







大规模模型训练通常使用单机集群进行,每台机器有8张GPU卡。集群中使用的机器型号包括8 种:A100、A800、H100、H800,以及可能即将推出的 {4, 8} L40S。以下是具有8个A100GPU的典型机器的硬件拓扑:

01 基本介绍 概念和术语
1. PCIe交换芯片
支持PCIe的CPU、内存、存储(NVMe)、GPU、网卡等设备都可以连接到PCIe总线或者专用的PCIe交换芯片上,实现互联互通。目前PCIe已经有五代产品,最新的是Gen5。
2. NVLink
NVLink是Nvidia 开发的有线串行多通道近距离通信链路。与PCI Express不同,一个设备可以由多个NVLink组成,并且设备使用网状网络而不是中央集线器进行通信。该协议于2014年3月首次发布,使用专有的高速信号互连 (NVHS)。
NVLink功能:
NVLink是指同一主机内不同GPU之间的高速互联方式。
它提供了短距离通信链路,确保数据包成功传输,并与PCIe相比提供更高的性能。
NVLink作为PCIe的替代品,支持多通道,链路带宽随着通道数量的增加而线性增加。
NV Switch在单个节点内,GPU使用NVLink以全网状配置互连,类似于主干叶(leaf-spine)拓扑。
NVIDIA 的专利技术。
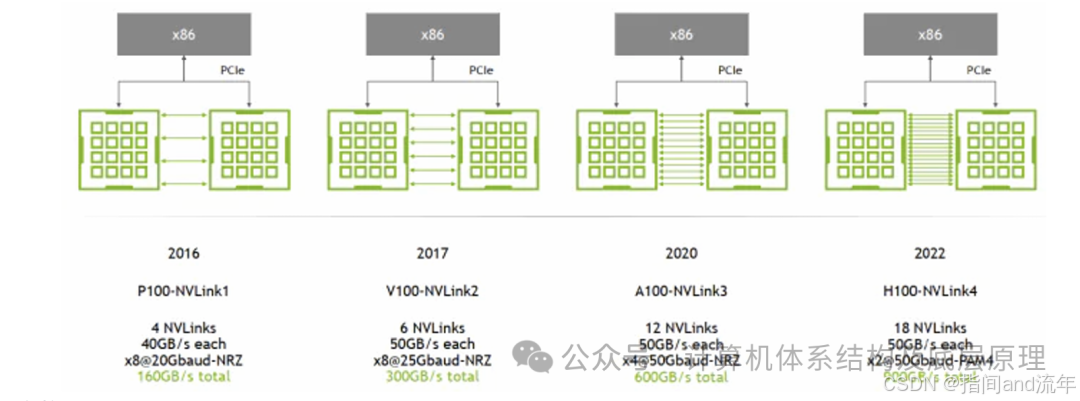
NVLink演进:第 1/2/3/4 代
主要区别在于单个NVLink链路中的通道数和每个通道的带宽(图中提供了两个方向)。
 <
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1003
1003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









