







目录
一、batch normalization和layer normalization的动机
三、Bert、Transformer中为何使用的是LN而很少使用BN
在深度学习中经常看到batch normalization的使用,在Bert模型里面经常看到layer normalization的使用。它们都是归一化的方法,具体的作用和区别以及为何能够work,我认为需要有一个很好的理解。因此,在参考了一些资料形成了这篇博客。
一、batch normalization和layer normalization的动机
batch normalization和layer normalization,顾名思义其实也就是对数据做归一化处理——也就是对数据以某个角度或者层面做0均值1方差的处理。
在机器学习和深度学习中,有一个共识:独立同分布的数据可以简化模型的训练以及提升模型的预测能力——这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障。也就是说我们在使用机器学习和深度学习的时候,会把数据尽可能的做一个独立同分布的处理,用来加快模型的训练速度和提升模型的性能。说到这里就不得不提一下——白化whitening。
白化whitening
什么是白化呢?就是对数据进行如下的2个操作:
1、去除数据之间的关联性,使之满足独立这个条件;2、使得特征具有相同的均值和方差,就是同分布。
以上就是白化,具体的算法有PCA降维白化,参考博文——机器学习(七)白化whitening。
首先看看,深度学习中的一个经典问题。Internal Covariate Shift——内部变量偏移
Internal Covariate Shift——内部变量偏移
深度学习这种包含很多隐层的网络结构,在训练过程中,因为各层参数不停在变化。另一方面,深度神经网络一般都是很多层的叠加,每一层的参数更新都会导致上层的输入数据在输出时分布规律发生了变化,并且这个差异会随着网络深度增大而增大——这就是Internal Covariate Shift。它会导致什么样的问题呢?
每个神经元的输入数据不再是独立同分布的了,那么:
- 上层参数需要不断适应新的输入数据分布,降低学习速度
- 下层输入的变化可能趋向于变大或者变小,导致上层落入饱和区。反向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因——梯度消失。
BN把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,其实就是把越来越偏的分布强制拉回比较标准的分布。这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。经过BN后,目前大部分Activation的值落入非线性函数的线性区内,其对应的导数远离导数饱和区,这样来加速训练收敛过程。
这就是在深度学习中使用BN的一个原因和动机,当然使用LN也是同样的以不同的方式来达到相似的效果。
对于为何BN能起作用这个问题,有不同的观点。有人认为BN能够减少ICS问题,但是有人发布论文说并没有直接的证据表明BN能够稳定数据分布的稳定性,同时也不能减少ICS。作者认为起作用的原因是由于:An empirical analysis of the optimization of deep network loss surfaces
1、BN层让损失函数更平滑
2、BN更有利于梯度下降,使得梯度不会出现过大或者过小的梯度值。
二、BN和LN的框架原理
2.1BN和LN的具体操作原理
BN一般怎么使用呢?原论文的作者是建议把BN放在激活函数之前,但是后面有人建议放在之后,效果都差不太多。
图片来自博文——Batch Normalization详解

以上就是在一些神经网络中,BN的插入位置。
下面来看看具体的BN公式和流程。现在假设batch size为m,那么在前向传播过程中每个节点就有m个输出。则有如下计算方式:

变换后某个神经元的激活x形成了均值为0,方差为1的正态分布,目的是把值往后续要进行的非线性变换的线性区拉动,增大导数值,增强反向传播信息流动性,加快训练收敛速度。但是这样会导致网络表达能力下降,为了防止这一点,每个神经元增加两个调节参数(scale和shift),这两个参数是通过训练来学习到的,用来对变换后的激活反变换,使得网络表达能力增强,即对变换后的激活进行如下的scale和shift操作,这其实是变换的反操作:
BN不同,LN是针对深度网络的某一层的所有神经元的输入按以下公式进行normalize操作——来自博客:Layer Normalization
1)计算各层的期望μ和标注差σ
l表示第l个隐藏层,H表示该层的节点数,a表示某一个节点在激活前的值,即a=w*x。
2)标准化
g和b分别表示增益和偏置参数,可以纳入训练随样本一群训练。
3)加入激活函数输出
2.2BN和LN的优点和不足
BN具有一些什么样的优点呢?
a、加快神经网络的训练时间。BN强行拉平了数据分布,它可以让收敛速度更快。使得总的训练时间更短。
b、容忍更高的学习率(learning rate)和初始化权重更容易。对于深层网络来说,权重的初始化要求是很高的,而BN能够动态的调整数据分布,因此初始化的要求就不像以前那么严格了。
c、可以支持更多的损失函数。有些损失函数在一定的业务场景下表现的很差,就是因为输入落入了激活函数的死亡区域——饱和区域。而BN的本质作用就是可以重新拉正数据分布,避免输入落入饱和区域,从而减缓梯度消失的问题。
d、提供了一点正则化的作用,可能使得结果更好。BN在一定的程度上起到了dropout的作用,因此在适用BN的网络中可以不用dropout来实现。
那么BN的不足呢?
a、BN对于batch_size的大小还是比较敏感的,batch_size很小的时候,其梯度不够稳定,效果反而不好。
b、BN对于序列网络,RNN、lstm等模型的效果并不好
针对以上BN的不足,主要是BN应用到RNN、LSTM等网络上效果不好的缺点,研究人员提出了LN。在继承了BN的优点上,还有另外2个优点:
1、LN能够很好的应用在RNN、lstm等类似的网络上。
2、LN是针对一层网络所有的神经元做数据归一化,因此对batch_size的大小并不敏感。
2.3BN和LN的不同
从原理操作上来讲,BN针对的是同一个batch内的所有数据,而LN则是针对单个样本。另外,从特征维度来说,BN是对同一batch内的数据的同一纬度做归一化,因此有多少维度就有多少个均值和方差;而LN则是对单个样本的所有维度来做归一化,因此一个batch中就有batch_size个均值和方差。借用知乎上的一张图——batchNormalization与layerNormalization的区别——来说明:
简单的来说就是BN和LN进行处理的方向不同。对于BN来说,batch_size大小不同,那么它对应的BN出来的mean和std都是变化的,上图中batch_size=3,均值是mean=3,std=3(第0维度),当batch_size不是3的时候,那么均值和方差就会改变;而LN随着batch_size的不同对应单条样本的均值和方差不同——————BN对batch比较敏感,batch_size不能太小;LN则是独立于batch_size的———就可以这么理解。
2.4BN和LN的实例代码展示
直接上代码:
import torch
from torch.nn import BatchNorm1d
from torch.nn import LayerNorm
def show_difference_BN_LN():
input = torch.tensor([[4.0, 3.0, 2.0],
[3.0, 3.0, 2.0],
[2.0, 2.0, 2.0]
])
print(input)
print(input.size())
BN = BatchNorm1d(input.size()[1]) #`C` from an expected input of size (N, C, L)` or :math:`L` from input of size :math:`(N, L)`
BN_output = BN(input)
print('BN_output:')
print(BN_output)
print('BN_output.size()',BN_output.size())
print('*'*20)
LN = LayerNorm(input.size()[1:]) #normalized_shape (int or list or torch.Size): input shape from an expected input
LN_output = LN(input)
print('LN_output:')
print( LN_output)
print('LN_output.size()', LN_output.size())
print('#' * 40)
input_text = torch.tensor([
[[1.0, 4.0, 7.0],
[0.0, 2.0, 4.0]
],
[[1.0, 3.0, 6.0],
[2.0, 3.0, 1.0]
]
])
print(input_text)
print(input_text.size())
BN = BatchNorm1d(2)#`C` from an expected input of size (N, C, L)` or :math:`L` from input of size :math:`(N, L)`
BN_output = BN(input_text)
print('BN_output:')
print( BN_output)
print('BN_output.size()', BN_output.size())
print('*' * 20)
# LN = LayerNorm(input_text.size()[1:])
LN = LayerNorm(3)
LN_output = LN(input_text)
print('LN_output:')
print( LN_output)
print('LN_output.size()', LN_output.size())
if __name__ == '__main__':
show_difference_BN_LN()结果如下:
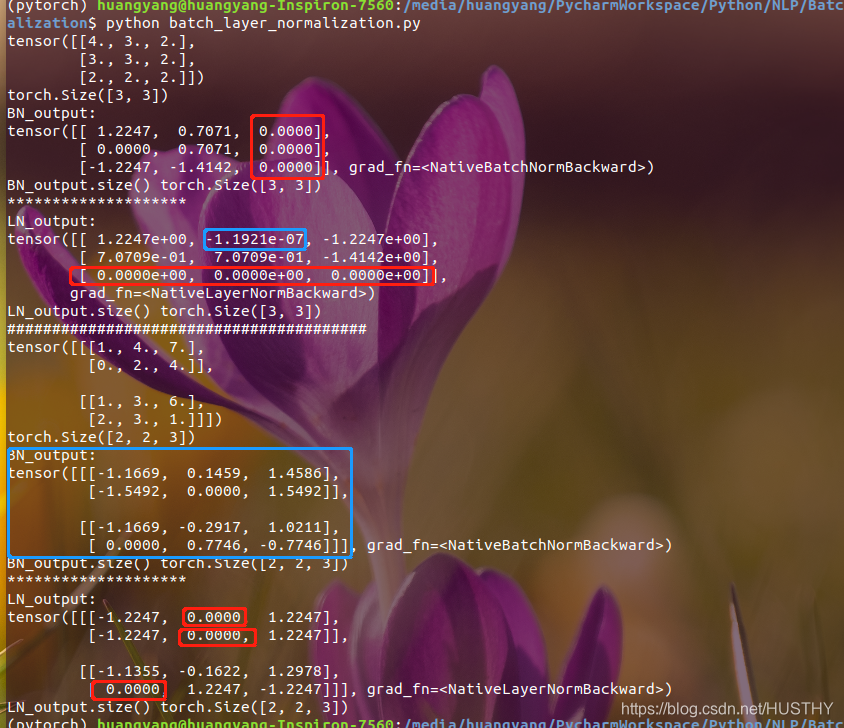
上图中,第一个torch.Size([3, 3])输入的结果用红色框表上的出现0的地方,和我想的一样,然后蓝色框出现的0不理解。
第二个输入torch.Size([2, 2, 3])的结果LN的输出出现0的地方很好理解,符合LN均值归一化;BN则是没有太看懂!有理解很清楚的人可以讲解一下!万分感谢!这个细节我还没有理解到位——表示好难。。。。。。。。
三、Bert、Transformer中为何使用的是LN而很少使用BN
其实这个问题是一个比较难的问题,我个人理解也是很有限的。参阅了很多资料,比较能接受2个解释。
3.1第一个解释
我们先把这个问题转化一下,因为Bert和Transformer基本都是应用到了NLP任务上。所以可以这样问:
为何CV数据任务上很少用LN,用BN的比较多,而NLP上应用LN是比较多的?
我们用文本数据句话来说明BN和LN的操作区别。
我是中国人我爱中国
武汉抗疫非常成功0
大家好才是真的好0
人工智能很火000
上面的4条文本数据组成了一个batch的数据,那么BN的操作的时候
就会把4条文本相同位置的字来做归一化处理,例如:我、武、大、人
我认为这里就破坏了一句话内在语义的联系。
而LN则是针对每一句话做归一化处理。例如:我是中国人我爱中国——归一化处理后,一句话内每个字之间的联系并没有破坏。从这个角度看,LN就比较适合NLP任务,也就是bert和Transformer用的比较多。
3.2第二个解释
1、layer normalization 有助于得到一个球体空间中符合0均值1方差高斯分布的 embedding, batch normalization不具备这个功能。
2、layer normalization可以对transformer学习过程中由于多词条embedding累加可能带来的“尺度”问题施加约束,相当于对表达每个词一词多义的空间施加了约束,有效降低模型方差。batch normalization也不具备这个功能。
NLP和CV的任务差别:
图像数据是自然界客观存在的,像素的组织形式已经包含了“信息”
NLP数据则是又embedding开始的,这个embedding并不是客观存在的,它是由我们设计的网络学习出来的。
通过layer normalization得到的embedding是 以坐标原点为中心,1为标准差,越往外越稀疏的球体空间中。这个正是我们理想的数据分布。
另外一词多义的表示中——简单来说,每个词有一片相对独立的小空间,通过在这个小空间中产生一个小的偏移来达到表示一词多义的效果。transformer每一层都做了这件事,也就是在不断调整每个词在空间中的位置。这个调整就可以由layer normalization 来实现,batch normalization是做不到的。
参考文章
batchNormalization与layerNormalization的区别















 840
840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









