






【PaddlePaddle论文复现】Temporal Pyramid Network for Action Recognition论文笔记
正参加百度AI studio的论文复现课程
https://aistudio.baidu.com/aistudio/education/group/info/1340
Abstract
视觉节奏表征了动作的动态和时间尺度。本文提出了一种通用的时间金字塔网络(TPN),该网络以即插即用的方式灵活地集成到2D或3D主干网络中。TPN的两个基本组件,特征源和特征融合,形成了主干的特征层次结构,因此它可以捕获各种速度的动作实例。
Introduction
![[外链图片转存失败,源站可能有防盗在即使是这里插入!链机保存下来直接上描述]qhttps://9hblog.csdnimg.cn/202008051T2207588.png?x-1ssprocess=image/watermark,type_ZmFuZ3poZW96naGVpdGk,shadow_10,text_aHR0cHM5Ly9ibG9nLmNzZG4ubmV0L0hDX3dvb7Q=,size_11,color_FFFFFF,t_8)tp即使是s://img-blog.csdnimg.cn/20200805192207588.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0hDX3dvb2Q=,size_16,color_FFFFFF,t_70)]](https://i-blog.csdnimg.cn/blog_migrate/9be97c03755481a828cb9e506dc4ed67.png)
当执行相同的动作时,由于年龄,情绪和精力水平等各种因素,每个演员可以按自己的视觉节奏来做动作。例如,老人的运动往往比年轻人慢,具有较重体重的人也是如此。对动作实例的视觉节奏中的类内和类间差异进行精确建模,可能会显著改善动作识别准确度。
Related Work
与本文思想相似的是Facebook 提出的SlowFast网络,本文认为虽然该网络在建模时候,考虑了视觉上速度的差异,但输入是固定的,只能是4/32帧,同时计算花费依旧比较大。
Temporal Pyramid Network
本文启发于在一个深度网络中,不同深度的输出特征已经涵盖了各种视觉速度。如特征维度T=32, 16, 8, 4的变化,也就是对应着不同间隔的采样帧。这样的话就可以运用网络本身,而不需要建立额外的分支去计算。基于此, TPN提出,其由两个重要的部分组成,特征来源, 特征聚合。
第一种方法想法很简单,直接规定网络某一层的输出为我们想要的特征。随后直接在帧取样上做文章:

TPN的框架:主干网络提取多个层次的特征。空间语义调制在空间上下采样特征以对齐语义。时间速率调制在时间上下采样特征来调整各个层次之间的相对速度。信息流在各个方向上聚合特征来加强和丰富层次的表示。最终预测重新缩放并连接了沿通道维度的所有金字塔等级。为简洁起见,省略了最终预测中的通道维度和对应的操作。
Feature Source of TPN
- 单深度金字塔:一种在某个深度选择大小为CxTxWxH的特征Fbase的简单方法,并且以M个不同的速率{r1, …, rM; r1 < r2 < … < rM} 在时间维度上采样。我们将这种TPN称为由大小为{C x T/r1 x W x H, …, C x T/rM x W x H}的{Fbase(1), …, Fbase(M)}组成的单深度金字塔。以这种方式收集的特征可以减轻融合的工作量,因为它们除时间维度外,都有相同的形状。但是,由于它们仅以单个时间粒度表示视频语义,可能在有效性上受限。
- 多深度金字塔: 一种更好的方法是随着深度的增加收集M个特征集,这使得TPN由大小为{C1 x T1 x W1 x H1, …, CM x TM x WM x HM} 的 {F1, F2, …, FM}组成,特征的维度通常满足{Ci1 >= Ci2, Wi1 >= Wi2, Hi1 >= Hi2; i1 < i2}。这种多深度金字塔在空间维度上含有更丰富的语义,但在特征融合中也需要仔细处理,以确保特征间的正确信息流。

Information Flow of TPN
按照上一节的要求收集并预处理了特征的层次结构后,使它们在视觉节奏上是动态的,并在空间语义上是一致的。让Fi’为第i层的聚合特征,通常有三个基本选择:

Implementation
由于inflated ResNet在各个数据集上出色的性能[1],我们将其作为3D主干网络,同时使用原始的ResNet[12]作为我们的2D主干网络。我们使用res2, res3, res4, res5的输出特征来构造TPN,与输入帧相比,它们在空间上分别下采样4, 8, 16和32倍。在空间语义调制中,M级TPN中处理第i层特征的M维卷积将使特征维数减小或增加到1024.此外,对每个特征的时间速率调制是通过一个卷积层和一个最大池化层实现的。最后,在通过上一节描述的5个流中的1个进行特征聚合后,TPN的特征将通过最大池化操作单独重新缩放,并将连接的特征输入到一个全连接层来实现最终的预测。TPN也可以与主干网络以端到端的方式联合训练。

Experiments

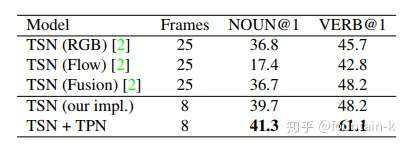
Conclusion
本文的特点是整合不同的层次的信息,其次引入中间层约束,更强的监督。最后信息流的流动,进行特征的融合,这种方式与LGD也有一定的相似性。
参考
https://zhuanlan.zhihu.com/p/127366929
https://blog.csdn.net/YoJayC/article/details/106989570















 1217
1217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









