






 该教程详细介绍了如何修改MMDetection框架中的VOC.py和class_names.py以适应自定义数据集,包括重新编译、配置文件修改(如修改SSD配置、数据处理、模型结构、优化器和学习率策略),以及训练和测试命令行的使用。重点在于理解并调整配置文件以匹配个人数据集的类别数量和尺寸需求。
该教程详细介绍了如何修改MMDetection框架中的VOC.py和class_names.py以适应自定义数据集,包括重新编译、配置文件修改(如修改SSD配置、数据处理、模型结构、优化器和学习率策略),以及训练和测试命令行的使用。重点在于理解并调整配置文件以匹配个人数据集的类别数量和尺寸需求。
一、修改voc.py和class_names.py
./mmdet/datasets/voc.py 
此处代码改为自己数据集的类别,以及./mmdet/core/evaluation/class_names.py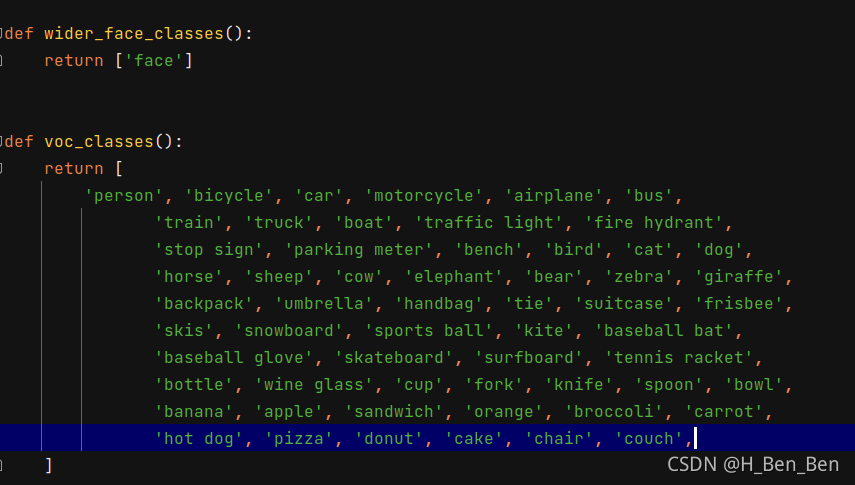
也需要将类别改为自己的数据集的类别。
【注意】修改完voc.py和class_names.py之后,需要重新编译一下,cd进入mmdetection文件夹,输入
python setup.py install至此,适合自己的voc数据集格式修改好了。
二、修改配置文件config
config文件夹中主要有_base_和各个目标检测框架的文件夹。
2.1、修改目标检测框架代码
在训练以及测试时使用的是对应目标检测框架下的程序,以SSD为例,如下图所示:
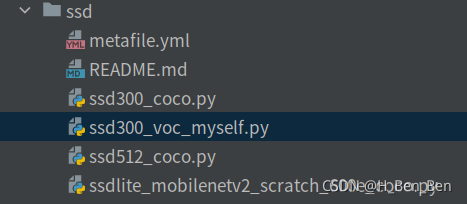
先复制一份代码,比如ssd300_coco.py,并按照自己的习惯命名即可。
进入代码,可以将除了_base_的部分都删去,这度利配置文件的补充,因为原代码里用的coco格式的,所以最后注释掉,并且 '../_base_/datasets/coco_detection.py'改为'../_base_/datasets/voc0712.py’,schedule_1x.py和default_runtime.py在此处不用修改,修改源文件。
可得结果为:
_base_ = [
'../_base_/models/ssd300_myself.py', '../_base_/datasets/voc0712.py',
'../_base_/schedules/schedule_2x.py', '../_base_/default_runtime.py'关于这四个文件的修改在2.2中讲解。
2.2、修改_base_内的文件
_base_的目录如下所示:
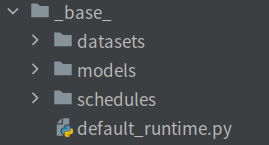
分别对应了2.1中的四个文件。
2.2.1、datasets
datasets为数据处理的部分,本处使用的是voc数据集,故打开voc0712.py。在train_pipeline = [ ]和test_pipeline=[ ]字典中,修改Resize,改为如下:
dict(type='Resize', img_scale=(300, 300), keep_ratio=False)img_scale=(300,300),keep_ratio=False否则在计算时会有报错,因为SSD是和输入图片尺寸有关系的框架。
2.2.2 、models
复制一个ssd.py重新命名,将num_class改为自己数据集的个数,如:
bbox_head=dict(
type='SSDHead',
in_channels=(512, 1024, 512, 256, 256, 256),
num_classes=3, # 此处为类别数2.2.3、schedules
此文件夹为优化器和学习率的策略,根据自身需要修改即可。
2.2.4、default_runtime.py
这是默认的一些设置,如运行记录log等的格式,可以使用tensorboard,dict(type='TensorboardLoggerHook'),这一行取消注释即可。
值得一提的是,下面的代码为保存的.pth文件的间隔,根据需要进行修改。
checkpoint_config = dict(interval=10) # 设置保存的间隔三、训练与测试
训练命令行:
python ./tools/train.py configs/ssd/ssd300_myself.py --work-dir work_dirs/ssd300_myself--work-dir参数为运行文件保存的位置
测试命令行:
python ./tools/test.py configs/ssd/ssd300_myself.py work_dirs/ssd300_myself/latest.pth --eval mAP--eval mAP是评价标准为mAP。

















 338
338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









