
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)
数据下载完成后,获
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









