






1. 加载数据
import pandas as pd
marketing = pd.read_csv("DirectMarketing.csv")
2.遍历数据
marketing.head(8)/describe()/info()
3.selecting columns
按columns的标题进行索引
print(marketing[['Age', 'Married', 'AmountSpent']])
4.selecting rows
print(marketing.iloc[[3, 5, 8]])
5.处理missing data
isnull 和 dorpna
6.增加新的行数
import pandas as pd
marketing = pd.read_csv('/course/data/DirectMarketing.csv')
ratio = marketing['Salary'] / marketing['AmountSpent']
marketing['SalarySpendRatio'] = ratio
print(marketing.head())
7.数数
计算有多少个不一样的项
print(marketing['Age'].nunique())
计算每个项里有多少个
value_counts()
8.正序排列
.sort_values()
import pandas as pd
marketing = pd.read_csv('/course/data/DirectMarketing.csv')
marketing_vc = marketing['Age'].value_counts().sort_index()
print(marketing_vc)
9.查询
import pandas as pd
marketing = pd.read_csv('/course/data/DirectMarketing.csv')
youth = marketing.query('Age == "Young"')
print(youth.head())
设置筛选条件
import pandas as pd
marketing = pd.read_csv('/course/data/DirectMarketing.csv')
age_group = 'Young'
youth = marketing.query('Age == @age_group')
print(youth.head())
and和or来设置筛选条件
import pandas as pd
marketing = pd.read_csv('/course/data/DirectMarketing.csv')
print(marketing.query('AmountSpent > 1000 and Gender == "Female"'))
使用索引符号来查询
synax:
DataFrame[query]
query = marketing['Salary'] > 90000
import pandas as pd
marketing = pd.read_csv('/course/data/DirectMarketing.csv')
x = 1000
big_earners = marketing[marketing['AmountSpent'] > x]
print(big_earners.head())
合并成一行
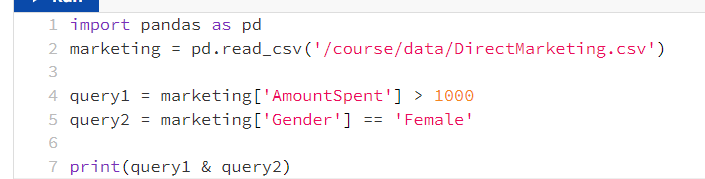
两者条件联合

10.Groupby:
相当于pivot table


11.组合两个columns
















 3170
3170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









