







GUI Action Narrator: Where and When Did That Action Take
前言
一篇GUI操作benchmark的工作,作者提出了一个GUI benchmark以及一个提高MLLM GUI操作能力的框架,在一定程度了提高了开源和闭源MLLM的GUI的性能。文章出发点比较有趣,但是逻辑上有点不自洽,不过整个工作的方向确实是当前的主流,值得深入去思考。
| Paper | https://arxiv.org/pdf/2406.13719 |
|---|---|
| HomePage | https://showlab.github.io/GUI-Narrator |
Abstract
多模态LLMs的出现为自动化GUI任务带来了可能。构建GUI自动化系统的一个基本方面是理解原始GUI操作,它可以让智能体学习人类的操作,因此至关重要。为了评估这种能力,本文设计了视频caption benchmark,包括4189个样本。该任务与传统的自然场景caption不同在于:
- GUI截图包含更密集的信息。
- GUIs中的事件瞬息万变,需要关注时间跨度和空间范围以准确理解。
为此,作者提出GUI动作数据集Act2Cap以及一个简单高效的框架 GUI Narrator,它利用光标作为视觉提示来提升高分辨率截图的理解。具体来说,光标探测器在数据集上训练,通过具有选择关键帧、关键区域机制的多模态LLM生成caption。即使对于最先进的多模态模型如GPT-4o来说仍具有挑战性。此外,评估显示,本文的策略有效增强了模型的性能,无论是对于开源还是闭源的模型。
Motivation
GUI自动化至关重要,现有的工作要不关注于理解学习GUI grounding能力,要不关注于构建生成行为的AI智能体,这些工作都缺少考虑了一个重要问题:理解截图记录中特定的GUI动作。理解GUI动作可以:
- 复制人类的行为。
- 提供用户与应用交互的见解。
虽然现实场景的行为理解已经取得巨大成功,但是GUI领域却远远落后,这是因为:
- GUI 截图信息更密集。
- 动作微妙且响应快,需要精密捕捉。
- 精确定位至关重要。
基于上面的motivation,构建GUI视频caption benchmark就显得十分必要了。
Solution

作者构建了一个GUI视频caption benchmark名为Act2Cap,包含4189个样本,如上图所示。对于数据集中的每个video:
- 每个GUI动作单独记录,如左点击,右点击,双击等,适配各种平台。
- 模型测评时除了识别执行类型,还必须识别具体的元素。
- 数据集中3152个自动捕获的GUI动作视频,以及1037个人工标注的视频。
为了解决GUI视频captioning的问题,作者设计了一个简单高效的框架GUI Narrator,把光标作为视觉prompt,并且训练一个轻量级的检测模型用于定位光标的位置。该模型然后利用定位的光标来识别关键帧。最后利用一个多模态LLM对这些关键帧生成caption。
Act2Cap
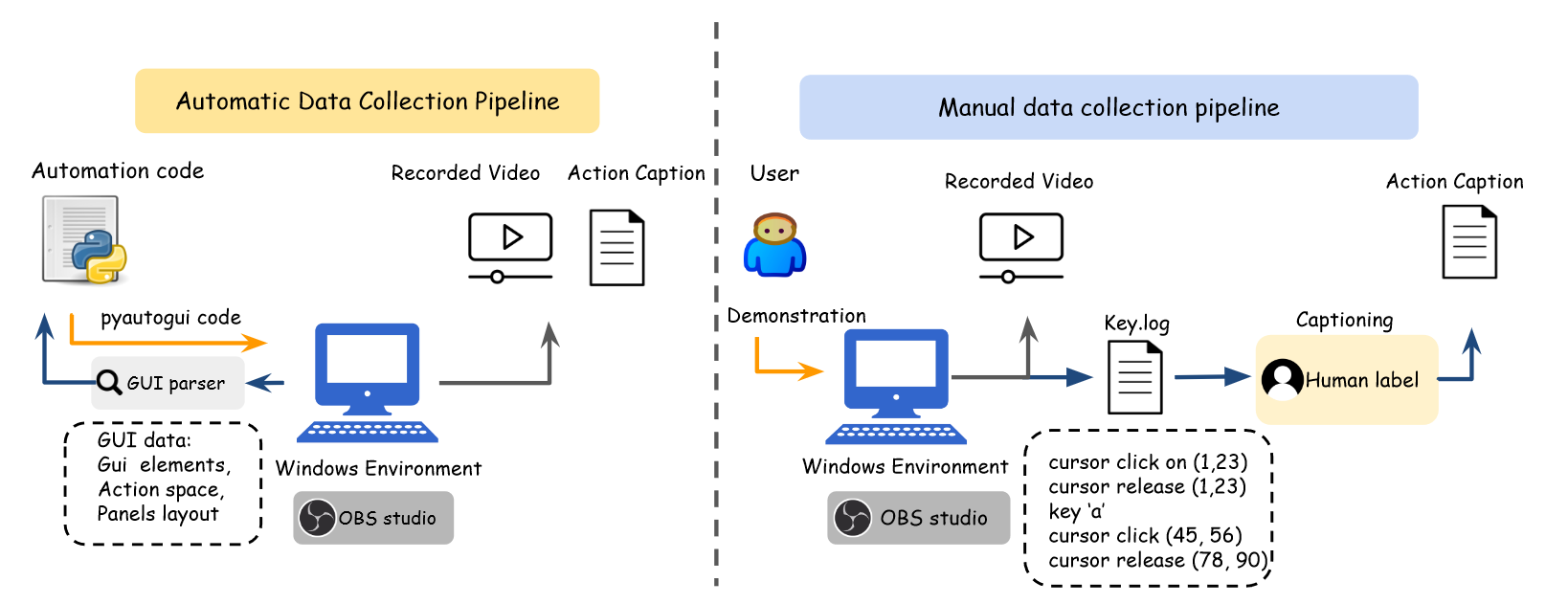
**输入:**全分辨率屏幕截图录像,引导MLLM生成相应caption的提示。
**输出:**自然语言caption。
Data Collection
GUI Narrator包括两种收集数据的pipeline:
- 自动化action视频和标注收集。
- 人类演示方法收集。
相应的caption标注为:
- 基于预定义好的动作空间 。
- 标注人员根据截图对动作进行标注。
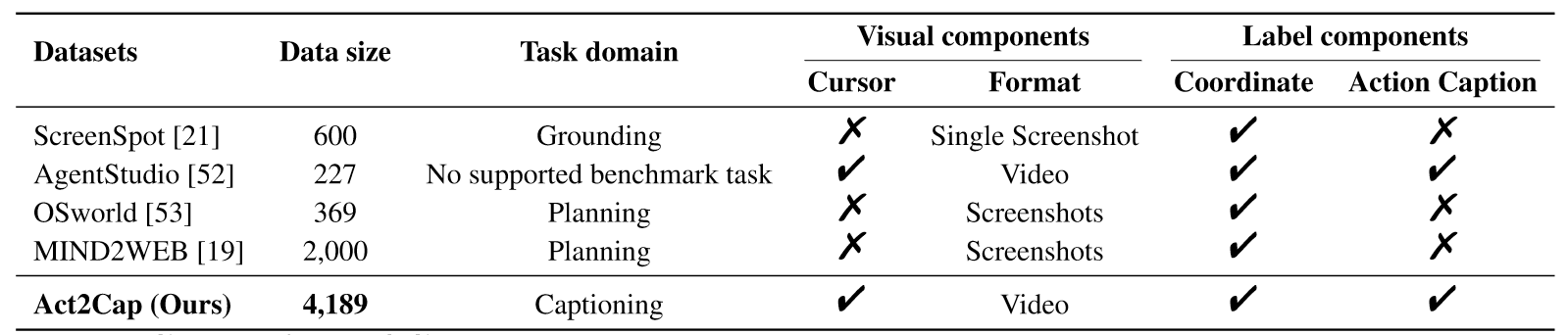
上图是Act2Cap与其他数据集的比较,其在规模和组件上更完整。
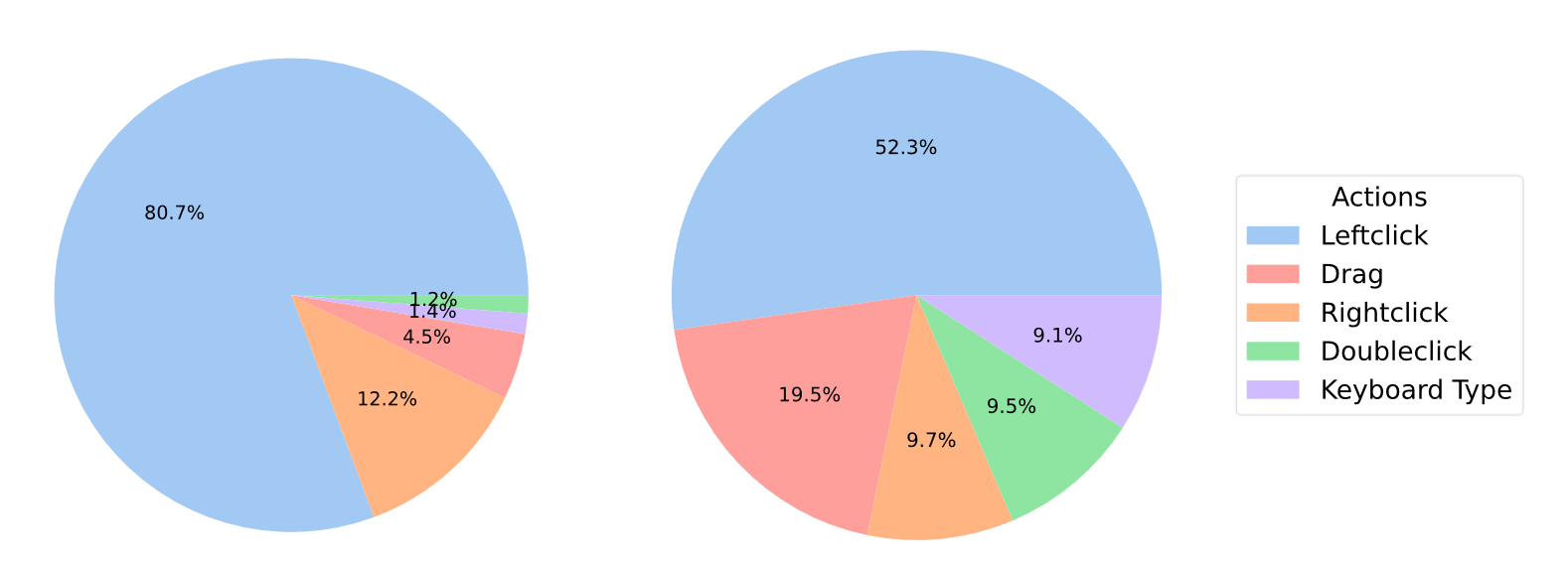
上图是训练集和测试集的分布,其中训练集包括3152个自动标注的数据和488个高质量人工标注数据。此外,作者选取了549个无重叠人工标注数据作为测试集,包括一些OOD的数据。
Metrics
鉴于文本匹配的方式难以捕获语义信息,作者使用GPT-4作为评估器,从叙述中提取关键元素,然后评估每个元素是否匹配语义含义。操作类型被分为三类:点击,拖拽和键盘输入。

Method
本文提出两阶段的基准方法,用于GUI中原子步骤的描述,如下图所示:
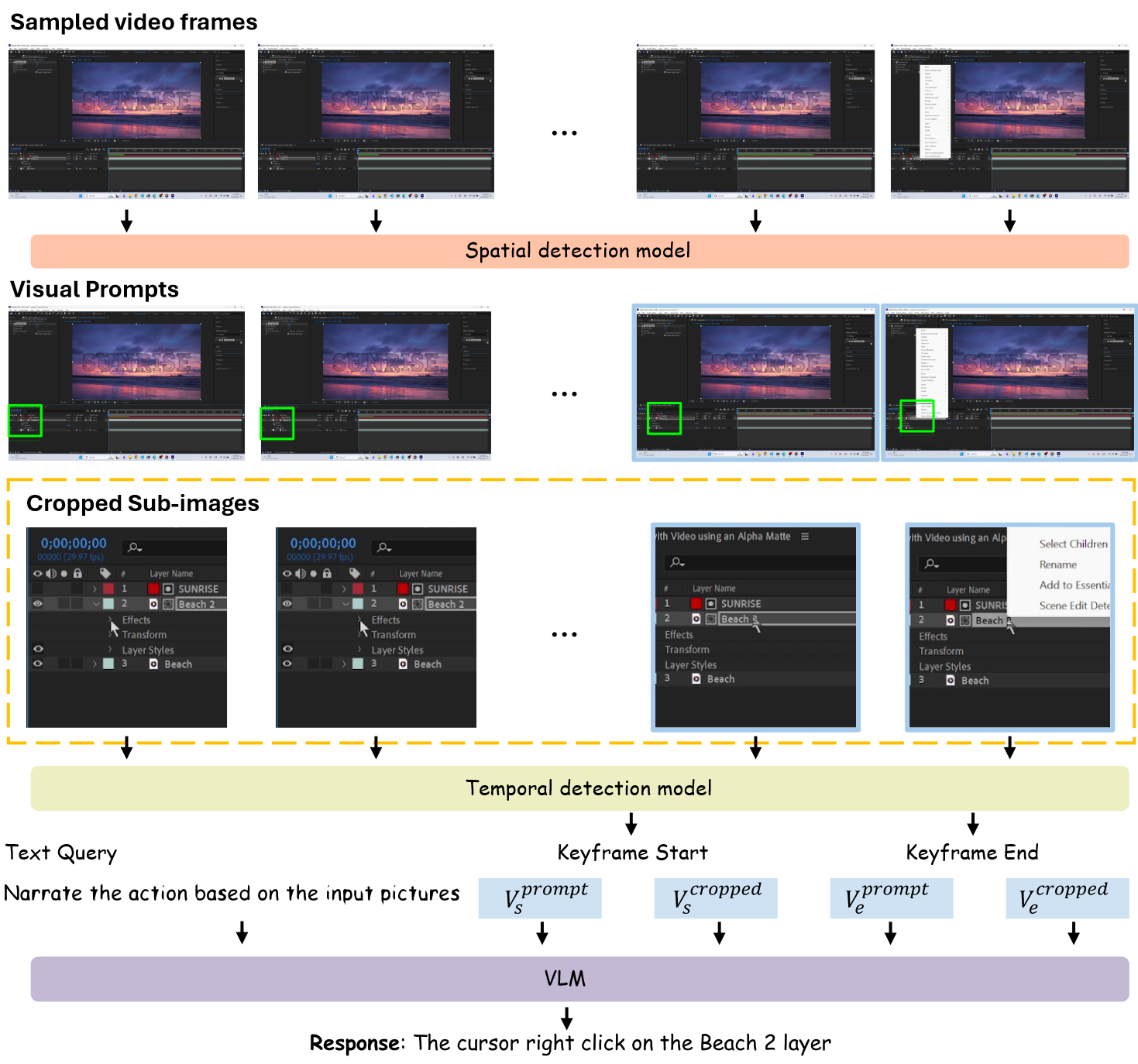
第一阶段:
- 随机抽取视频的10个帧。
- 训练好的光标定位器检测每个帧中的光标。
- 时间检测模型抽取关键帧(before & after)。
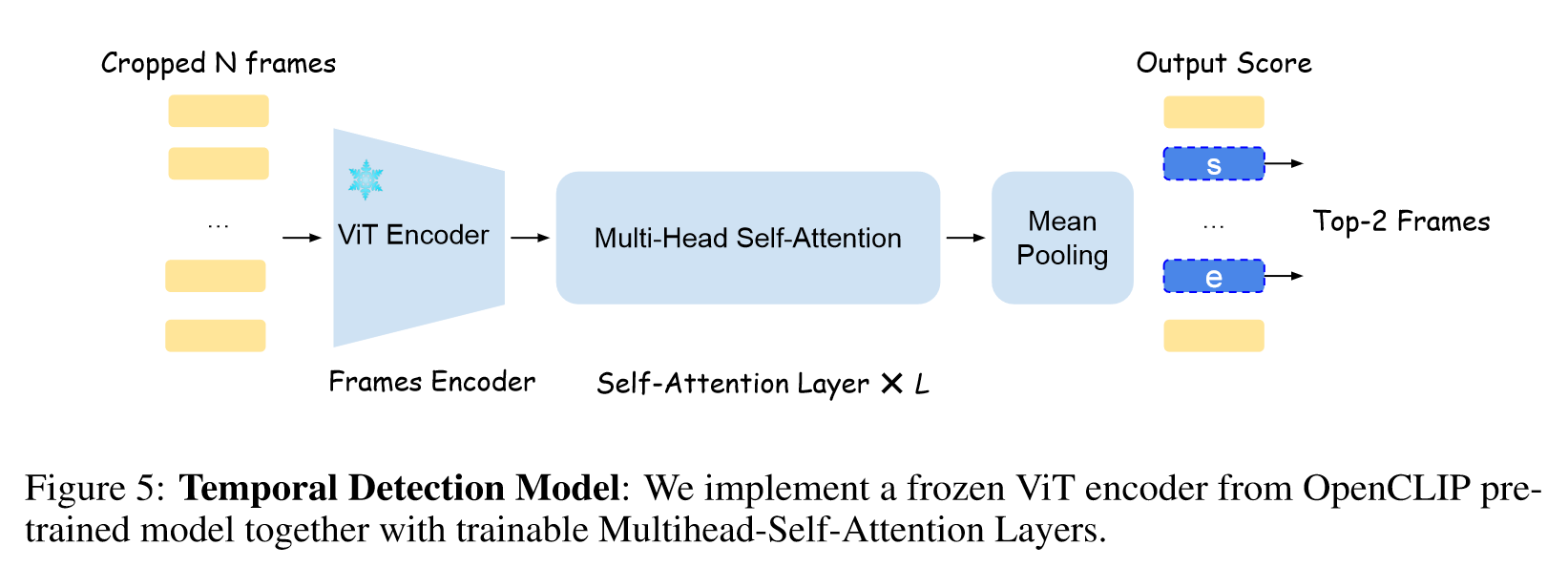
第二阶段:
- 将两个关键帧以及对应的视觉提示注释和裁剪的区域图像作为模型的视觉输入。
- 输出得到包含动作类型、元素、目的的动作叙述。
Experiment
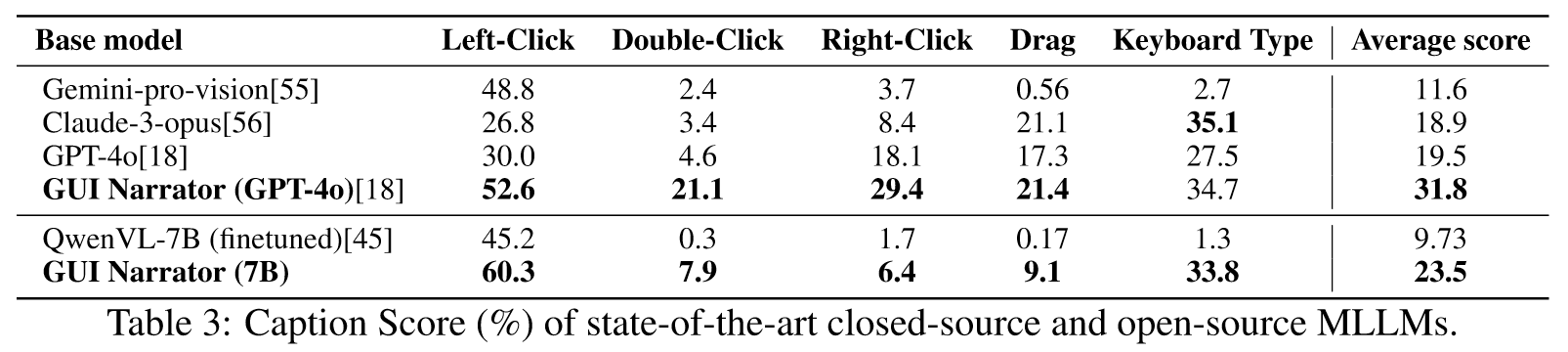
GPT-4o效果最好,并且左击效果显著,但是右击和双击表现很差,本文提出的GUI Narrator在平均分上超过了GPT-o,尽管训练后的模型在左击和键盘输入上表现更好,但是在处理双击、右击和拖拽方面存在困难。
Ablation Study
Visual Prompt Size

最好的Visual Prompt大小为256,该大小越小模型越能生成元素的准确描述,但是限制了图像中感兴趣的区域。
Spatial Prompt

结果证明了Visual Prompt的有效性。
Temporal Prompt
为了验证关键帧的有效性,设计了两个变体,一种使用视频第一帧和最后一帧作为关键帧,另一种使用ground truth作为关键帧。

结果证明了关键帧检测模型只有微小的提升,并且受限于操作方式,一些操作来说可能会降低精度。
Conclusion
本文提出了一个包含4189个数据的GUI Video Caption benchmark,解决了当前GUIs上的不同于现实场景图像的挑战。此外,本文设计了新的框架,利用光标作为视觉提示来增强截图的解释。尽管任务复杂,GUI Narrator还是有效提高了性能,无论是开源还是闭源的模型都适用。最后,作者分析了当前工作的一些局限性,比如对真实场景数据的适应(提供的数据都是剪辑过的),受到两阶段的局限性,GUI Narrator性能取决于光标定位和关键帧提取的准确性。
这篇工作出发点很有趣,不像别的工作上来就从GUI的grounding、GUI的knowledge和planning角度出发,而是从GUI的行为理解和现实场景的行为理解出发,来说明GUI场景行为理解的特异性,进而说明GUI场景需要构建基于视频的GUI benchmark。但是这样的motivation会带来一个问题,视频确实很重要,但是做法怎么又回归到截图了呢?既然说明了GUI场景快、精细、密集,但最后的解决方案还是抽取关键帧,有点不合理。抛开这些,作者构建数据的方式按照作者的故事来说没什么问题(简单的自动化,困难的人工标注),后面提到的提高GUI场景智能体action能力的方案有点意思,但是我有如下的疑问:
- 为什么不先检测关键帧再构建相关的Vision Prompt?感觉这并不冲突反而更能提高效率?
- 随机截取10帧合理吗?能不能一开始就定位好关键帧?
- 自然语言引导图片真的合理吗,VLM实现了自然语言和图片位置对齐吗?
- 训练VLM进行Action Captioning的细节没有描述清楚,突然提出的参数θ和k具体指代什么?
- 关键帧提取的效果不够好,是随机截取10帧的影响还是本身就是不够好呢?
- 数据规模较小,不足以支撑构建一个GUI的 foundational 智能体。
















 1459
1459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











