







 本文介绍了Cheney算法与广度优先搜索(BFS)之间的联系,通过倒酒问题展示了BFS在解决实际问题中的应用。通过状态转移函数,将倒酒问题转化为图的遍历问题,利用BFS找到达到目标状态的最少操作次数。文章还探讨了如何记录状态变化和构建状态转移图,以及在实现过程中遇到的挑战和解决方案。
本文介绍了Cheney算法与广度优先搜索(BFS)之间的联系,通过倒酒问题展示了BFS在解决实际问题中的应用。通过状态转移函数,将倒酒问题转化为图的遍历问题,利用BFS找到达到目标状态的最少操作次数。文章还探讨了如何记录状态变化和构建状态转移图,以及在实现过程中遇到的挑战和解决方案。
转载请注明: http://blog.csdn.net/HEL_WOR/article/details/50446567
写JVM的垃圾回收的时候,提到了Minor GC时用到的Cheney算法。
在莫枢的回答里有一份他写的Chenny算法的实现,有兴趣的话可以直接进去看,不过他把算法放在了Gist上。Chenny算法和BFS很相似。如果先去读读《算法(第四版)》上BFS算法实现那节,就很容易看出Cheney在处理Survive From区对象Copy到Suevive To区和算法第4版上输出起始节点A到目标节点B的路径有多相似了。
不同之处:其一是Cheney算法中起始节点变成了多个(对应使用根遍历来搜索Active对象的多个根),其二是Chenny算法中对每一个遍历到的子节点的处理是将其复制到To区,并把父节点指向了复制到To区的对象。而在算法第四版上是对每一个遍历到的子节点记录其父节点地址或值以找到起始节点到目标节点的路径。
用图片来描述会好理解好多:
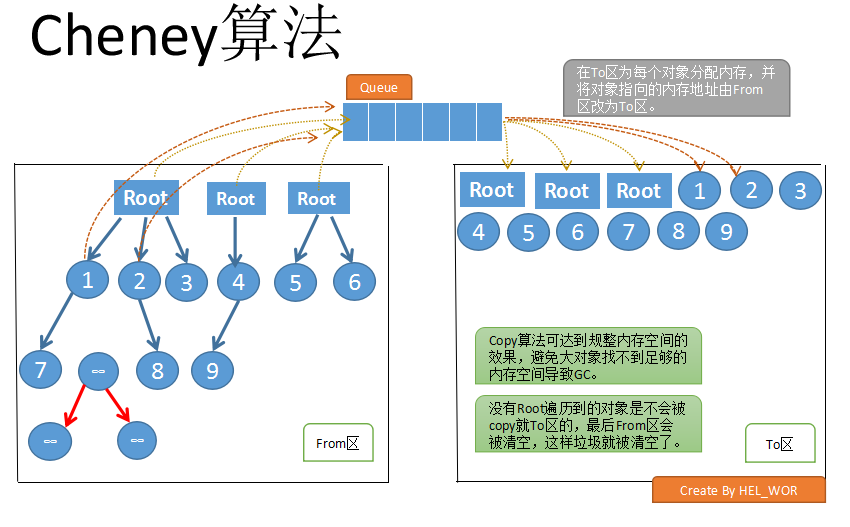
在画这张图的时候,我想起了消息队列,BFS算法使用到队列的作用就像是我们解决输入输出处理速度相差太大而引入的消息队列,在遍历到每一个根节点的子节点时都将这个子节点加入到队列,而每次从队列中取出的对象都做一次引用处理。队列的使用保证了先来先处理,但又不会导致先处理某个对象导致后来出现的对象丢失。
BFS算法的核心部分不是它的使用需要你提供什么条件,而是算法本身定义了一个遍历顺序,核心就是那段入队列和出队列的结构,队列的使用保证了你从顶向下的处理都是按照处理完第一层再处理下一层的顺序,不同的功能需求如处理引用关系(Cheney算法)和输出从A到B路径,都是在这个遍历顺序上实现的。
倒酒问题:
一个8L杯子装满了酒,有一个一个3L空杯子和一个5L空杯子,问怎样才能用最少的次数倒出4L的酒。(不能倒掉)
BFS算法本身就会保证第一次遇到目标节点就会结束搜索,这个功能是通过从上之下,从左至右依次遍历完成的。保证最少到达目标节点时从根节点到目标节点路径上的节点数是最少的;类似在地图上找从城市A到城市B的最少转乘路线。
倒酒问题就是三水杯问题的一个翻版。
可能对我来说最大的难度就是
- 如何把这3个杯子里的酒量所表示的状态和状态的改变抽象为一幅图。
- 状态的改变要满足那几个条件才算成功。
对第一个问题,现在3个水杯已有的状态是800,已经有一个点了,从这个点出发,每次状态的改变都会产生一个新的点xxx,那么这次状态的改变就可以作为连接800到xxx得边。现在就又回到了第二个问题:如何用函数定义一次状态的改变。
考虑两个数组,一个数组中保存的现有的状态avail[],另一个数组中保存的是每个杯子还剩余多少空间可以倒入酒need[]。
倒酒的几个限制条件:1,倒酒放的杯子里必须还有余量。
2,被倒入酒方的杯子不能是满的。
3,因为现在酒的总量是8,而3个杯子的最大容量分别是8,3,5;要构造出某个杯子中酒量为4的情况,因为8 = 3 + 5;如果每次杯子都被装满,我们是不能得到目的值4的,因此必须打破这种情况,也就是说倒酒方的avail不能和被倒酒方的need相等。
4,每次倒完酒只会有两种情况,倒酒方杯子空或者被倒酒方杯子满。所以当avail大于need时,该如何处理;当avail小于need时,又该如何处理。
5,状态不能回退,比如不能出现800->530->800的情况。
把这5个限制条件用代码描述出来,状态转移函数也就完成了。
package BFS;
import java.util.*;
public class StateTransfer {
/// <summary>
/// 每个杯子的现有酒量
/// </summary>
private static int[] avail;
/// <summary>
/// 每个杯子的现有酒量
/// </summary>
private static int[] availTemp;
/// <summary>
/// 每个杯子的还可装入的酒量
/// </summary>
private static int[] need;
/// <summary> 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2656
2656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









