







翻译|Gradient Descent in Python
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use(['ggplot'])当你初次涉足机器学习时,你学习的第一个基本算法就是 梯度下降 (Gradient Descent), 可以说梯度下降法是机器学习算法的支柱。 在这篇文章中,我尝试使用 python解释梯度下降法的基本原理。一旦掌握了梯度下降法,很多问题就会变得容易理解,并且利于理解不同的算法。
如果你想尝试自己实现梯度下降法, 你需要加载基本的 python packages —— numpy and matplotlib
首先, 我们将创建包含着噪声的线性数据
# 随机创建一些噪声
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)array([[1.33025881], [0.09309373], [0.49532139], [1.60476696], [0.58710846], [1.56722395], [0.59914427], [1.51932972], [1.13519401], [1.48989254]])
接下来通过 matplotlib 可视化数据
# 可视化数据
plt.plot(X, y, 'b.')
plt.xlabel("$x$", fontsize=18)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.axis([0, 2, 0, 15])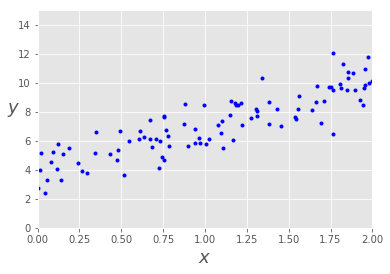
显然, yy 与 xx 具有良好的线性关系,这个数据非常简单,只有一个自变量 xx.
我们可以将其表示为简单的线性关系:
y=b+mx
并求出 b , m。
这种被称为解方程的分析方法并没有什么不妥,但机器学习是涉及矩阵计算的,因此我们使用矩阵法(向量法)进行分析。
我们将 y 替换成 J(θ), b 替换成 θ0, m 替换成 θ1。
得到如下表达式:
J(θ)=θ0+θ1x
注意: 本例中 θ0=4, θ1=3
求解 θ0和 θ1的分析方法,代码如下:
X_b = np.c_[np.ones((100, 1)), X] # 为X添加了一个偏置单位,对于X中的每个向量都是1
theta_best = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y)
theta_bestarray([[4.0728819 ], [3.05958308]])
不难发现这个值接近真实的 θ0,θ1,由于我在数据中引入了噪声,所以存在误差。
X_new = np.array([[0], [2]])
X_new_b = np.c_[np.ones((2, 1)), X 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 419
419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









