







Journey Learning: A New Paradigm for AI Training
——从捷径学习到旅程学习的范式转变
解读的进度报告来源:https://github.com/GAIR-NLP/O1-Journey
10.22 组会汇报的内容摘录。
很适合作为通用的工作流改善措施。
文章目录
- Journey Learning: A New Paradigm for AI Training
- 背景
- 旅程学习简介 O1 Journey Overview
- 旅程学习的特点
- 长思考(Long Thought)的构建
- 推理树的示例
- Q1: What does O1’s Thought Look Like?
- Q2: How Does Long Thought Work?
- Q3: How to Construct Long Thoughts?
- Q4: How to Construct Reward Models?
- Q5: How to Construct an On-policy Reasoning Tree?
- Q6: How to Derive a Long Thought from a Reasoning Tree?
- Q7: How to Evaluate our Trials?
- Q8: How to Train our Models?
- 实验结果
- 总结
背景
团队

- 该项目的核心开发团队主要由上海交通大学GAIR研究组的大三、大四本科生以及一年级博士生组成。
- 该项目由大型语言模型领域的顶尖研究科学家指导,其中包括来自纽约大学和MBZUAI的科学家。
使命感: Why We Created Progress Report
不得不说,真的很伟大的革新想法。
- 透明分享探索过程: 记录 O1 模型的探索过程,注重在试验中的失败与成功,减少全球范围内的试错成本。
- 推动开放协作文化: 为未来的人工智能研究和更广泛的科学探索建立新的范式。(非paper)
旅程学习简介 O1 Journey Overview
- 旅程学习 是一种新兴的AI训练方法,强调不仅仅依赖“捷径”获得结果,而是学习整个探索过程,包括试错、反思和回溯。
- 与传统的“捷径学习”相比,旅程学习更加关注AI系统的持续进步,能够应对复杂、动态和开放性问题。
- 作者的复刻探索 本身也可以看作一个旅程学习。
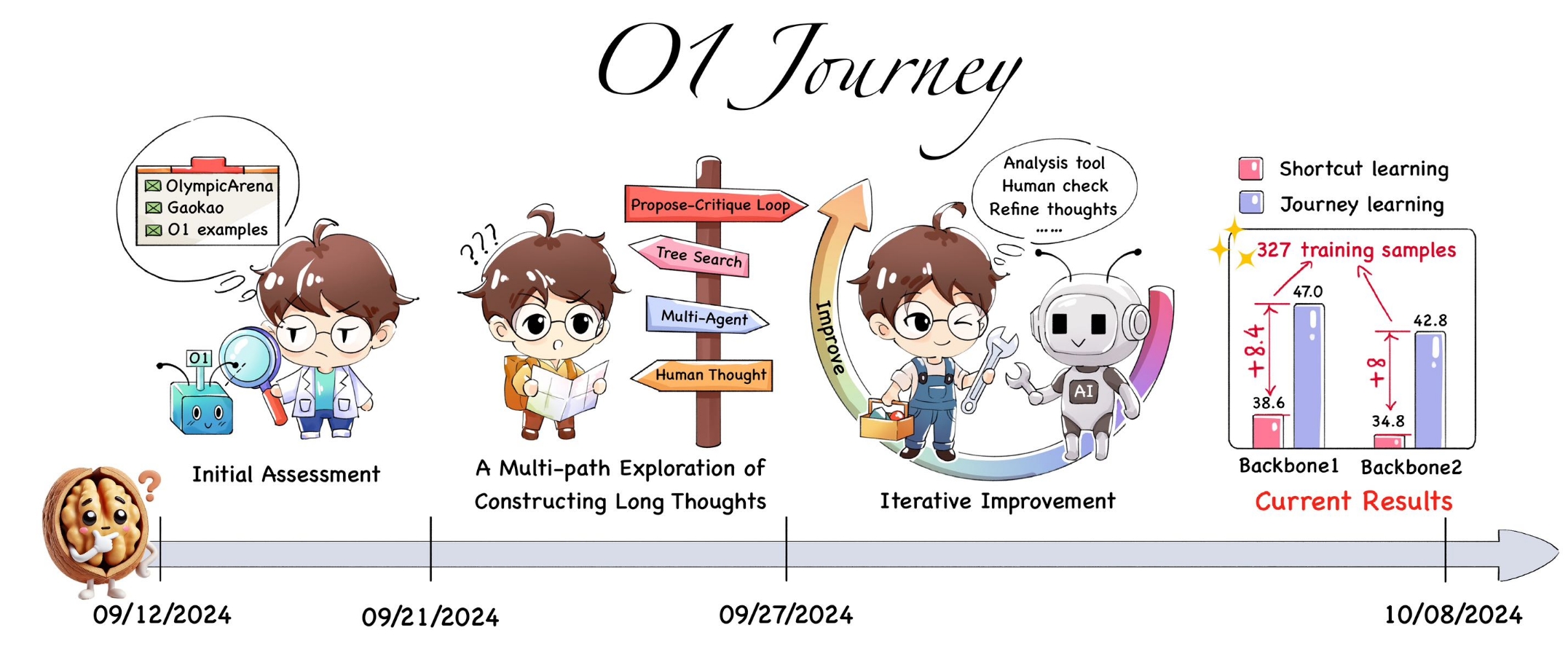
O1 Journey Process from Initial Assessment to Current Results
最近在10.16 他们还发布了一个327条记录的训练数据集:released the journey thought training dataset on Hugging Face
旅程学习的特点
O1 Exploration Journey (重点关注第一次的分支探索)
O1 Journey Process from Initial Assessment to Current Results
O1 模型探索的关键阶段:
- 前期准备 (9 月 12 日 - 9 月 19 日): 团队评估了 O1 模型的表现并组建团队,确定了探索方向和初步计划。
- 长思考构建 (9 月 21 日 - 9 月 23 日): 采用了多条路径来探索长思考的构建方法,重点在于树搜索、多代理系统以及人类推理记录。
- 迭代改进 (9 月 27 日 - 10 月 4 日): 通过实验和人类反馈,团队持续优化推理模型,并评估定量与定性结果。
- 进展报告 (10 月 8 日): 团队发布了最新进展报告,并启动了后续的高质量推理合作研究。
捷径学习 vs 旅程学习
下面的图很直观地展示了什么是旅程学习。其实像是(已有论文提及的思维树 + 面对过程监督学习)
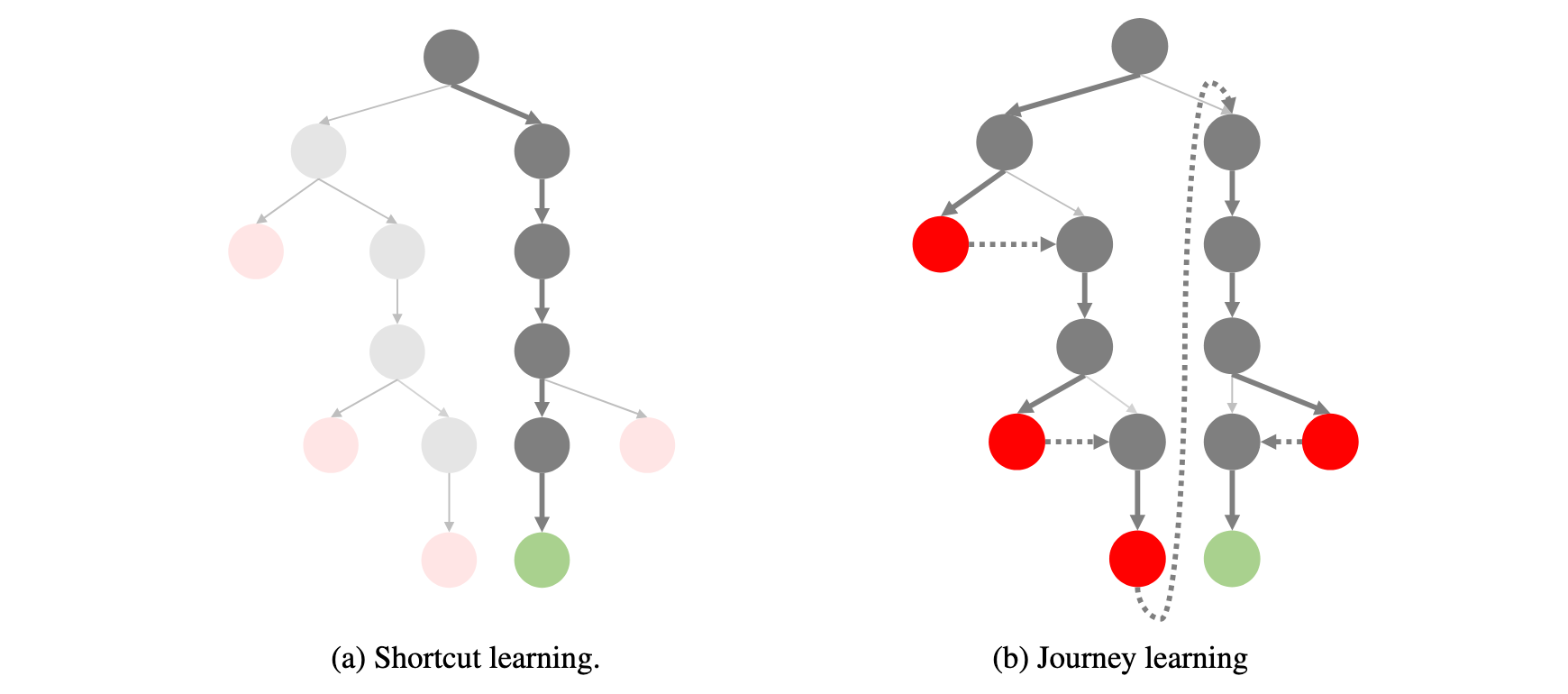
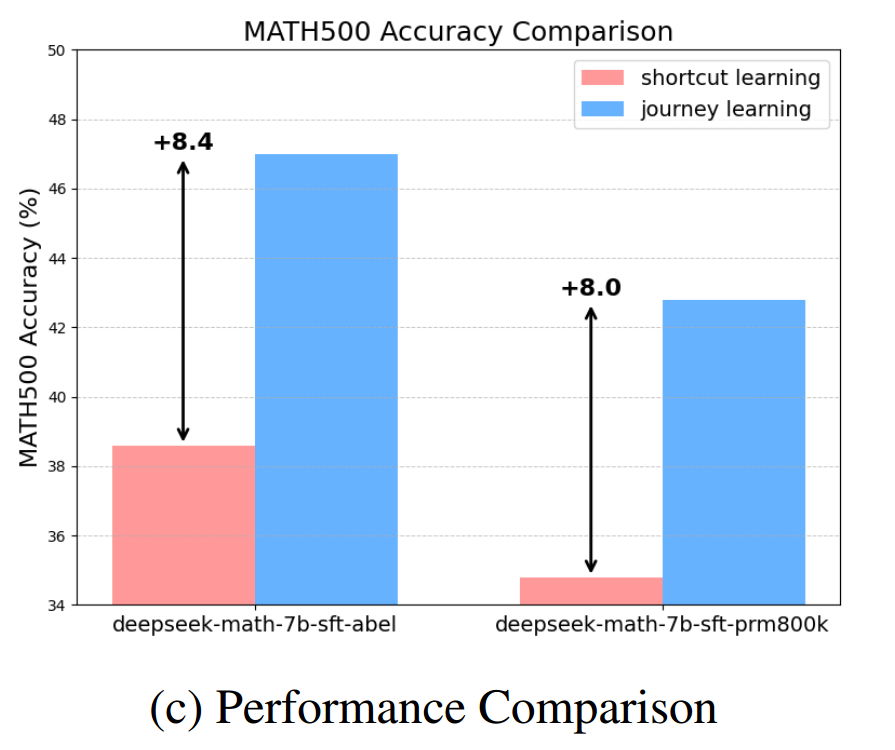
他们提出量化的结论是旅程学习相比捷径学习,仅靠327个长思考样本即可达到8%的提升。(但是需要注意,不是基础训练327个样本,两个对比的前面还有一轮监督学习。)
旅程学习的核心特征
- 深度推理能力: 通过多次尝试和回溯,模型可以建立更强的推理能力。
- 自我改进: 旅程学习允许模型从错误中学习,并在面对新问题时逐步改进。
- 强大的泛化能力: AI不再仅仅依赖于训练数据,而是通过探索和反思能够处理新的情况。
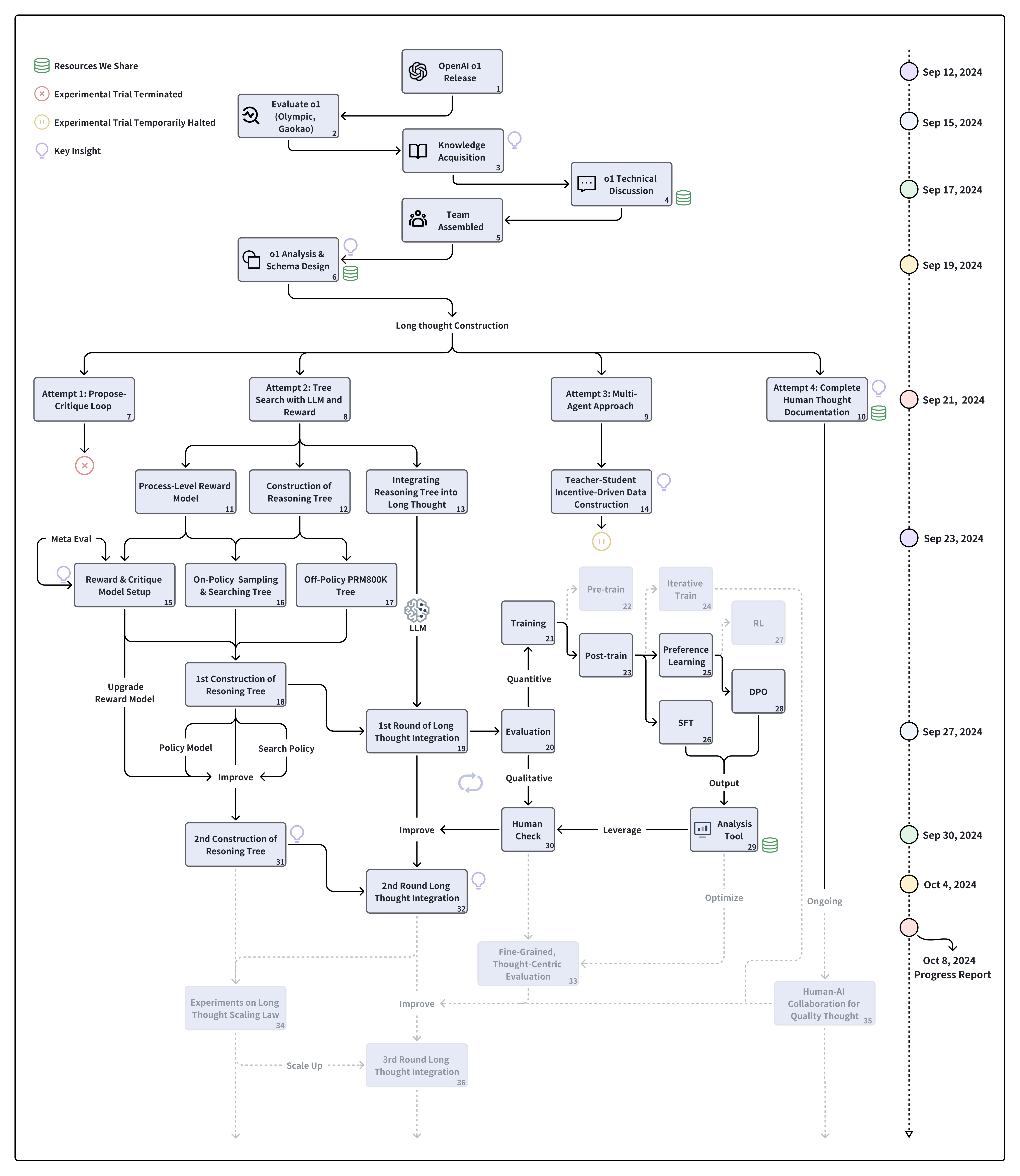
长思考(Long Thought)的构建
- 长思考是旅程学习的关键组成部分,指的是模型通过回溯和反思构建复杂的推理链。
- 使用方法包括:推理树、奖励模型、以及多代理系统协作来提高模型的推理深度。
推理树的示例
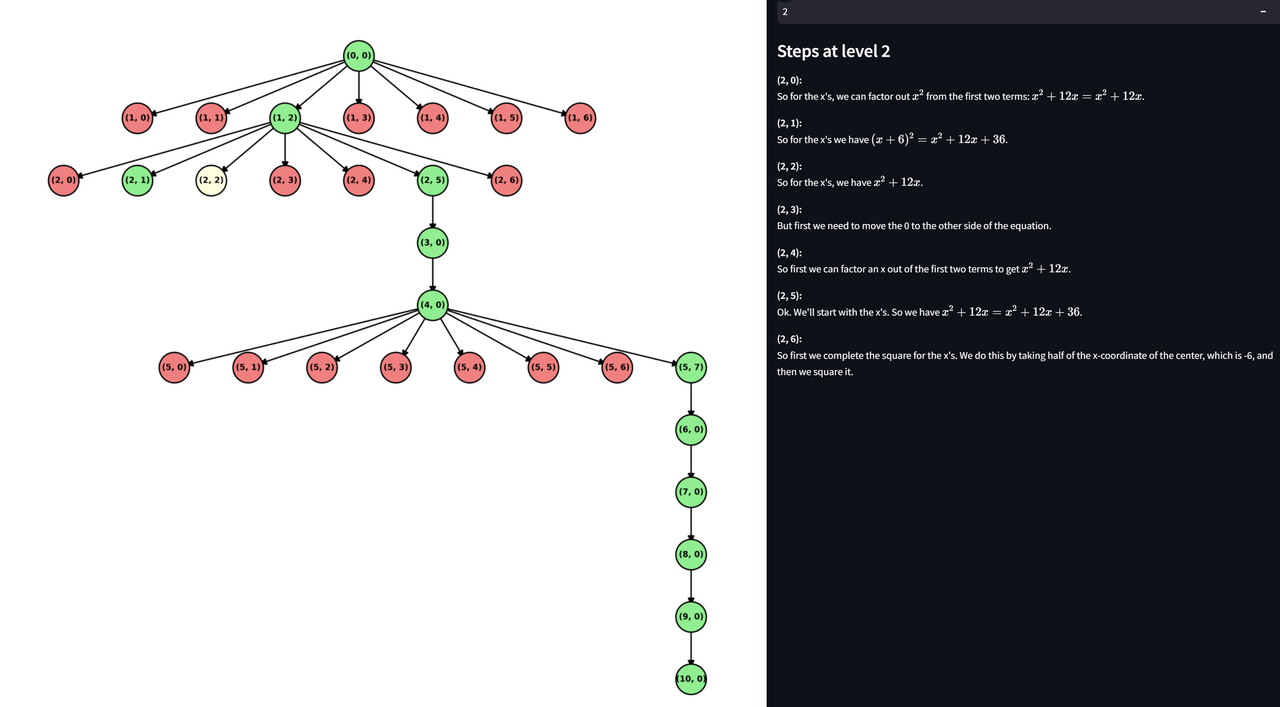
- 推理树的每个节点表示推理步骤。
- 错误的节点通过回溯修正,逐步构建完整的长思考链条。
后面这篇进度报告以提问的方式逐层讲述o1旅程学习。
Q1: What does O1’s Thought Look Like?
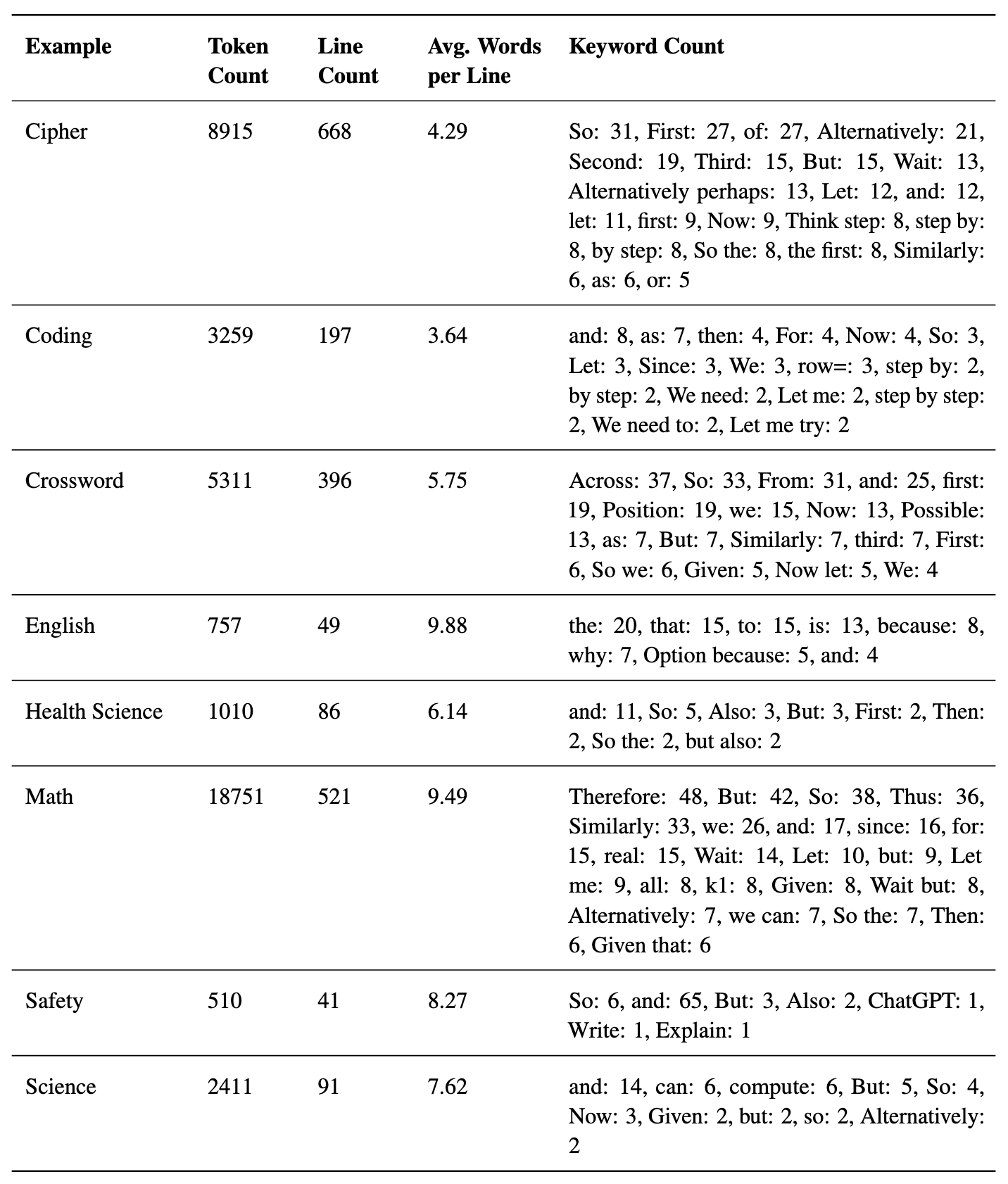
重点关注的是第二个核心点:通过ngram 词频统计频繁出现重要词语。其实有点像是英语写李华小作文的连接套路词。However、while、What’s more…
- Iterative Problem-Solving:
- 模型从定义函数开始,逐步探索相关表达式,将复杂的方程分解为更简单的部分。这反映了一种结构化且有条理的方法。
- Key Thought Indicators:
- 使用像“Therefore”(因此)来表示结论,“Alternatively”(或者)来探索不同路径,“Wait”(等待)来进行反思,“Let me compute”(让我计算)来进行计算转换的术语,突显了模型推理过程的不同阶段。
- Recursive and Reflective Approach:
- 模型经常重新评估和验证中间结果,使用递归结构确保一致性,这在严格的数学推理中尤为常见。
- Exploration of Hypotheses:
- 模型测试不同的假设,并随着获取更多信息调整其方法,展示在推理过程中灵活应对问题的能力。
- Conclusion and Verification:
- 最后,模型解方程并验证结果,强调在结束推理之前验证结论的重要性。
Q2: How Does Long Thought Work?
- Based on Journey Learning:
- O1 的长思考成功源于“旅程学习”,与传统捷径学习不同,旅程学习允许模型探索整个决策路径,模仿人类的解决问题过程。
- Multi-Path Exploration and Error Learning:
- 通过体验正确和错误的路径,O1 模型提升了错误处理与自我纠错能力,不仅能找到正确答案,还能理解如何得出答案。
- Simulating Human Cognition:
- O1 的学习过程模仿人类的认知,包括试错、反思和调整,这使得模型的推理过程具备高度的解释性,能够清晰解释如何从错误中恢复。
- Enhanced Adaptability and Explainability:
- 长思考不仅延长了模型的计算时间,它代表了一种更全面的类人思维探索,使 O1 能够处理更复杂的问题,提供可靠且可解释的答案,并在新挑战下表现出更好的适应性。
Q3: How to Construct Long Thoughts?
- Attempt 1: Tree Search with LLM and Reward
- 基于推理树的搜索和细粒度的奖励模型,模型能够回溯和反思错误的推理步骤,直到找到正确的路径,从而构建包含回溯和反思的长思考。
- Attempt 2: Propose-Critique Loop
- 让模型自主选择行为(如继续、回溯、反思、终止)构建推理树。当推理树无法到达正确答案时,通过负面信号引导模型反思并改正推理路径。
- Attempt 3: Multi-Agent Approach
- 通过多智能体辩论算法,一个智能体负责推理,另一个智能体负责批判,构建出更符合逻辑和反思行为的长思考数据集。
- Attempt 4: Complete Human Thought Process Annotation
- 记录人类解决推理问题的过程,通过反思和回溯产生高质量的长思考数据,与人类思维过程高度一致。
Q4: How to Construct Reward Models?
构建奖励模型的关键步骤如下:
- Granularity Definition:
- 首先,需要定义奖励模型的评估粒度。与仅关注最终结果不同,这里我们更注重模型在反思、回溯等认知过程中的能力提升。具体来说,我们使用微调数据,通过行号区分解决方案,确保模型能够更细粒度地进行评估。
- Reward Model Evaluation:
- 实施奖励模型的过程中,可以选择开源模型或专有模型。我们将不同奖励模型在 PRM800K 和 MR-GSM8K 子集上的表现进行了比较。结果显示,o1-mini 模型在多个数据集上的表现最佳。
- Pruning and Efficiency:
- 构建推理树的过程计算成本较高,因此需要使用奖励模型来修剪错误的推理步骤,提高效率。我们采用了束搜索(beam search)来选择得分最高的推理步骤用于下一轮迭代,从而显著减少了生成步骤的总数量。
Meta Evaluation Results
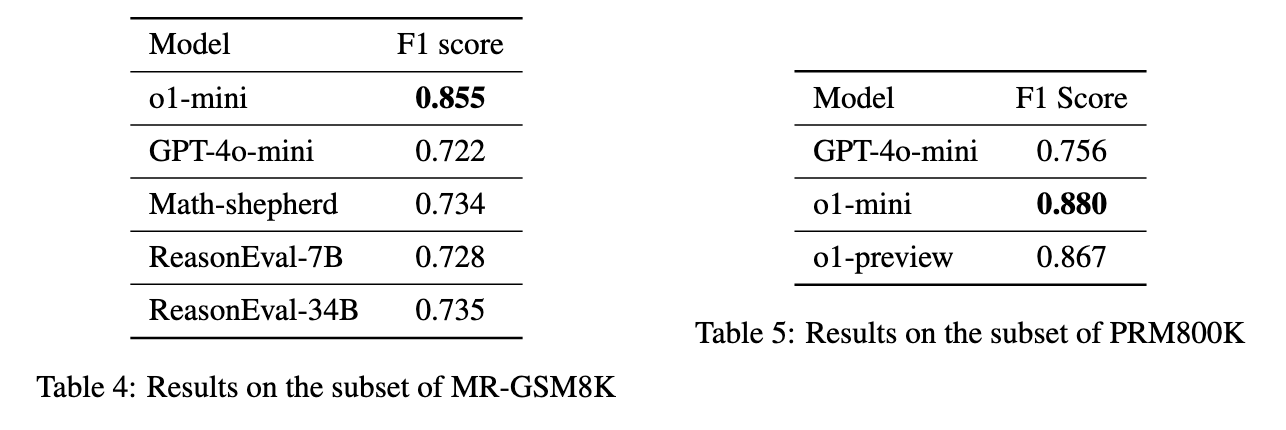
- 在 MR-GSM8K 数据集上,o1-mini 取得了 0.855 的 F1 分数,明显高于其他模型,如 GPT-4o-mini 的 0.722 和 Math-shepherd 的 0.734。
- 在 PRM800K 数据集上,o1-mini 再次领先,F1 分数达到 0.880,略高于 o1-preview 的 0.867 和 GPT-4o-mini 的 0.756。
Q5: How to Construct an On-policy Reasoning Tree?
- 策略推理树的构建:
- 使用策略模型 π \pi π,从问题的根节点开始生成推理树,每个节点表示推理的某一步,直到达到最大深度或找到解决方案。
- 策略模型与步骤分割:
- 通过 Abel 数据集微调的 DeepSeekMath-7B-Base 模型生成每一步推理,并使用该模型控制推理步骤的生成。
- 奖励模型与剪枝 (Pruning):
- 使用束搜索方法修剪错误的推理步骤(奖励最高的),减少计算成本。相比 Math-shepherd,o1-mini 提供了更精确的奖励信号,在处理复杂问题时表现更好。
Q6: How to Derive a Long Thought from a Reasoning Tree?
- 构建 ShortCut:
- 从推理树中识别仅包含正确答案和有效中间步骤的路径,多个正确路径可能并存。
- 推理树的遍历路径:
- 使用深度优先搜索(DFS)遍历推理树,记录正确路径和错误节点的推理步骤。引入约束条件简化搜索空间,保证有意义的试错探索。
- DFS 的约束条件:
- 在正确路径上的节点允许探索错误子节点,错误后回溯继续正确路径;不在正确路径上的节点随机选择子节点探索。
- 每个正确路径节点最多允许一次错误路径和一次正确路径的尝试。
- 构建长思考:
- 通过遍历路径构建初步长思考草案。使用 GPT-4o 改进草案,确保思维过程连贯流畅,同时保留所有反思与修正步骤。
Q7: How to Evaluate our Trials?
除去与自己的对比(捷径 vs 旅程)
好像没啥特别的评估方式,就是使用 streamlit 可视化 + 筛选。
Q8: How to Train our Models?
阶段 1:监督微调 (SFT)
- 1.1 ShortCut Learning:
- 在初始阶段,模型专注于学习正确答案和中间步骤。使用 Abel 和 PRM800K 数据集进行微调,共 6,998 个示例。
- 每个数据集训练 1 个 epoch,目的是让模型熟悉目标响应格式。
- 1.2 Journey Learning:
- 第二阶段,模型通过长思考的训练提升反思、回溯和纠正的能力。使用 327 个长思考示例进行微调,并与 ShortCut 进行对比。
- 每个数据集训练 3 个 epoch,旨在让模型深入理解复杂推理链条中的错误与纠正。
阶段 2:直接偏好学习 (DPO)
- 使用 MATH 数据集生成偏好对,使用 DPO 损失训练模型。每个问题生成 20 个响应,随机选择 5 个正响应和 5 个负响应进行偏好对训练。
- DPO 训练允许模型通过对正确与错误答案的比较进行学习。
- 不过这个效果不显著。
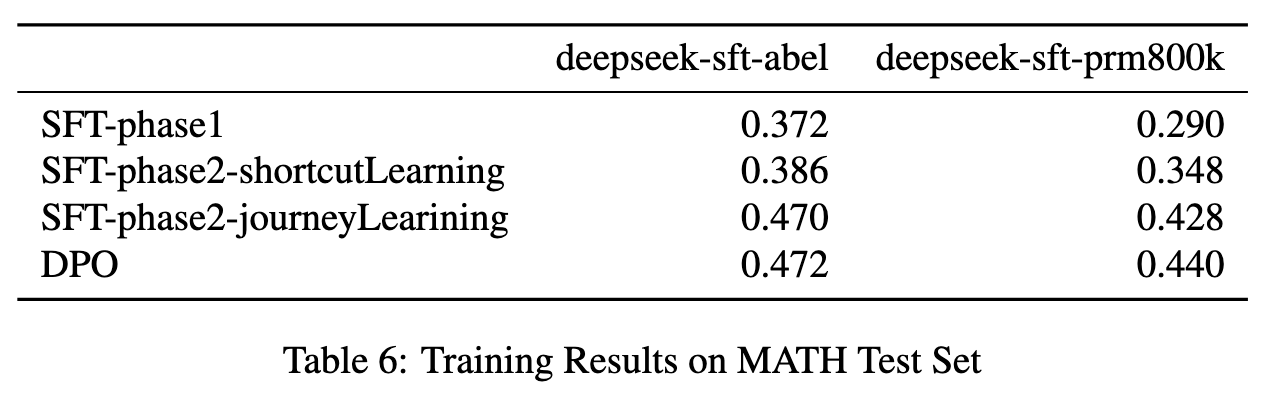
实验结果
- 旅程学习在深度推理任务中表现出色,DeepSeek-SFT-Abel 和 DeepSeek-SFT-PRM800K 模型分别提升 +8.4% 和 +8.0%。
- DPO 改进较温和,未来计划进一步探索偏好学习与强化学习。
总结
旅程学习是一种革命性的方法,它超越了传统的捷径学习,提供了更强的泛化能力和推理深度。
- 旅程学习已成功应用于复杂数学问题的求解,以及开放式问题的推理。
- 通过反思、回溯和错误学习,使得AI系统更加接近人类推理模式。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











