









实验内容
完成两中分类算法:朴素贝叶斯算法,决策树算法
分类算法
分类算法是基于有类标号的训练集数据建立分类模型并使用其对新观测值(测试数据集)进行分类的算法。
通俗的说就是发现经验,然后通过经验来得到结果。
汽车满意度数据集
汽车已经成为了人们出行必不可少的工具之一。现在各个汽车销售商也是想方设法提高汽车的销售量。但汽车的销售量是由什么决定的呢?
换而言之,汽车的销售量是由客户的满意度来决定的。我们又想问,汽车的满意度是主要由什么决定的呢?汽车的价格,质量,舒服度哪个因素起的作用更大呢?
有这样一份数据集:
- buy: buying price(购买价格,分为low, med, high, vhigh)
- main: price of the maintenance(保养价格,分为low, med, high, vhigh)
- doors: number of doors(门的个数,分为2, 3, 4, 5more)
- capacity: capacity in terms of persons to carry(载人个数)
- lug_boot: the size of luggage boot(车身的大小,分为small, med, big)
- safety: estimated safety of the car(安全程度,分为low, med, high)
- accept: car acceptability(被接受程度,四个等级:unacc, acc, good, vgood)
实验内容
朴素贝叶斯
算法原理
首先得知道贝叶斯公式

而朴素贝叶斯指的就是多个特征值(就上面数据集除了最后汽车满意度accept,其他都是特征值)之间相互独立。
根据概率论知识,A,B相互独立的话有以下公式。
P(AB)=P(A)P(B)
P(AB|C)=P(A|C)*P(B|C)
而根据已经有的数据集(数据集),test作为训练集

然后根据训练得到的模型预测predict数据集的结果,与已经给的结果对比,求一个最后的正确率。
关键在于如何根据6个特征值预测接受度!
比如已经知道6个特征值
| 特征 | Value |
|---|---|
| buy | vhigh |
| main | vhigh |
| doors | 2 |
| capacity | 2 |
| lug_boot | small |
| safety | low |
我们需要去预测一下accept的值,把上面6个特征值称为 事实前提S
被接受程度,四个等级:unacc, acc, good, vgood
本质是找到P(unacc|S),P(acc|S),P(good|S),P(vgood|S)中最大的一个
用到贝叶斯公式:
P(accept|S)=P(S|accept)*P(accept) / P(S)
S是6个特征合集,前面提到的相互独立就可以把他们拆开了。
比如求P(buy=vhigh),就是统计训练集数据这种情况的占比
具体代码实现
训练集数据读入时,做统计处理
主要用五个二维数组记录
#include <iostream>
#include <fstream>
using namespace std;
string buys[]={"low","med","high","vhigh"};
string maintes[]={"low","med","high","vhigh"};
string doors[]={"2","3","4","5more"};
string capacitys[]={"2","4","more"};
string lug_boots[]={"small","med","big"};
string safetys[]={"low","med","high"};
string accepts[]={"unacc","acc","good","vgood"};
int a[10][5];//无条件时
int b[10][5];//accept=unacc
int c[10][5];//accept=acc
int d[10][5];//accept=good
int e[10][5];//accept=vgood
int cnt = 0;
string str[10];
int Getj(int i)//根据特征找到数组索引
{
int k;
switch(i){
case 0:
for(k = 0;k < 4;k++){
if(str[i]==buys[k])
return k;
}
break;
case 1:
for(k = 0;k < 4;k++){
if(str[i]==maintes[k])
return k;
}
break;
case 2:
for(k = 0;k < 4;k++){
if(str[i]==doors[k])
return k;
}
break;
case 3:
for(k = 0;k < 4;k++){
if(str[i]==capacitys[k])
return k;
}
break;
case 4:
for(k = 0;k < 4;k++){
if(str[i]==lug_boots[k])
return k;
}
break;
case 5:
for(k = 0;k < 4;k++){
if(str[i]==safetys[k])
return k;
}
break;
case 6:
for(k = 0;k < 4;k++){
if(str[i]==accepts[k])
return k;
}
break;
}
}
void Cal(){
for(int i = 0;i < 7;i++){
a[i][Getj(i)]++;
if(str[6]=="unacc")
b[i][Getj(i)]++;
if(str[6]=="acc")
c[i][Getj(i)]++;
if(str[6]=="good")
d[i][Getj(i)]++;
if(str[6]=="vgood")
e[i][Getj(i)]++;
}
}
double Pre()//预测结果与实际结果对比
{
double tol=1350;
double x1=1,x2=1,x3=1,x4=1;
double fac1,fac2;
for(int i = 0;i < 6;i++){
fac1 = b[i][Getj(i)];//buy&unacc
fac2 = a[6][0];//unacc
x1*=fac1/fac2;//P(buy|unacc)*P(main|unacc)*...
fac1 = a[i][Getj(i)];//buy
x1/=fac1/tol;
fac1 = c[i][Getj(i)];//buy&acc
fac2 = a[6][1];//acc
x2*=fac1/fac2;//P(buy|acc)*P(main|acc)
fac1 = a[i][Getj(i)];
x2/=fac1/tol;
fac1 = d[i][Getj(i)];
fac2 = a[6][2];
x3*=fac1/fac2;//P(buy|good)*P(main|good)
fac1 = a[i][Getj(i)];
x3/=fac1/tol;
fac1 = e[i][Getj(i)];
fac2 = a[6][3];
x4*=fac1/fac2;//P(buy|vgood)*P(main|vgood)
fac1 = a[i][Getj(i)];
x4/=fac1/tol;
}
x1*=a[6][0]/tol;
x2*=a[6][1]/tol;
x3*=a[6][2]/tol;
x4*=a[6][3]/tol;
if(x1>=x2&&x1>=x3&&x1>=x4&&Getj(6)==0)
cnt++;
if(x2>=x1&&x2>=x3&&x2>=x4&&Getj(6)==1)
cnt++;
if(x3>=x1&&x3>=x2&&x3>=x4&&Getj(6)==2)
cnt++;
if(x4>=x1&&x4>=x2&&x4>=x3&&Getj(6)==3)
cnt++;
}
int main()
{
ifstream in1("test.txt");
ifstream in2("predict.txt");
cout << "开始导入训练集数据,训练集数据共计1350个\n";
for(int i = 0;i < 1350;i++){
in1 >> str[0] >> str[1] >> str[2] >>
str[3] >> str[4] >> str[5] >> str[6];
Cal();
}
cout << "数据归类完毕!\n";
cout << "开始导入预测数据集,共计378个\n";
for(int i = 0;i < 378;i++){
in2 >> str[0] >> str[1] >> str[2] >>
str[3] >> str[4] >> str[5] >> str[6];
Pre();
}
cout<<"预测结果分析完毕 \n";
cout << "根据训练集数据预测结果符合的共计" << cnt <<"个\n";
cout << "预测正确率为:" ;
cout << (double)cnt/378;
cout << endl;
in1.close();
in2.close();
}
决策树算法
决策树简介
决策树算法是一种逼近离散函数值的方法。它是一种典型的分类方法,首先对数据进行处理,利用归纳算法生成可读的规则和决策树,然后使用决策对新数据进行分析。本质上决策树是通过一系列规则对数据进行分类的过程。
决策树方法最早产生于上世纪60年代,到70年代末。由J Ross Quinlan提出了ID3算法,此算法的目的在于减少树的深度。但是忽略了叶子数目的研究。

基本思想:
- 1)树以代表训练样本的单个结点开始。
- 2)如果样本都在同一个类.则该结点成为树叶,并用该类标记。
- 3)否则,算法选择最有分类能力的属性作为决策树的当前结点.
- 4)根据当前决策结点属性取值的不同,将训练样本数据集tlI分为若干子集,每个取值形成一个分枝,有几个取值形成几个分枝。匀针对上一步得到的一个子集,重复进行先前步骤,递4’I形成每个划分样本上的决策树。一旦一个属性出现在一个结点上,就不必在该结点的任何后代考虑它。
- 5)递归划分步骤仅当下列条件之一成立时停止:
①给定结点的所有样本属于同一类。
②没有剩余属性可以用来进一步划分样本.在这种情况下.使用多数表决,将给定的结点转换成树叶,并以样本中元组个数最多的类别作为类别标记,同时也可以存放该结点样本的类别分布,
③如果某一分枝tc,没有满足该分支中已有分类的样本,则以样本的多数类创建一个树叶。
ID3算法
ID3算法是一种贪心算法,用来构造决策树。ID3算法起源于概念学习系统(CLS),以信息熵的下降速度为选取测试属性的标准,即在每个节点选取还尚未被用来划分的具有最高信息增益的属性作为划分标准,然后继续这个过程,直到生成的决策树能完美分类训练样例。
** 信息熵与信息增益**
在信息增益中,重要性的衡量标准就是看特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要。
- 信息熵的定义
假如一个随机变量的取值为,每一种取到的概率分别是,那么的熵定义为
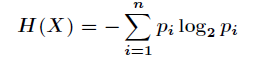
- 信息增益
信息增益是针对一个一个特征而言的,就是看一个特征,系统有它和没有它时的信息量各是多少,两者的差值就是这个特征给系统带来的信息量,即信息增益。

一共14个样例,包括9个正例和5个负例。那么当前信息的熵计算如下
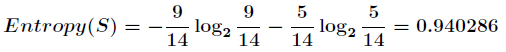
假设利用属性Outlook来分类,分类后:
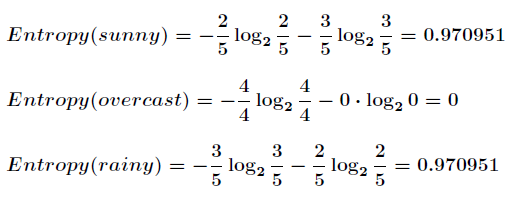
划分后的信息熵为:
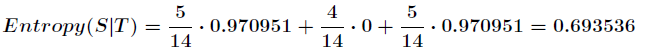
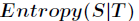
代表在特征属性的条件下样本的条件熵。那么最终得到特征属性带来的信息增益为
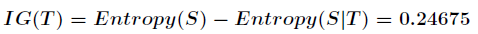
信息增益的计算公式如下:
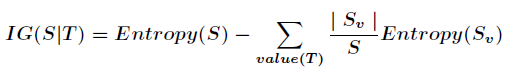
ID3算法最终生成的决策树就是左右叶子节点都只包含一类数据。
IDS算法的python实现
这里调用了sklearn已有算法的包,主要需要对数据进行预处理一下。
from sklearn import tree
import numpy as np
#将特征值转为整数
# buying,maint,doors,persons,lug_boot,safety,Class_Values
def buying(s):
type2 = {b'vhigh': 0, b'high': 1, b'med': 2, b'low': 3}
return type2[s]
def maint(s):
type3 = {b'vhigh': 0, b'high': 1, b'med': 2, b'low': 3}
return type3[s]
def Class_Values(s):
type1 = {b'unacc':0, b'acc':1, b'good':2, b'vgood':3}
return type1[s]
def doors(s):
type4 = {b'2':0, b'3':1, b'4':2, b'5more':3}
return type4[s]
def persons(s):
type5 = {b'2':0, b'4':1, b'more':2}
return type5[s]
def lug_boot(s):
type6 = {b'small':0, b'med':1, b'big':2}
return type6[s]
def safety(s):
safety = {b'low':0, b'med':1, b'high':2}
return safety[s]
# 数据文件路径
path1 = 'test.txt' #训练集
path2 = 'predict.txt' #预测集
train = np.loadtxt(path1,dtype=int,delimiter=',',converters={0:buying,1:maint,2:doors,3: persons,4:lug_boot,5:safety,6:Class_Values})
test = np.loadtxt(path2,dtype=int,delimiter=',', converters={0:buying,1:maint,2:doors,3:persons,4:lug_boot,5:safety,6:Class_Values})
train_x, train_y = np.split(train, (6,), axis=1) #划分特征 和 结果
test_x, test_y = np.split(test, (6,), axis=1) #划分属性 和 value
#使用信息熵作为划分标准,对决策树进行训练
clf=tree.DecisionTreeClassifier(criterion='entropy')
clf.fit(train_x, train_y.ravel())
#print (clf.score(train_x, train_y))
print ("测试集正确率为: ")
print (clf.score(test_x, test_y))
#生成决策树dot文件
with open("jueceshu.dot", 'w') as f:
f = tree.export_graphviz(clf, out_file = f)
用可视化工具转dot文件成pdf格式如下:

支持向量机

SVM简介
支持向量机(support vector machines, SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;SVM还包括核技巧,这使它成为实质上的非线性分类器。SVM的的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。SVM的的学习算法就是求解凸二次规划的最优化算法。
python代码实现:
from sklearn import svm
from main import train_x, train_y, test_x, test_y
clf = svm.SVC(C=0.8, kernel='rbf', gamma=10, decision_function_shape='ovo')
clf.fit(train_x, train_y.ravel())
print (clf.score(train_x, train_y)) # 精度
y_hat = clf.predict(train_x)
print (clf.score(test_x, test_y))
y_hat = clf.predict(test_x)
#print(classification_report(test_y,y_hat))
clf = svm.SVC(C=0.8, kernel='linear', decision_function_shape='ovr')
clf.fit(train_x, train_y.ravel())
print (clf.score(train_x, train_y))
print (clf.score(test_x, test_y))
人工神经网络
神经网络
神经网络模型:

单个神经元:

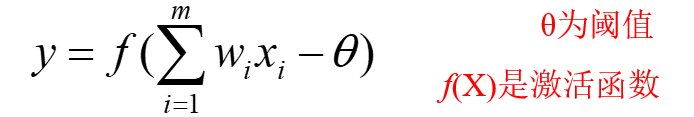
激活函数

python实现:
from sklearn.neural_network import MLPClassifier
from main import train_x, train_y, test_x, test_y
clf = MLPClassifier(hidden_layer_sizes=(12,9),
activation='logistic',
solver='lbfgs',
alpha=1e-3,
random_state=1)
clf.fit(train_x, train_y.ravel())
print (clf.score(test_x, test_y))
总结
朴素贝叶斯相对简单,实现一遍之后更深刻的记住它,决策树的话目前只能手动计算简单数据集的题,因此调包大法好!














 422
422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









