







Semi-supervised Learning
Introduction
监督学习数据集: { ( x r , y ^ r ) } r = 1 R \{(x^r,\hat{y}^r)\}^R_{r=1} {(xr,y^r)}r=1R;即所有数据都有被标记了
半监督学习数据集: { ( x r , y r ) } r = 1 R , { x u } u = R R + U \{(x^r,y^r)\}_{r=1}^R, \{x^u\}_{u=R}^{R+U} {(xr,yr)}r=1R,{xu}u=RR+U;即存在一部分数据未被标记
通常情况下, U > > R U>>R U>>R
半监督学习分为两张情况:
-
T r a n s d u c t i v e l e a r n i n g Transductive\ learning Transductive learning(直推式学习):
未标记数据是测试集数据;即将未标记的测试集数据当作无表情的训练集使用。(仅使用测试集的 f e a t u r e feature feature,适用于测试集已知的情况下) -
I n d u c t i v e l e a r n i n g Inductive\ learning Inductive learning(归纳学习法):
未标记数据不是训练集数据;即训练集存在一部分未标记数据,不将训练集的 f e a t u r e feature feature用于训练。(适用于事先并不知道测试集的情况下,这种情况相比直推式学习)
为什么半监督学习能够起作用?
T h e d i s t r i b u t i o n o f t h e u n l a b e l e d d a t a t e l l u s The\ distribution\ of\ the\ unlabeled\ data\ tell\ us The distribution of the unlabeled data tell us s o m e t h i n g . something. something.
如下图,灰色数据是未标记数据,红色是使用标记数据训练的猫狗分类决策边界;

根据这些未标记的数据,可以假设得到一条更好的决策边界,如下图:

半监督学习的使用都伴随着假设,假设的合理性会决定模型的 p e r f o r m a n c e performance performance。如上图,也行左下角的未标记数据是一只狗,那么这条新的决策边界就不是最好的决策边界。
Semi-supervised Learning for Generative Model
先简单回顾以下 G e n e r a t i v e M o d e l Generative\ Model Generative Model,存在一组属于 C 1 C_1 C1、 C 2 C_2 C2其中一个类别的训练集数据: { x r ∈ C 1 , C 2 } \{x^r∈C_1,C_2\} {xr∈C1,C2};生成模型会根据这组数据计算出 C 1 C_1 C1的分布( m e a n 1 = u 1 , c o v a r i a n c e 1 = Σ mean_1=u^1,covariance_1=Σ mean1=u1,covariance1=Σ)和 C 2 C_2 C2的分布( m e a n 2 = u 2 , c o v a r i a n c e 1 = Σ mean_2=u^2,covariance_1=Σ mean2=u2,covariance1=Σ);
确定了分布之后,就可以算出先验概率 P ( x n e w ∣ C 1 ) P(x_{new}|C_1) P(xnew∣C1)和 P ( x n e w ∣ C 2 ) P(x_{new}|C_2) P(xnew∣C2);使用贝叶斯公式就能算出后验概率 P ( C 1 ∣ x n e w ) P(C_1|x_{new}) P(C1∣xnew)和 P ( C 2 ∣ x n e w ) P(C_2|x_{new}) P(C2∣xnew),即新的样例 x n e w x_{new} xnew是 C 1 C_1 C1或者 C 2 C_2 C2的概率值。
在半监督生成概率模型:
通过已经标记的数据,可以确定数据分布并确定一个决策边界,如下图:
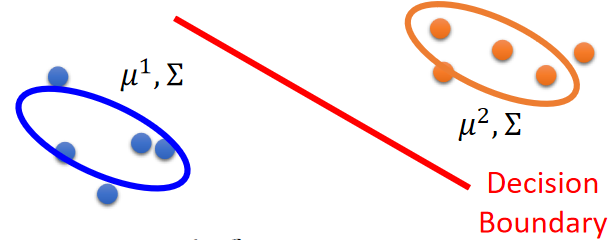
但是考虑了那些未标记的数据,会发现原来的分布并不是比较好的,这时候就会考虑这些未标记的数据,从而去更新原来的数据分布,从而形成一个新的决策边界,如下图:
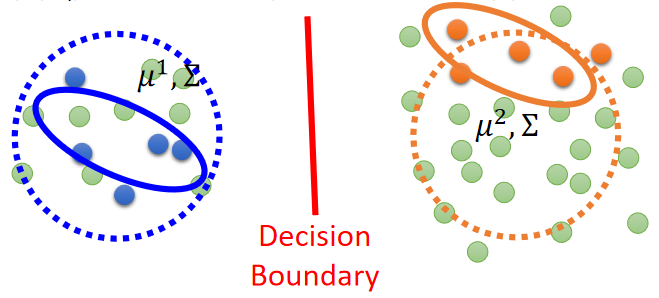
详细步骤如下:
-
初始化参数: θ = P ( C 1 ) , P ( C 2 ) , u 1 , u 2 , Σ θ={P(C_1),P(C_2),u^1,u^2,Σ} θ=P(C1),P(C2),u1,u2,Σ
-
步骤 1 1 1:使用已标记数据计算未标记数据的后验概率: P θ ( C 1 ∣ x u ) P_θ(C_1|x^u) Pθ(C1∣xu)
-
步骤 2 2 2:更新模型
P ( C 1 ) = N 1 + ∑ x u P ( C 1 ∣ x u ) N P(C_1)=\frac{N_1+\sum_{x^u}P(C_1|x^u)}{N} P(C1)=NN1+∑xuP(C1∣xu)
u 1 = 1 N ∑ x r ∈ C 1 x r + 1 ∑ x u P ( C 1 ∣ x u ) ∑ x u P ( C 1 ∣ x u ) x u u^1=\frac{1}{N} \sum_{x^r∈C_1}x^r+\frac{1}{\sum_{x^u}P(C_1|x^u)}\sum_{x^u}P(C_1|x^u)x^u u1=N1xr∈C1∑xr+∑xuP(C1∣xu)1xu∑P(C1∣xu)xu
其余参数同理。得到了一组新的参数 θ θ θ,再回到步骤 1 1 1,重复直到参数 θ θ θ收敛。 -
以上方法是可以收敛的,但一开始的初始化参数 θ θ θ会影响收敛的结果。
我们在考虑未标记数据
x
u
x^u
xu时,会将它看作时可划分的,一部分属于
C
1
C_1
C1,一部分属于
C
2
C_2
C2,所以
P
θ
(
x
u
)
=
P
θ
(
x
u
∣
C
1
)
P
(
C
1
)
+
P
θ
(
x
u
∣
C
2
)
P
(
C
2
)
P_θ(x^u)=P_θ(x^u|C_1)P(C_1)+P_θ(x^u|C_2)P(C_2)
Pθ(xu)=Pθ(xu∣C1)P(C1)+Pθ(xu∣C2)P(C2)
此时 P θ ( x u ) ≠ 1 P_θ(x^u)≠1 Pθ(xu)=1,我们想让 x u x^u xu要么属于 C 1 C_1 C1,要么属于 C 2 C_2 C2;所以希望这个概率值越大越好。
则损失函数从原来的
l
o
g
L
(
θ
)
=
∑
(
x
r
,
y
^
r
)
l
o
g
P
θ
(
x
r
∣
y
^
r
)
logL(θ)=\sum_{(x^r,\hat{y}^r)}logP_θ(x^r|\hat{y}^r)
logL(θ)=(xr,y^r)∑logPθ(xr∣y^r)
变成了
l o g L ( θ ) = ∑ ( x r , y ^ r ) l o g P θ ( x r ∣ y ^ r ) + ∑ x u l o g P θ ( x u ) logL(θ)=\sum_{(x^r,\hat{y}^r)}logP_θ(x^r|\hat{y}^r)+\sum_{x^u}logP_θ(x^u) logL(θ)=(xr,y^r)∑logPθ(xr∣y^r)+xu∑logPθ(xu)
Low-density Separation
接下来介绍一个基于Low-density Separation的半监督学习方法。
L o w − d e n s i t y S e p a r a t i o n Low-density\ Separation Low−density Separation认为这个世界是非黑即白的,即 C 1 C_1 C1和 C 2 C_2 C2分类的交界处数据密度是很低的,中间会存在一条鸿沟,接下来通过未标记数据将存在于鸿沟中的决策边界选出来即可,如下图:
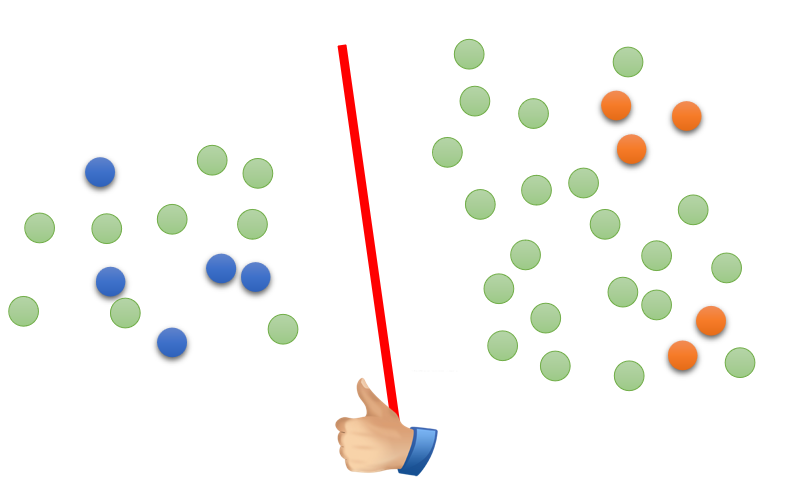
L
o
w
−
d
e
n
s
i
t
y
S
e
p
a
r
a
t
i
o
n
Low-density\ Separation
Low−density Separation的思想就是
S
e
l
f
−
t
r
a
i
n
i
n
g
Self-training
Self−training,步骤如下:
- 步骤 1 1 1:通过已标记数据训练出模型 f ∗ f^* f∗
- 步骤 2 2 2:用模型 f ∗ f^* f∗去标记 u n l a b e l e d d a t a s e t unlabeled\ data\ set unlabeled data set
- 步骤 3 3 3:抽取一部分标记的 u n l a b e l e d d a t a s e t unlabeled\ data\ set unlabeled data set,并将它加入到 l a b e l e d d a t a s e t labeled\ data\ set labeled data set.
- 然后回到步骤再次重复步骤 1 1 1- 3 3 3
这个方法对 R e g r e s s i o n Regression Regression是不管用的, R e g r e s s i o n Regression Regression预测的是一个数值,带回到模型种,对 T o t a l L o s s Total\ Loss Total Loss的贡献值为 0 0 0。
该方法与生成模型比较相似,不同之处在于:
- S e l f − t r a i n i n g Self-training Self−training是 h a r d l a b e l hard\ label hard label:强制性将未标记样本归为某一个类
- G e n e r a t i v e M o d e l Generative\ Model Generative Model用的是 s o f t l a b e l soft\ label soft label:假设一笔数据可以从多个类中进行抽取,即不同部分属于不同的类别。
如,当使用神经网络预测
x
u
x^u
xu的结果为
[
0.7
0.3
]
\begin{bmatrix} 0.7 \\ 0.3 \\ \end{bmatrix}
[0.70.3];
h
a
r
d
l
a
b
e
l
hard\ label
hard label会将其变成
[
1
0
]
\begin{bmatrix} 1 \\ 0 \\ \end{bmatrix}
[10],
s
o
f
t
l
a
b
e
l
soft\ label
soft label之后依然是
[
0.7
0.3
]
\begin{bmatrix} 0.7 \\ 0.3 \\ \end{bmatrix}
[0.70.3]。
可以看到对于神经网络来说 s o f t l a b e l soft\ label soft label的结果是没有用的,原因同上面的 r e g r e s s i o n regression regression。
所以可以看出 l o w d e n s i t y s e p a r a t i o n low\ density\ separation low density separation就是通过强制分类来提升分类效果的方法
Entropy-based Regularization
该方法属于Low-density Separation的进阶版;
假设 y u y^u yu是模型对未标记样本 x u x^u xu的概率分布预测,当预测值集中在某一类上,那么模型的表现是比较好的,如下图:
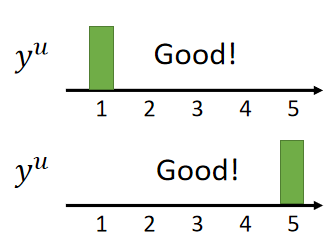
当预测值比较分散时,模型的表现是比较差的,如下图:
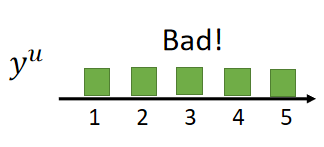
所以我们希望模型预测出来的预测值能够比较集中在某个类上;首先对好坏的评估进行量化,这里采用信息熵来表示:
E
(
y
u
)
=
−
∑
m
=
1
5
y
m
u
l
n
(
y
m
u
)
E(y^u)=-\sum^5_{m=1}y^u_mln(y^u_m)
E(yu)=−m=1∑5ymuln(ymu)
个人觉得这个方法的想法是:
不要对未标记的数据进行摸棱两可的预测,预测出来的结果信息量少一点,能够更加的确定属于这个类
对上图预测结果计算其熵值,如下图;可以看出当 E ( y u ) E(y^u) E(yu)较小时,预测值得分布就会比较集中,模型就会比较好。
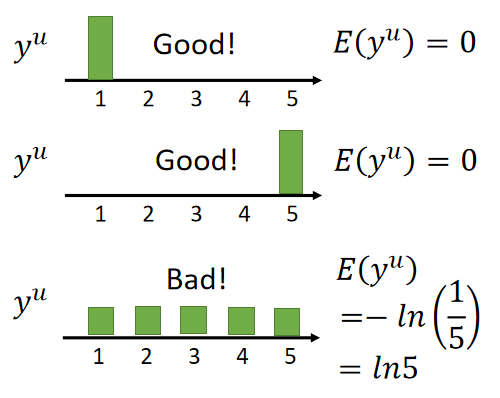
总之我们的目标是在已经标记的数据集上要正确分类,在未标记数据上的预测值能够集中,即
E
(
y
u
)
E(y^u)
E(yu)越小越好。因此在原来的损失函数:
L
=
∑
x
r
C
(
y
r
,
y
^
r
)
L=\sum_{x^r}C(y^r,\hat{y}^r)
L=xr∑C(yr,y^r)
变成:
L = ∑ x r C ( y r , y ^ r ) + λ ∑ x u E ( y u ) L=\sum_{x^r}C(y^r,\hat{y}^r)+λ\sum_{x^u}E(y^u) L=xr∑C(yr,y^r)+λxu∑E(yu)
Smoothness Assumption
这个假设的想法是:近朱者赤,近墨者黑。
这个方法会假设:“相似”的 x x x会有相同的 y ^ \hat{y} y^;即 S m o o t h n e s s A s s u m p t i o n Smoothness\ Assumption Smoothness Assumption假设样本 x x x的分布是不均匀的,如果 x 1 x_1 x1和 x 2 x_2 x2在一个高密度区域很相近的话( x 1 x^1 x1 and x 2 x^2 x2 are close in a high density region),那么 y 1 ^ \hat{y^1} y1^和 y 2 ^ \hat{y^2} y2^是一样的。
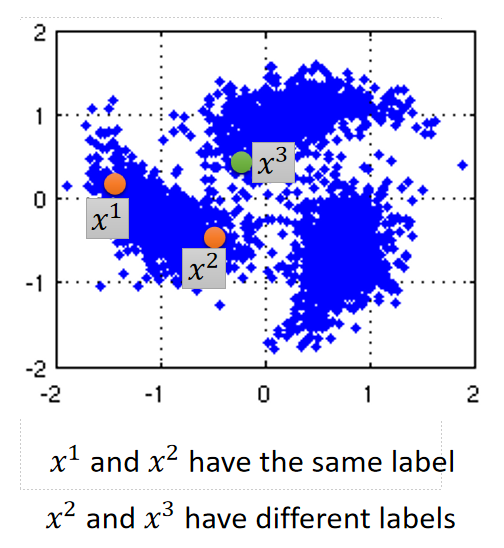
如下图,
x
2
x^2
x2和
x
1
x^1
x1是处于一个高密度区域的,所以它们的预测结果是一样的;而
x
2
x^2
x2和
x
3
x^3
x3虽然比较近,但不属于同一个密度区域,预测值就会不同。
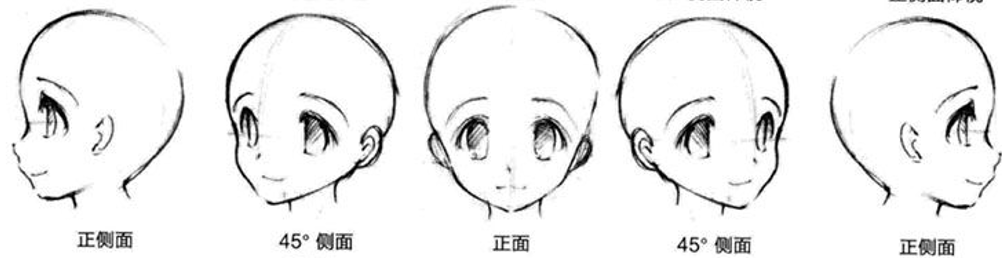
举一个例子,存在两张图片,一张是人的左侧脸,另一张是同一个人的右侧脸,如下图;这两张图片在像素上差别很大,但是预测的结果应该都是属于一个人的。根据距离也许会将这两张图归为不同类。

若数据集中还存在
45
°
45°
45°侧脸、正面,如下图;那么根据Smoothness Assumption的理论,左侧脸和右侧脸就会是比较像的了,认为预测的结果应该是相同的。
Smoothness Assumption在文章分类上比较有效,如存在天文和旅行两类文章,各自有自己的专属词汇;
如果专属词汇之间存在很大的重合,如下图;那么就会比较好去分类。

但是实际情况是这两类文章在很大情况下很难存在重合的词汇,如下图;
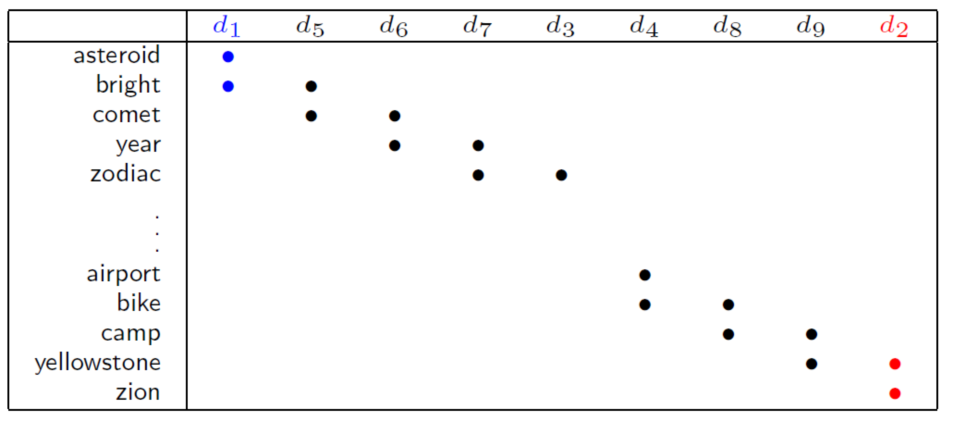
若使用Smoothness Assumption的理论,当无标签数据足够的多时,就会产生一种传递过度的形式,建立文档之间的桥梁。如上图 d 1 、 5 、 6 、 73 d1、5、6、73 d1、5、6、73应该是一类, d 4 、 8 、 9 、 2 d4、8、9、2 d4、8、9、2应该是一类。
实现Smoothness Assumption最简单的方式是Cluster and then Label;即先将样本(有标记样本+无标记样本)分成几个簇( c l u s t e r cluster cluster),然后根据结果簇中有标签样本的数量对未标记样本进行贴标签,然后再进行学习得到新的簇。
当这种方法不一定管用,需要确保同类样本能够分到同一个簇中。对于图像分类来说,如果单纯的使用像素之间的相似度来划分,那么分类的效果会比较差,对此需要设置一个编码网络,将图片转成一组 f e a t u r e s features features,这样聚类会比较有效。
Graph-based Approach
我们也可使用Graph-based Approach来实现Smoothness Assumption,通过图来表达 x 1 x^1 x1、 x 2 x^2 x2处在同一个高密度区域内这件事;即表达 x 1 x^1 x1 and x 2 x^2 x2 are connected by a high density path这件事。
将所有的数据看作点构成一张图,有时候建立数据之间的关系图是比较容易的,如网页之间的跳转转关系、论文之间的引用;但大部分情况下都需自己去寻找数据之间的关系图。
如何建立一张关系图是一件具有探索性的事情,需要我们凭借经验和直觉来做。构建关系图步骤如下:
-
定义两个数据样本 x i 、 x j x^i、x^j xi、xj之间的相似度函数 s ( x i , x j ) s(x^i,x^j) s(xi,xj)。
【对于图片,建议使用编码器将图片转换成一组 f e a t u r e s features features后在进行计算】
可以定义 s ( x i , x j ) = e − γ ∣ ∣ x i − x j ∣ ∣ 2 s(x^i,x^j)=e^{-γ||x^i-x^j||^2} s(xi,xj)=e−γ∣∣xi−xj∣∣2,这里的 x i 、 x j x^i、x^j xi、xj为向量。经验上来说,指数操作是可以提升模型性能的,因为只有当 x i 、 x j x^i、x^j xi、xj比较接近时 s ( x i , x j ) s(x^i,x^j) s(xi,xj)才会比较大;只有距离稍微远一些, s ( x i , x j ) s(x^i,x^j) s(xi,xj)就会迅速下降,变得比较小。 -
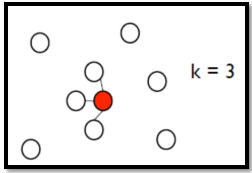
Add edge:
(1)K Nearest Neighbor:与 K K K个最近的数据点相连
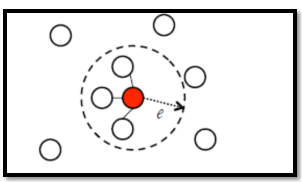
(2)e-Neighborhood:e范围内的点都进行连接
-
此外,还可以为边添加上权重(Edge weight),Edge weight与 s ( x i , x j ) s(x^i,x^j) s(xi,xj)成正比。
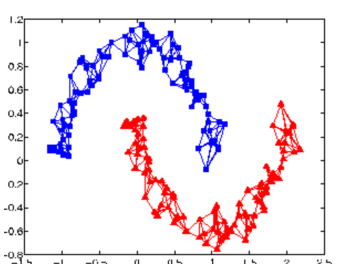
graph-based approach的想法是,关系图中存在着一些标记数据,那么与之相连的未标记数据点属于同一类的概率就会上升;每一个数据点都会影响它的邻居,像流感一样通过edges传播,即使有些点没有与标记数据相连,也会被传播到。
看下图,当关系图构建的比较好的话,红、蓝两类会传递完两张完整的图。
但是数据不够时,传播会中段,信息的传递也就失效了,如下图:
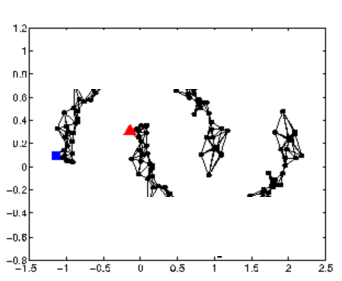
如何评估一个关系图是否符合Smoothness Assumption的理论呢?
在这里我们定义图的smoothness为:
S = 1 2 ∑ i , j w i , j ( y i − y j ) S=\frac{1}{2}\sum_{i,j}w_{i,j}(y^i-y^j) S=21i,j∑wi,j(yi−yj)
- y i 、 y j y^i、y^j yi、yj表示样本标签,可以为伪标签或者真实标签。
- w i , j w_{i,j} wi,j表示 x i 、 x j x^i、x^j xi、xj之间的边的权重
这里希望 S S S越小越好,即不同标签的样本之间的边的权重尽量小一点;具体例子如下图:
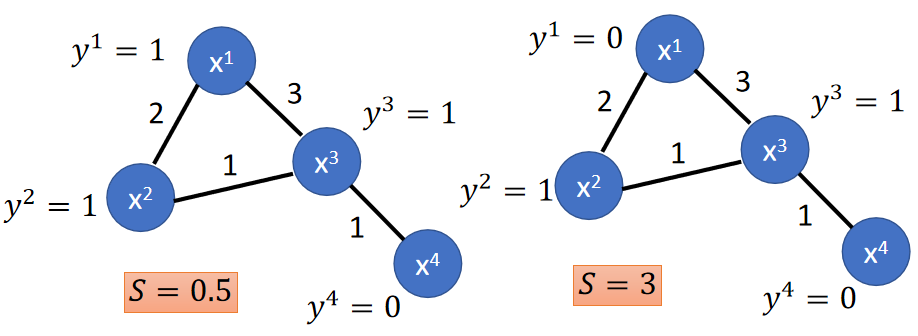
假设W为图矩阵表示方式,矩阵的值表示为权重;假设D为W各行的和并放在对角线上;如下图:
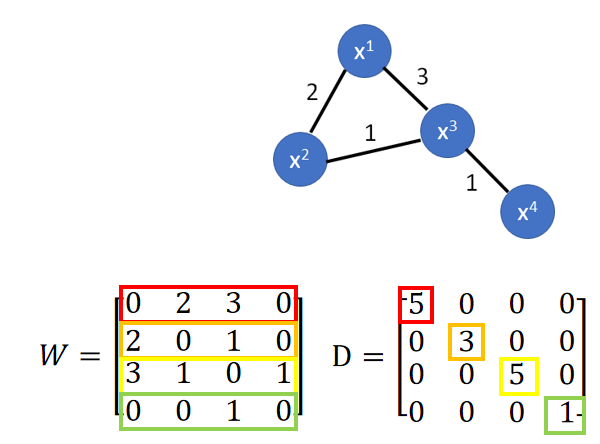
设
L
=
D
−
W
L=D-W
L=D−W,
L
L
L是个(R+U)X(R+U)的矩阵,名字为Graph Laplacian(在图神经网络中有介绍),则:
S
=
1
2
∑
i
,
j
w
i
,
j
(
y
i
−
y
j
)
=
y
T
L
y
S=\frac{1}{2}\sum_{i,j}w_{i,j}(y^i-y^j)=y^TLy
S=21i,j∑wi,j(yi−yj)=yTLy
因此,损失函数从:
L
=
∑
x
r
C
(
y
r
,
y
^
r
)
L=\sum_{x^r}C(y^r,\hat{y}^r)
L=xr∑C(yr,y^r)
变成:
L
=
∑
x
r
C
(
y
r
,
y
^
r
)
+
λ
S
L=\sum_{x^r}C(y^r,\hat{y}^r)+λS
L=xr∑C(yr,y^r)+λS
综上可知我们的训练目标是,已标注的数据交叉熵损失函数要尽可能的小;已标注的数据与未标注数据所训练出来的模型要尽可能的满足Smoothness Assumption。














 2246
2246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









