







1 对于丢弃法的一点小思考
(1) 对于模型设计我们可以把隐藏层设计的稍微大一点然后用drop out控制隐藏层大小这样的设计可能比隐藏层设计的小一点的效果更好,防止过拟合,drop out 其实就是一个正则项。
(2) drop out 就是随机丢弃隐藏层神经元的个数从而防止参数过分依赖训练数据,增加参数对数据集的泛化能力
(3) Drop out可以减少神经元之间复杂的共适应关系,因为Dropout使得某两个神经元不一定每次都在一个子网络结构中出现。基于此权值的更新不在依赖于固定关系的隐含节点的共同作用,使得了在丢失某些特定信息的情况下依然可以从其它信息中学到一些模式(鲁棒性),迫使网络去学习更加鲁棒的特征(更加具有通适性)。
(4) drop out作用在隐藏层的输出可以再激活函数之前也可以在激活函数之后。drop out作用在全连接层而不是卷积层,丢弃前一层的输出丢弃后一层的输出。drop out 比起权重衰退(L2正则化来说)更容易调参
(5) 随机性高稳定性就会增加这怎么理解呢? 我理解的是随机性高了会弱化一些偶然事件的影响考虑的方面会增多防止过拟合。
(6) 丢弃法是在训练的时候丢弃一些神经元,在预测的时候没有丢弃神经元。
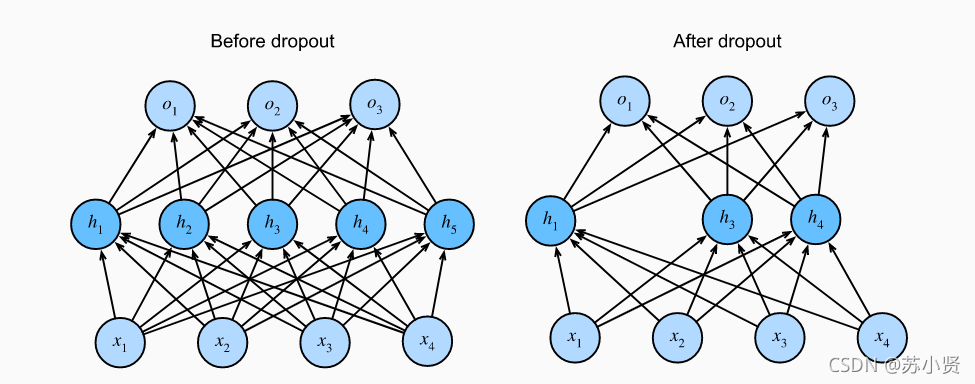
2 代码实现(手动)
(1) 生成dropout函数
import torch
from torch import nn
from d2l import torch as d2l
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1 #ssert断言是声明其布尔值必须为真的判定,如果发生异常就说明表达示为假.也就是说dropout值必须在0-1之间
# 在本情况中,所有元素都被丢弃。
if dropout == 1:
return torch.zeros_like(X)
#  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









