


import tensorflow as tf
"""
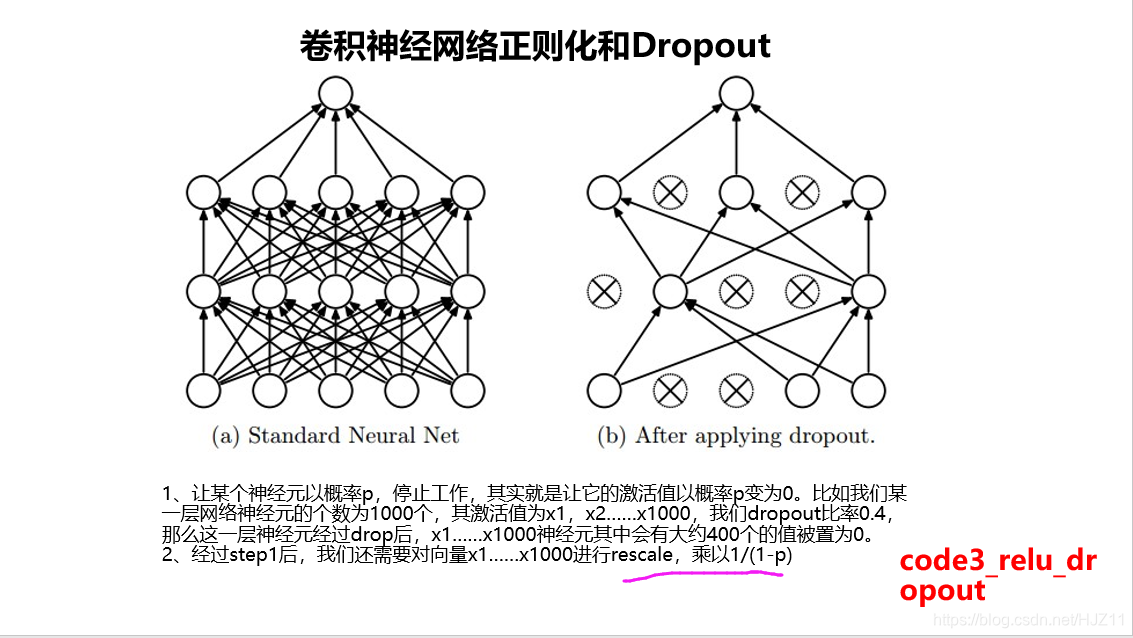
学习relu激活函数 和 dropout的使用
"""
tf.set_random_seed(43)
def activation_func():
with tf.Graph().as_default():
hidden_layer_weights = tf.truncated_normal(shape=[4, 3], stddev=1.0)
output_weights = tf.truncated_normal(shape=[3, 2], stddev=1.0)
weights = [
tf.get_variable('w1', initializer=hidden_layer_weights),
tf.get_variable('w2', initializer=output_weights)
]
biases = [
tf.get_variable('b1', initializer=tf.zeros(3)),
tf.get_variable('b2', initializer=tf.zeros(2))
]
input_x = tf.constant(value=[[1, 2, 3, 4],
[-1, -23, -32, -12],
[11, 12, 2, 3]], dtype=tf.float32)
hidden_input = tf.matmul(input_x, weights[0]) + biases[0]
activate_out = tf.nn.relu(hidden_input)
relu6_out = tf.nn.relu6(hidden_input)
alpha = 0.2
leaky_relu_out = tf.maximum(hidden_input, hidden_input*alpha)
final_output = tf.matmul(activate_out, weights[1]) + biases[1]
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
hidden_input_, activate_out_, relu6_out_, leaky_relu_out_ = sess.run(
[hidden_input, activate_out, relu6_out, leaky_relu_out]
)
print('激活之前的值为:{}'.format(hidden_input_),
'\n',
'relu 激活值为:{}'.format(activate_out_),
'\n',
'relu6 激活值为:{}'.format(relu6_out_),
'\n',
'leaky relu激活值为:{}'.format(leaky_relu_out_))
def dense(inputs, units, name, activation=None, use_bias=True, trainable=True):
"""
tf.layers.dense(
inputs, # 输入的tensor
units, # 隐藏层的节点数量(神经元的个数。)
activation=None, # 是否使用激活函数,None 代表不用激活函数
use_bias=True, # 是否创建偏置项
kernel_initializer=None, # 权重的初始化器
bias_initializer=init_ops.zeros_initializer(), # 偏置项初始化器
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
trainable=True, # 参数(权重和偏置项)是否可以被训练。
name=None, # 名字
reuse=None): # 参数是否重用
"""
shape = inputs.get_shape()
with tf.variable_scope(name):
weights = tf.get_variable(
'w', shape=[shape[-1], units],
initializer=tf.truncated_normal_initializer(stddev=0.1),
trainable=trainable
)
fc_out = tf.matmul(inputs, weights)
if use_bias:
bias = tf.get_variable(
'b', shape=[units],
initializer=tf.zeros_initializer(),
trainable=trainable
)
fc_out = fc_out + bias
if activation:
return activation(fc_out)
return fc_out
def dense_func():
with tf.Graph().as_default():
hidden_layer_weights = tf.truncated_normal(shape=[4, 3], stddev=1.0)
output_weights = tf.truncated_normal(shape=[3, 2], stddev=1.0)
weights = [
tf.get_variable('w1', initializer=hidden_layer_weights),
tf.get_variable('w2', initializer=output_weights)
]
biases = [
tf.get_variable('b1', initializer=tf.zeros(3)),
tf.get_variable('b2', initializer=tf.zeros(2))
]
input_x = tf.constant(value=[[1, 2, 3, 4],
[-1, -23, -32, -12],
[11, 12, 2, 3]], dtype=tf.float32)
hidden_input = tf.matmul(input_x, weights[0]) + biases[0]
hidden_out = tf.nn.relu(hidden_input)
"""
tf.layers.dense(
inputs, # 输入的tensor
units, # 隐藏层的节点数量(神经元的个数。)
activation=None, # 是否使用激活函数,None 代表不用激活函数
use_bias=True, # 是否创建偏置项
kernel_initializer=None, # 权重的初始化器
bias_initializer=init_ops.zeros_initializer(), # 偏置项初始化器
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
trainable=True, # 参数(权重和偏置项)是否可以被训练。
name=None, # 名字
reuse=None): # 参数是否重用
"""
hidden_out1 = tf.layers.dense(
input_x, units=3, use_bias=True, activation=tf.nn.relu
)
hidden_out2 = dense(
input_x, units=3, name='dense', activation=None,
use_bias=True, trainable=True)
logits = tf.matmul(hidden_out, weights[1]) + biases[1]
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
hidden_out_, hidden_out1_, hidden_out2_, final_output_ = sess.run(
[hidden_out, hidden_out1, hidden_out2, logits]
)
print(hidden_out_, hidden_out1_)
def drop_out(x, keep_prob):
"""
自己实现dropout函数。
:param x:
:param keep_prob:
:return:
"""
x_shape = x.get_shape()
k_prob = tf.cast(tf.random_uniform(shape=x_shape, maxval=1) < keep_prob, tf.float32) / keep_prob
x = x * k_prob
return x
def dropout_func():
with tf.Graph().as_default():
hidden_layer_weights = tf.truncated_normal(shape=[4, 3], stddev=1.0)
output_weights = tf.truncated_normal(shape=[3, 2], stddev=1.0)
weights = [
tf.get_variable('w1', initializer=hidden_layer_weights),
tf.get_variable('w2', initializer=output_weights)
]
biases = [
tf.get_variable('b1', initializer=tf.zeros(3)),
tf.get_variable('b2', initializer=tf.zeros(2))
]
input_x = tf.constant(value=[[1, 2, 3, 4],
[-1, -23, -32, -12],
[11, 12, 2, 3]], dtype=tf.float32)
hidden_input = tf.matmul(input_x, weights[0]) + biases[0]
hidden_output = tf.nn.leaky_relu(hidden_input)
hidden_output_drop = tf.nn.dropout(hidden_output, keep_prob=0.6)
hidden_output_drop1 = drop_out(hidden_output, keep_prob=0.6)
final_output = tf.matmul(hidden_output_drop, weights[1]) + biases[1]
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
hidden_output_, hidden_output_drop_, hidden_output_drop1_ = sess.run(
[hidden_output, hidden_output_drop, hidden_output_drop1]
)
print('leaky relu激活值为:{}'.format(hidden_output_),
'\n',
'tf.nn.dropout之后的值为:{}'.format(hidden_output_drop_),
'\n',
'自己实现的dropout之后的值为:{}'.format(hidden_output_drop1_))
if __name__ == '__main__':
activation_func()
dense_func()
dropout_func()
激活之前的值为:[[ 2.859401 2.0733218 -2.0179286]
[ -5.016388 -0.7504692 -1.0032654]
[ 19.776606 -11.05093 -22.942028 ]]
relu 激活值为:[[ 2.859401 2.0733218 0. ]
[ 0. 0. 0. ]
[19.776606 0. 0. ]]
relu6 激活值为:[[2.859401 2.0733218 0. ]
[0. 0. 0. ]
[6. 0. 0. ]]
leaky relu激活值为:[[ 2.859401 2.0733218 -0.40358573]
[-1.0032777 -0.15009384 -0.20065308]
[19.776606 -2.210186 -4.5884056 ]]
[[ 2.6600227 11.10044 0. ]
[13.155464 0. 28.872334 ]
[ 0. 16.034973 0. ]] [[ 0. 3.531556 0.4266281]
[ 3.4427366 0. 18.767883 ]
[ 0. 7.7806087 0. ]]
leaky relu激活值为:[[ 3.4195879 -0.524014 2.676589 ]
[ 6.741766 8.814518 11.51157 ]
[-4.762424 4.847961 8.176558 ]]
tf.nn.dropout之后的值为:[[ 5.699313 -0.87335664 4.4609814 ]
[11.236277 14.690863 19.18595 ]
[-7.937373 8.079935 13.627596 ]]
自己实现的dropout之后的值为:[[ 5.699313 -0.87335664 0. ]
[11.236277 14.690863 19.18595 ]
[-0. 0. 13.627596 ]]
Process finished with exit code 0























 362
362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









