






1.5 window
滚动窗口+滑动窗口
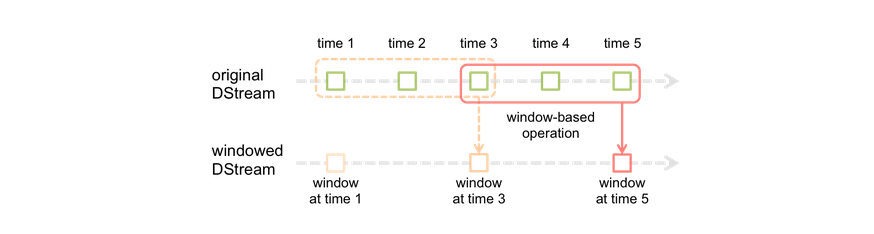
window操作就是窗口函数。Spark Streaming提供了滑动窗口操作的支持,从而让我们可以对一个滑动窗口内的数据执行计算操作。每次掉落在窗口内的RDD的数据,会被聚合起来执行计算操作,然后生成的RDD,会作为window DStream的一个RDD。比如下图中,就是对每三秒钟的数据执行一次滑动窗口计算,这3秒内的3个RDD会被聚合起来进行处理,然后过了两秒钟,又会对最近三秒内的数据执行滑动窗口计算。所以每个滑动窗口操作,都必须指定两个参数,窗口长度以及滑动间隔,而且这两个参数值都必须是batch间隔的整数倍。
-
红色的矩形就是一个窗口,窗口hold的是一段时间内的数据流。
-
这里面每一个time都是时间单元,在官方的例子中,每隔window size是3 time unit, 而且每隔2个单位时间,窗口会slide一次。
所以基于窗口的操作,需要指定2个参数:
window length - The duration of the window (3 in the figure)
slide interval - The interval at which the window-based operation is performed (2 in the figure).
-
窗口大小,个人感觉是一段时间内数据的容器。
-
滑动间隔,就是我们可以理解的cron表达式吧。
案例实现
package com.qianfeng.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 统计,截止到目前为止出现的每一个key的次数
* window窗口操作,每个多长M时间,通过过往N长时间内产生的数据
* M就是滑动长度sliding interval
* N就是窗口长度window length
*/
object Demo05_WCWithWindow {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("WordCountUpdateStateByKey")
.setMaster("local[*]")
val batchInterval = 2
val duration = Seconds(batchInterval)
val ssc = new StreamingContext(conf, duration)
val lines:DStream[String] = ssc.socketTextStream("qianfeng01", 6666)
val pairs:DStream[(String, Int)] = lines.flatMap(_.split("\\s+")).map((_, 1))
val ret:DStream[(String, Int)] = pairs.reduceByKeyAndWindow(_+_,
windowDuration = Seconds(batchInterval * 3),
slideDuration = Seconds(batchInterval * 2))
ret.print()
ssc.start()
ssc.awaitTermination()
}
}
1.6 SparkSQL和SparkStreaming的整合案例
Spark最强大的地方在于,可以与Spark Core、Spark SQL整合使用,之前已经通过transform、foreachRDD等算子看到,如何将DStream中的RDD使用Spark Core执行批处理操作。现在就来看看,如何将DStream中的RDD与Spark SQL结合起来使用。
案例:top3的商品排序: 最新的top3
这里就是基于updatestateByKey,统计截止到目前为止的不同品类下的商品销量top3
代码实现
package com.qianfeng.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.DStream
/**
* SparkStreaming整合SparkSQL的案例之,热门品类top3排行
* 输入数据格式:
* id brand category
* 1 huwei watch
* 2 huawei phone
*
*/
object Demo06_SQLWithStreaming {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("StreamingIntegerationSQL")
.setMaster("local[*]")
val batchInterval = 2
val duration = Seconds(batchInterval)
val spark = SparkSession.builder()
.config(conf)
.getOrCreate()
val ssc = new StreamingContext(spark.sparkContext, duration)
ssc.checkpoint("/Users/liyadong/data/sparkdata/streamingdata/chk-1")
val lines:DStream[String] = ssc.socketTextStream("qianfeng01", 6666)
//001 mi moblie
val pairs:DStream[(String, Int)] = lines.map(line => {
val fields = line.split("\\s+")
if(fields == null || fields.length != 3) {
("", -1)
} else {
val brand = fields(1)
val category = fields(2)
(s"${category}_${brand}", 1)
}
}).filter(t => t._2 != -1)
val usb:DStream[(String, Int)] = pairs.updateStateByKey(updateFunc)
usb.foreachRDD((rdd, bTime) => {
if(!rdd.isEmpty()) {//category_brand count
import spark.implicits._
val df = rdd.map{case (cb, count) => {
val category = cb.substring(0, cb.indexOf("_"))
val brand = cb.substring(cb.indexOf("_") + 1)
(category, brand, count)
}}.toDF("category", "brand", "sales")
df.createOrReplaceTempView("tmp_category_brand_sales")
val sql =
"""
|select
| t.category,
| t.brand,
| t.sales,
| t.rank
|from (
| select
| category,
| brand,
| sales,
| row_number() over(partition by category order by sales desc) rank
| from tmp_category_brand_sales
|) t
|where t.rank < 4
|;
""".stripMargin
spark.sql(sql).show()
}
})
ssc.start()
ssc.awaitTermination()
}
def updateFunc(seq: Seq[Int], option: Option[Int]): Option[Int] = {
Option(seq.sum + option.getOrElse(0))
}
}
1.7 SparkStreaming整合Reids
//将实时结果写入Redis中
dStream.foreachRDD((w,c)=>{
val jedis = new Jedis("192.168.10.101", 6379) //抽到公共地方即可
jedis.auth("root")
jedis.set(w.toString(),c.toString()) //一个key对应多个值,可以考虑hset
})














 150
150











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











