







周末总结
周末花6.5k的4060ti主机到家了,配好了和女朋友一起玩了两天帕鲁,真好玩!
玩完开始上班!
今天,上午先看三篇paper,然后下午继续1日计划的工作
文章阅读
文章一:SciGLM: Training Scientific Language Models with Self-Reflective Instruction Annotation and Tuning
https://github.com/THUDM/SciGLM
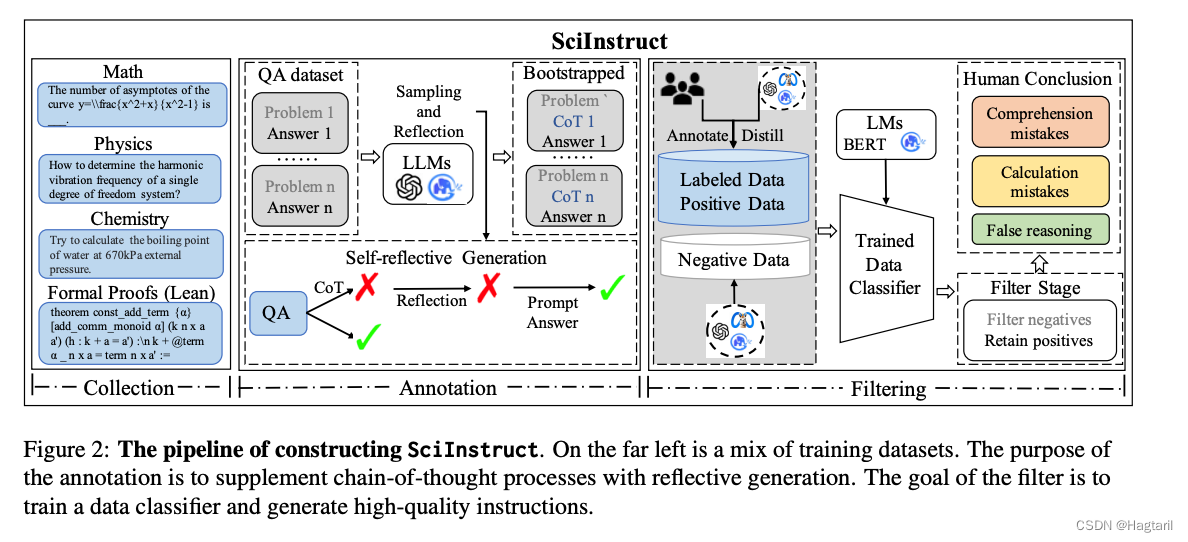
通过自动纠错生成SciInstruct数据集,在SciInstruct数据集上训练ChatGLM得到优于baseline(ChatGLM)的模型。
-
“从互联网上获得的用于科学问题的指令数据的规模远小于其他任务。科学内容通常需要更高级别的专业知识才能创建,且大多数高质量信息经常受到知识产权的保护。我们能合法访问的大多数数据只包含问题-答案(QA)对,而没有详细的思考链条推理步骤。然而,仅仅训练大型语言模型(LLMs)使用QA对会导致非常糟糕的结果,甚至损害它们的通用语言能力。为了获得高质量的推理步骤作为指令(I),并创建问题-指令-答案(QIA)对,我们提出了一个自我反思的指令标注框架,要求LLM自主地标注、评价和修正推理步骤,几乎不需要人为干预。具体来说,LLM首先尝试仅根据问题(Q)生成推理步骤和答案;然后,对于那些答案预测错误的输出,我们要求LLM自身识别错误类型,基于此来解决错误并修正输出。最后,我们提供给LLM正确的答案,以完成它们的标注指令。这样一个自我反思的标注框架完全利用AI而非人类来收集指令,同时通过仔细的答案检查和LLM自我反思,保证质量并解决现有LL在这里插入图片描述
M的潜在错误。”

-
由光学字符识别(OCR)提取的真实数据和由自反射框架生成的指令仍然可能包含错误。因此,对未细化的数据进行处理,获得高质量的数据,是提高模型性能的关键。**为了创建高质量的指令并过滤掉噪声数据,我们选择特定的标准问题和答案作为正样本,并使用llm生成相应的负样本。然后可以利用这些样本来训练数据分类器。在整合自我反思标注产生的问题和答案并进行过滤后,我们构建了scidirective,一个包含科学信息的综合数据集,用于微调。**在这项工作中,我们选择双语ChatGLM (Du et al., 2022;Zeng et al., 2022)系列模型作为主干。ChatGLM系列模型是一个开源的对话预训练模型,具有流畅的对话和低部署障碍。通过在scidirective上对ChatGLM系列模型进行微调,得到SciGLM模型。
文章二:LlaSMol: Advancing LLMs for Chemistry with SMolInstruct
https://github.com/OSU-NLP-Group/LLM4Chem
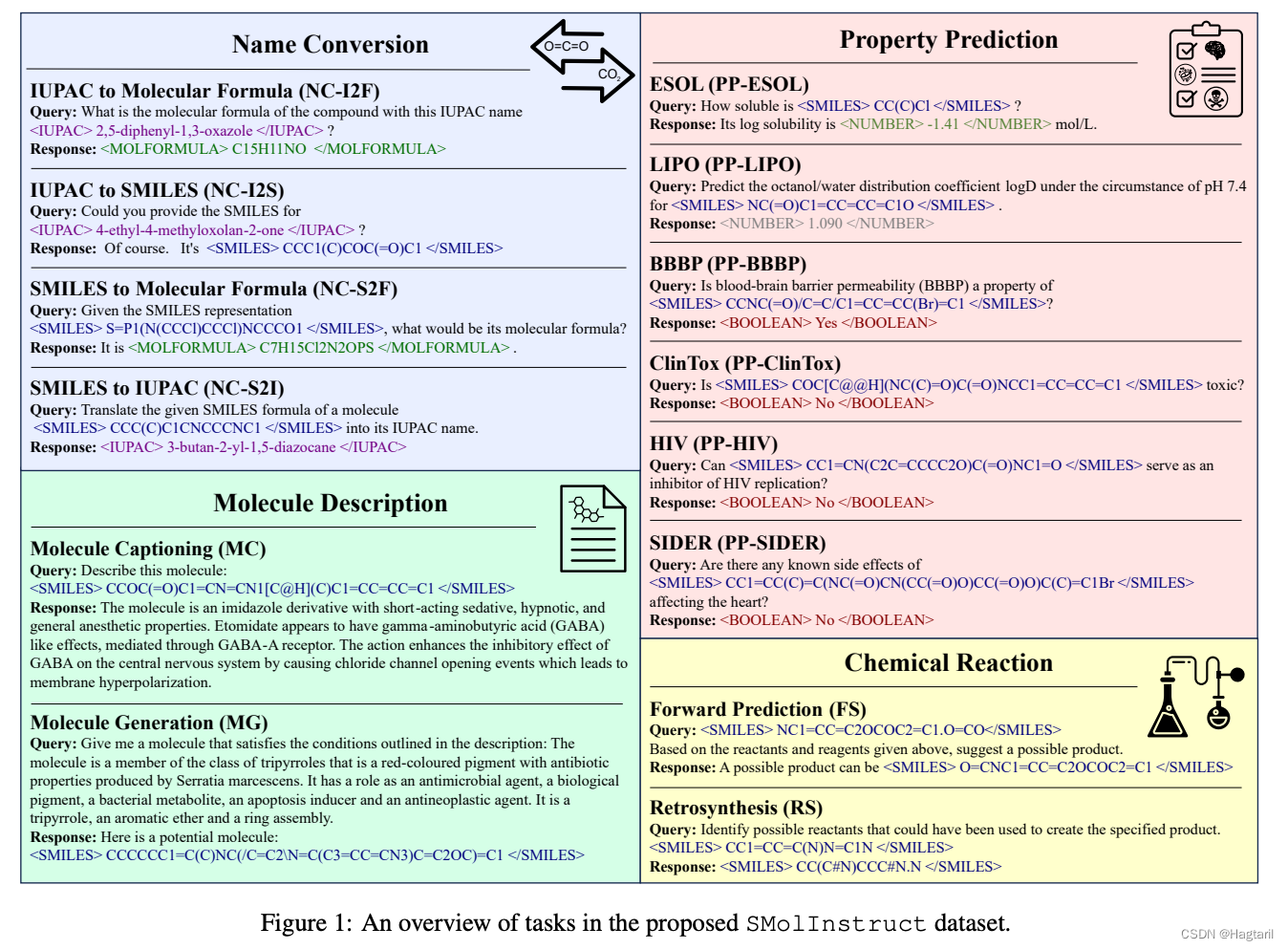
收集和制造了一个总大小3M的指令微调数据集。在开源模型中测试结果是Mistral基座模型科学理解能力最强,所以用Mistral作为基座。
文章三:ChemLLM: A Chemical Large Language Model
将结构化科学内容转为更贴近LLM-Chat的corpora以避免对预训练大模型能力的破坏。
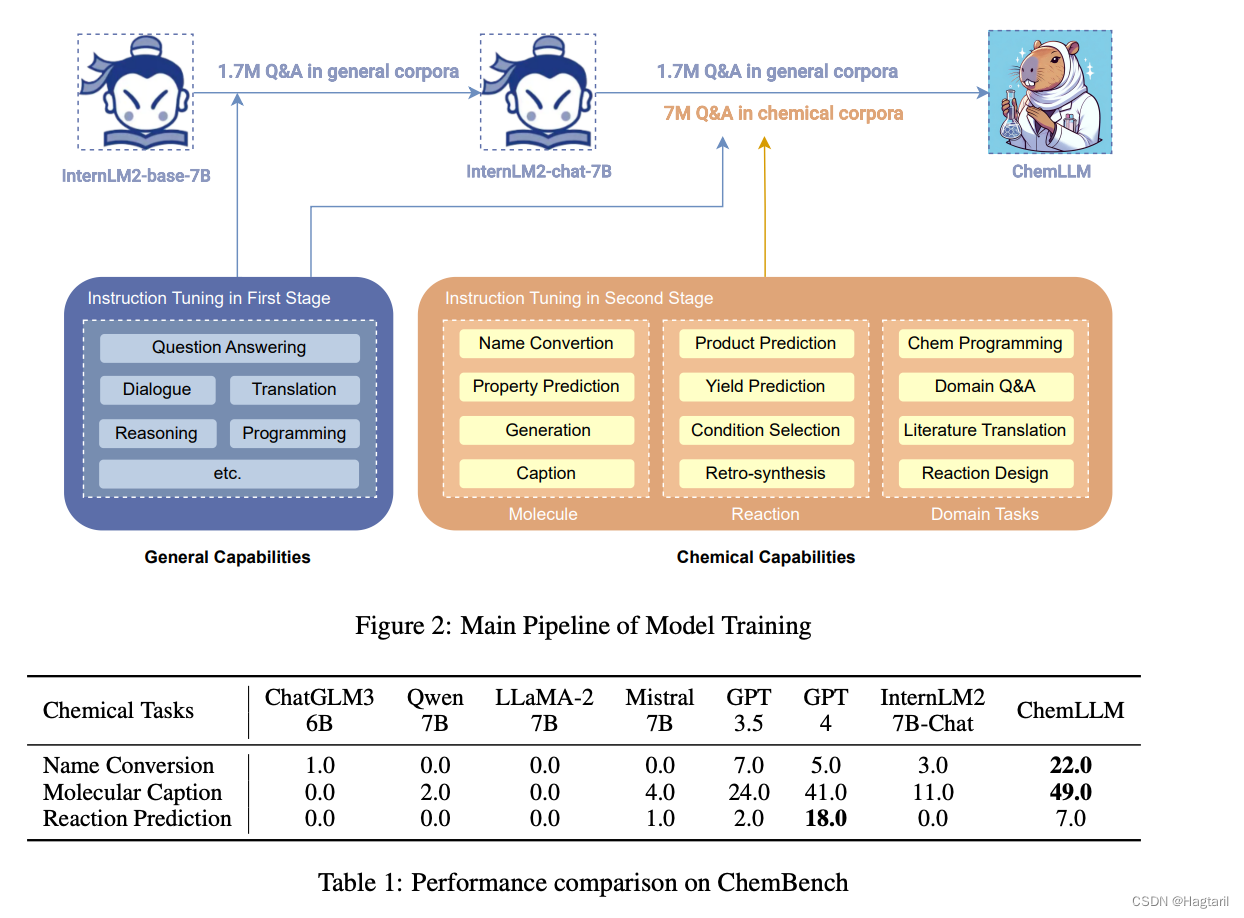
主要在name conversion, molecular caption, and reaction prediction三个方面进行测试。从这个表格结果来看,微调模型和GPT4的差距集中体现在反应预测上。















 1099
1099











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









