







本文是关于综述论文《Video Understanding with Large Language Models: A Survey》的部分介绍。文章调研了将视频理解和大语言模型结合的最新技术,从任务、方法、评价、应用等方面对视频大语言模型进行介绍。本文写于2024年4月。
有关本专栏的更多内容,请参考大语言模型论文调研专栏目录
目录
文章链接:https://arxiv.org/pdf/2312.17432.pdf
作者维护了一个网站用于更新最新的视频大模型技术:https://github.com/yunlong10/Awesome-LLMs-for-Video-Understanding
文章引用:
@article{tang2023video,
title={Video understanding with large language models: A survey},
author={Tang, Yunlong and Bi, Jing and Xu, Siting and Song, Luchuan and Liang, Susan and Wang, Teng and Zhang, Daoan and An, Jie and Lin, Jingyang and Zhu, Rongyi and others},
journal={arXiv preprint arXiv:2312.17432},
year={2023}
}
1. 视频理解的历史
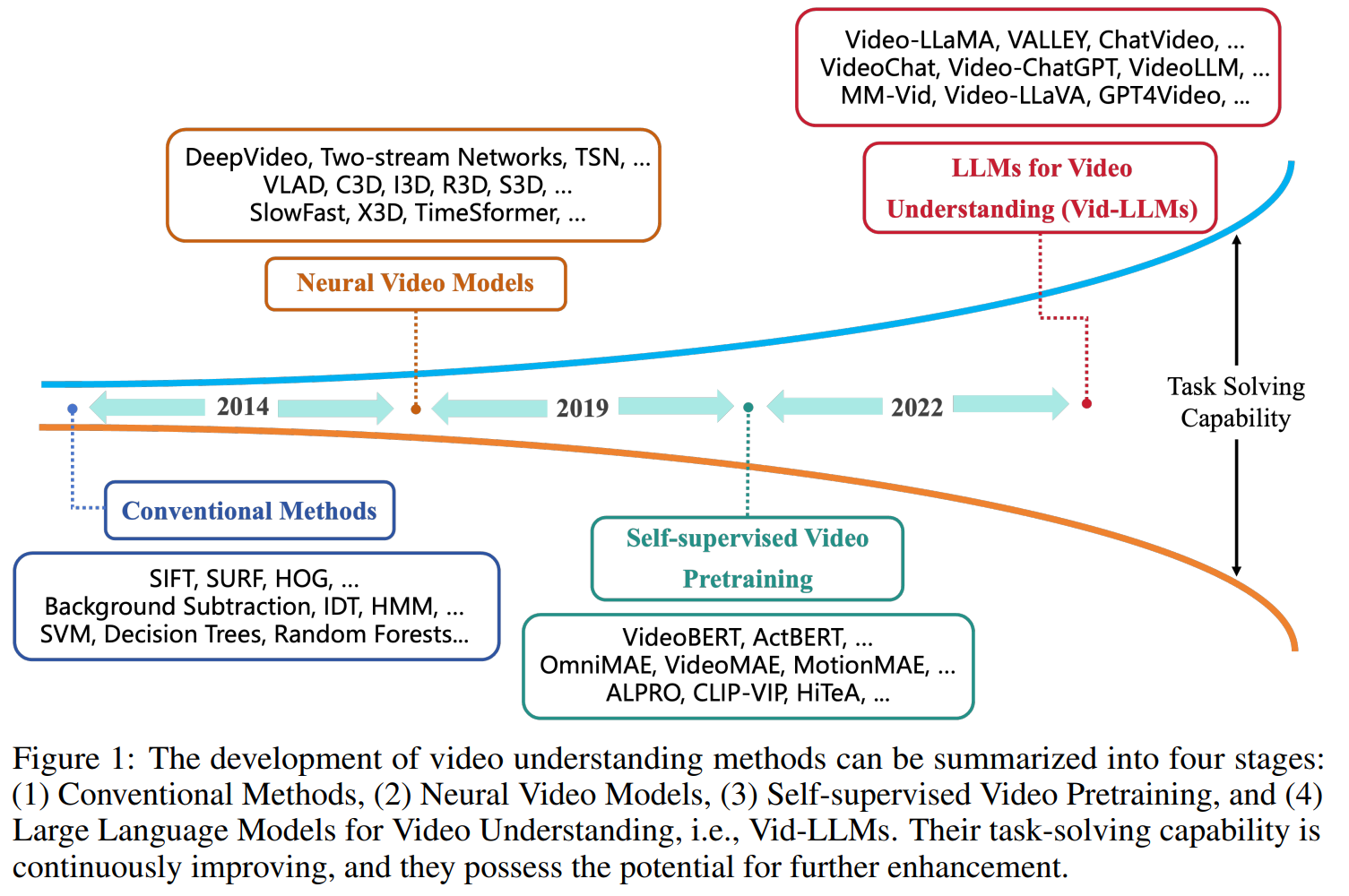
1.1 传统方式的视频理解
在视频理解的早期阶段,手工特征提取技术如尺度不变特征变换(SIFT)、加速稳健特征(SURF)和方向梯度直方图(HOG)被用于捕获视频中的关键信息。背景减除、光流方法和改进的稠密轨迹(IDT)被用于建模运动信息以进行跟踪。由于视频可以被视为时间序列数据,时间序列分析技术如隐马尔可夫模型(HMM)也被用于理解视频内容。在深度学习流行之前,基本的机器学习算法如支持向量机(SVM)、决策树和随机森林也被用于视频分类和识别任务。聚类分析用于分类视频段,或者主成分分析用于数据降维也是常用的视频分析方法。
1.2 基于人工神经网络的视频理解
与传统方法相比,深度学习方法在视频理解方面具有更强大的任务解决能力。DeepVideo是最早引入深度神经网络,特别是卷积神经网络(CNN),用于视频理解的方法。然而,由于未充分利用运动信息,其性能并不优于最佳手工特征方法。双流网络将CNN和IDT结合起来,以捕获运动信息以改善性能,验证了深度神经网络在视频理解方面的能力。为了处理长视频理解,采用了长短期记忆(LSTM)。时间段网络(TSN)也是为了长视频理解而设计,通过分析单独的视频段然后对它们进行聚合。基于TSN,引入了Fisher向量编码、双线性编码和局部聚合描述符向量编码。这些方法提高了在UCF-101和HMDB51数据集上的性能。不同于双流网络,3D网络通过引入3D CNN到视频理解(C3D)另起炉灶。膨胀的3D卷积网络(I3D)利用了2D CNN,即Inception的初始化和架构,在UCF-101和HMDB51数据集上取得了巨大的改进。随后,人们开始使用Kinetics-400(K-400)和Something-Something数据集评估模型在更具挑战性场景中的性能。ResNet、ResNeXt和SENet也从2D适应到3D,导致了R3D、MFNet和STC的出现。为了提高效率,在各种研究中,3D网络已经分解成2D和1D网络。LTC、T3D、Non-local和V4D专注于长视频的时间建模,而CSN、SlowFast和X3D倾向于实现高效率。视觉Transformer的引入推动了一系列杰出的模型的发展。
1.3 自监督视频预训练
自监督预训练模型在视频理解中的可迁移性使它们能够在各种任务之间进行泛化,减少额外标注需求,从而克服了早期深度学习模型对大量任务特定数据的需求。VideoBERT是对视频进行预训练的早期尝试。基于双向语言模型BERT,相关任务被设计用于从视频文本数据中进行自监督学习。它使用层次K均值对视频特征进行标记。预训练模型可以微调以处理多个下游任务,包括动作分类和视频字幕生成。遵循“预训练”和“微调”的范式,涌现了大量关于视频理解预训练模型的研究,特别是视频-语言模型。它们要么使用不同的架构(ActBERT、SpatiotemporalMAE、OmniMAE、VideoMAE、MotionMAE),要么采用不同的预训练和微调策略(MaskFeat、VLM、ALPRO、All-in-One transformer、maskViT、CLIP-ViP、Singularity、LF-VILA、EMCL、HiTeA、CHAMPAGNE)。
1.4 使用大语言模型进行视频理解
近年来,大型语言模型(LLMs)发展迅速。在广泛数据集上预训练的大型语言模型的出现引入了一种新的上下文学习能力。这使它们能够使用提示来处理各种任务,而无需进行微调。ChatGPT是建立在这一基础上的第一个突破性应用。包括生成代码、调用其他模型的工具或API等能力。许多研究正在探索使用像ChatGPT这样的LLMs调用视觉模型API来解决计算机视觉领域的问题,包括Visual-ChatGPT。指导调整的出现进一步增强了这些模型对用户请求的有效响应能力和执行特定任务的能力。集成了视频理解能力的LLMs提供了更复杂的多模态理解优势,使它们能够处理和解释视觉和文本数据之间的复杂交互。类似于它们在自然语言处理(NLP)中的影响,这些模型作为更通用的任务解决者,在利用其广泛的知识库和从大量多模态数据中获得的上下文理解方面表现出色,擅长处理更广泛的任务范围。这使它们不仅能够理解视觉内容,还能够以更符合人类理解方式的方式进行推理。许多作品还探索了在视频理解任务中使用LLMs,即Vid-LLMs。
2. 基础知识
视频理解的任务已从基本分类和识别演变为更复杂的任务,如标题、总结、关联和检索以及问答等。这些任务要求模型以接近人类水平的理解来解释视频,融合了时间连续性、逻辑推理和语境知识。视频理解的主要任务包括识别和预测、标题和总结、关联和检索以及问答等类型。并且模型已经从处理有限帧数的经典方法发展到可以处理数百帧,使其能够提供详细描述并回答有关视频内容的复杂问题。将大型语言模型(LLMs)整合到视频理解中的四个主要策略正在推动这一进程。
- LLM-based Video Agents: 在LLM为基础的视频理解方法中,LLM充当中央控制器。它们引导视觉模型有效地将视频中的视觉信息转化为语言领域,包括提供详细的文本描述和转录音频元素。
- Vid-LLM Pretraining: Vid-LLM预训练方法专注于利用监督或对比训练技术从头开始开发基础视频模型。在这个框架中,LLMs既充当编码器又充当解码器,为视频理解提供了全面的功能。
- Vid-LLM Instruction Tuning: Vid-LLM指令调整策略涉及构建专门的调整数据集,以精细调整视觉模型与LLMs的整合,特别在视频领域。
- Hybrid Methods: 混合方法利用视觉模型在微调过程中提供额外反馈。这种协作方法使模型能够获得超出文本生成的能力,如物体分割和其他复杂的视频分析任务。
2.1 将视频信息与大语言模型整合
为了赋予LLMs解释视频内容的能力,有两种主要方法:
- 利用预训练的视觉模型从视频中提取文本信息,并将其格式化为LLMs生成回应的提示词;
- 将LLMs与视觉模型结合起来,使用微调或预训练策略创建一个统一模型,能够处理视频内容。
先进的大型语言模型如GPT-4具有作为控制器的能力,指导视觉模型执行特定任务。在这个框架中,视觉模型主要充当翻译器,将视觉信息转换为语言文本。流行的视觉模型选择包括字幕生成模型和标注模型。这些模型通常在广泛的数据集上预训练,并且易于集成。
视觉模型提取的语言信息然后被转换为LLMs生成响应或请求进一步信息的提示。视觉模型在这个交互过程中发挥着至关重要的作用,根据LLMs的需要可以提供更详细或具体的信息。LLMs与视觉模型之间的这种协作创造了一个能够解释和回应复杂视觉输入的动态系统。
在微调方面,主要有两种普遍的类别:基于帧的编码器和时间编码器。这些视频编码器处理不同长度的输入视频,通过视频建模模块将帧级特征聚合成统一的视频级特征。
2.2 视频理解任务中大语言模型的角色
语言在视频理解中起着重要作用,主要包括文本编码和解码两个方面。
对于文本编码,装有编码器的语言模型(如BERT或T5)因其稳健的性能和出色的适应性在该领域备受青睐。生成的文本嵌入通常与视频嵌入合并,作为解码器的输入。例如,BLIP-2模型中使用的Q-former即采用了这种方法。
在文本解码方面,从专门针对不同任务的转换器模型转向预训练语言模型。这些大型语言模型参数规模各不相同,Bert系列的一些模型可以有数亿个参数,而LLaMA系列的模型则可能达到数十亿个参数。采用Transformer架构,它们在自回归框架下运行,预测序列中的下一个令牌,这对于文本生成非常有效。在这个领域,LLaMA系列尤为突出,特别是像Vicuna这样的模型。Vicuna以其7B/13B模型规模而闻名,尤其在文本解码任务中表现出色。
2.3 其他模态
我们需要区分:“音频”指视频中的背景声音,“语音”涵盖视频中的口头内容。音频和语音通常被分开处理,音频被视为一个整体,而语音则被转成文本。语音通常由专门的语音编码器处理,通常是一个预训练的语音识别模型,如Whisper。该模型将语音转成文本,为LLM提供有价值的上下文信息。
2.4 训练策略
在调整预训练的基础模型以适应各种视频理解任务时,通常会使用适配器模块,它充当了两个角色:
- 在基础模型和LLM之间架起桥梁
- 帮助预训练模型适应新任务,同时不会丢失从预训练中学到的知识。
适配器通常作为可学习的、参数高效的模块添加到预训练模型中&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2501
2501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









