









Python实现离线音频转文字(时间分隔+区分说话人)
前言
- 前阵子因工作原因,需要将一些录音文件转为文字,方便后续记录和摘要。在尝试付费使用了一些成熟的语音识别转写APP后,偶然发现讯飞开放平台有5小时免费时长可领取使用。
- 虽是免费,但是需要自己编写代码进行使用,于是参考了官网的API使用说明,自己实现了一个python版本的离线音频转写,默认支持普通话和英语。
领取转写时长
- 浏览器打开讯飞开放平台首页:https://www.xfyun.cn/,点击“语音识别”→“语音转写”,进入语音转写模块页面。
- 完成新用户的注册登录认证后,即可领取免费时长。
- **注意:**因为我们要实现的是离线音频上传后转写为文字,所以领取免费时长时领的是“语音转写”,而不是“语音听写”。
创建个人应用
- 注册登录并领取免费时长后,右上角点击“控制台”,进入控制台页面,并创建一个新应用。
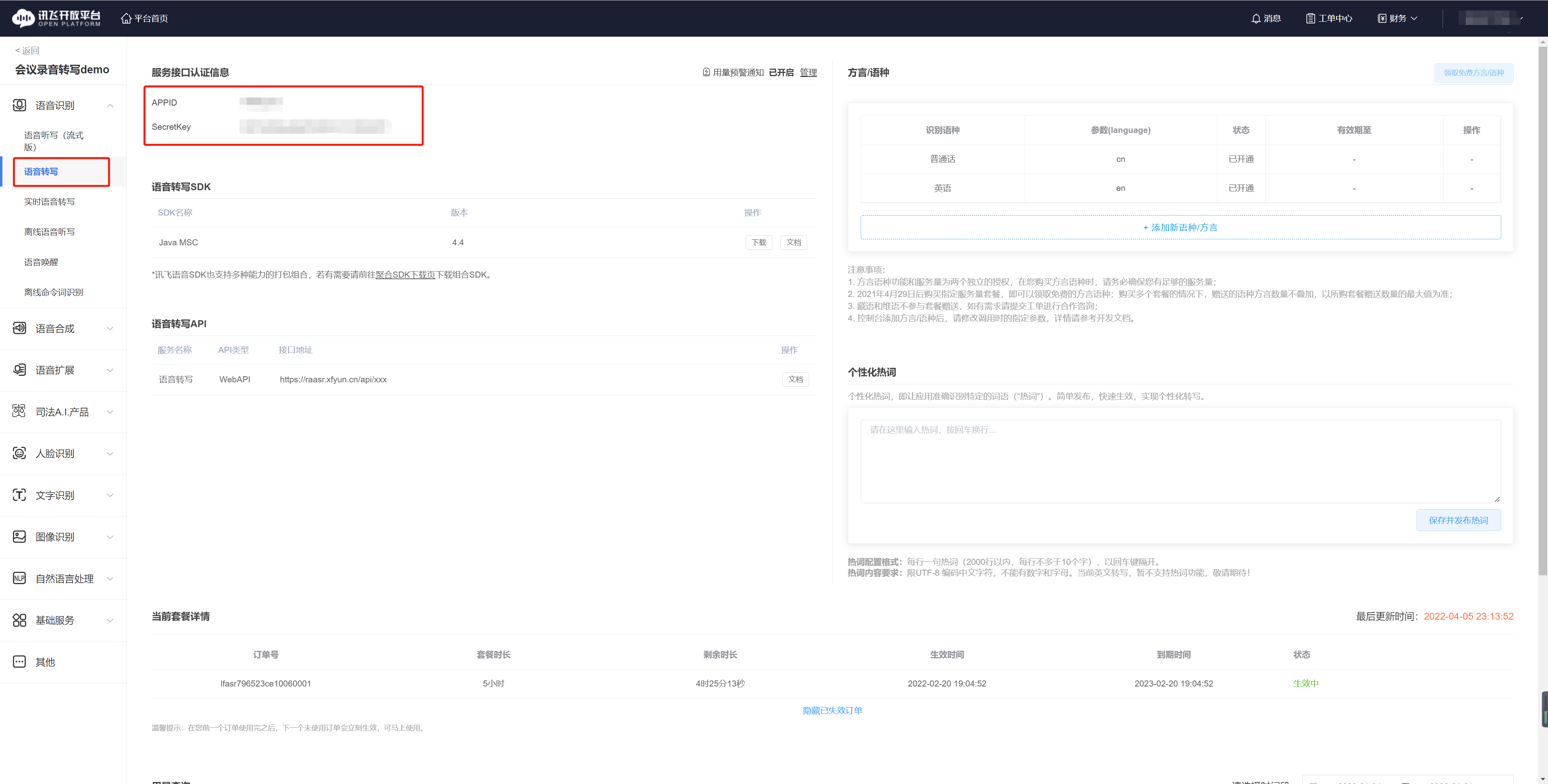
- 创建应用后,进入应用管理页面,点击“语音转写”模块,获取APPID和密钥,后面代码运行要用到这两个参数。
运行Python代码
运行环境
- Python3.7
- 需要特别注意的依赖库:requests==2.21.0
解决思路
- 参考讯飞开放平台上的接口说明和使用demo,输入APPID和密钥后,可访问对应的语音转写接口API,得到转写后的文字数据。
- 返回数据中包括每一句话的起始点、结束点、说话人、文字内容,所需要做的是对返回的JSON格式数据进行相应的读取,转为可读性高的文本文件。
- 笔者代码中所做到的,一个是将整段的文本保存下来,不做时间分隔以及说话人区分,便于单人单段演讲或讲话的录音文件转写;另一个是做了时间分隔和说话人区分的版本,便于多人会议或讨论的录音文件转写。

- 时间分隔的算法思路是,记录上一句话的结束点,如果与当前这一句话的起始点重合(精确到毫秒),说明这两句话是紧密衔接着的,可以拼接在一起。于是设置一个缓冲区存放当前拼接着的文本,如果上下两句不衔接,则将缓冲区内容写入文件,刷新缓冲区,放入当前句子的文本内容。遍历平台返回数据的每一句话,不断更新和写入缓冲区,便实现了整段音频做了时间分隔并写入文件。
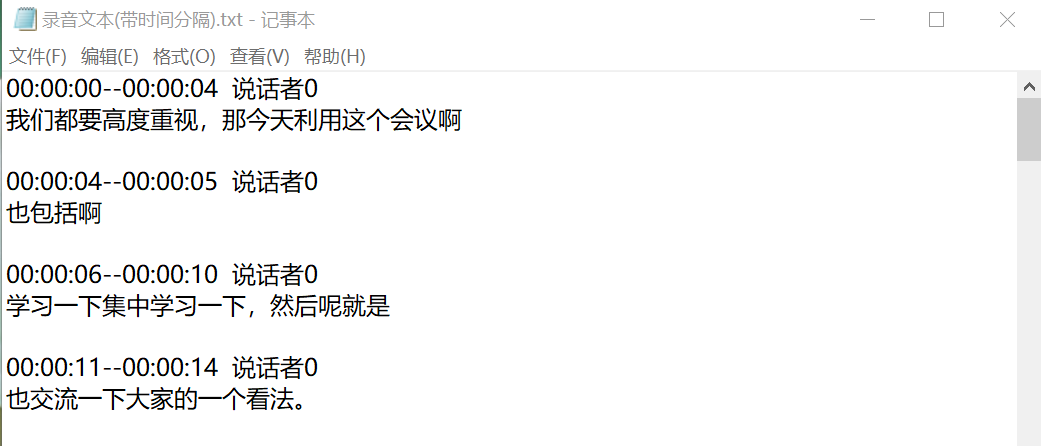
- 两种转写方式的文本均有保存到代码同目录下,保存格式为txt文件。以下为时间分分割版本的截图:
修改参数
- 运行代码时,需修改相关参数为自己创建的应用的APPID和密钥,以及想要转写的录音文件路径。

代码下载
-
代码资源地址:讯飞开放平台音频转文字(python)


















 3403
3403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











