







OS-ATLAS: A FOUNDATION ACTION MODEL FOR GENERALIST GUI AGENTS
前言
一篇ICLR 2025的高分工作,面向GUI场景的基座模型的研究。通过作者的观测以及相应的方法的应用,得到了领域内的SOTA模型,证实了作者的猜想。这是GUI Agent领域的一篇开拓性的工作,证明了action和grounding是可以统一的,这也为未来在grounding基础上收集大量轨迹数据做action和planning的工作打下了坚实的基础。| Paper | https://arxiv.org/pdf/2410.23218 |
|---|---|
| github | https://github.com/OS-Copilot/OS-Atlas |
| HomePage | https://osatlas.github.io/ |
Abstract
现有构建GUI智能体的工作严重依赖商业VLMs的能力,因为开源VLM性能明显滞后,特别在GUI场景。为此,本文引入一个GUI动作基座模型——OS-Atlas,它具有很强的Grounding能力,同时能够泛化到OOD的Agent场景。作者投入大量精力开发了跨平台的GUI数据工具包,基于该工具包,作者发布了迄今为止最大的开源平台GUI基础语料库,包含超过1300万个GUI元素。基于该语料库训练得到的OS-Atlas具有很强的GUI理解能力并且能泛化到未见的场景。在跨三个平台、六个Benchmark上评测结果取得了显著的性能提升。
Motivation
现有的digital agent很多基于环境的文本描述,最新的工作有尝试只使用屏幕截图来执行复杂任务,但是受到VLM在GUI场景的限制而表现不佳,这主要归因两个元素:
- 现有VLMs很少在GUI截图上训练。
- 现有的开源数据集在内容和格式上异质。
因此,本文期望构建一个强大的基座action模型,用于未来通用智能体的开发。
Solution
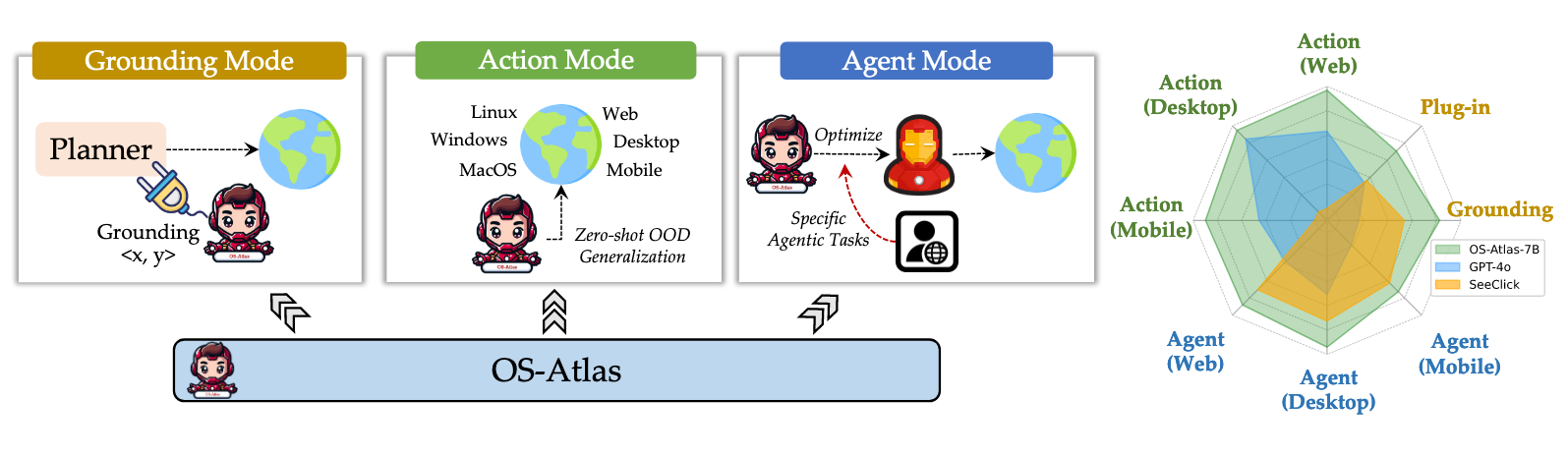
- 构建跨平台的GUI grounding数据合成工具。
- 基于
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1265
1265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











