







1. map 的用法: 替代for循环,辅助加速
map(function, list)
简写
map(lambda x: x ** 2, [1, 2, 3, 4, 5]) # 使用 lambda 匿名函数
[1, 4, 9, 16, 25]
提供了两个列表,对相同位置的列表数据进行相加
>>> map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10])
[3, 7, 11, 15, 19]
以def写复杂函数

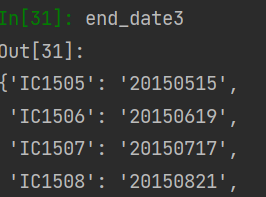
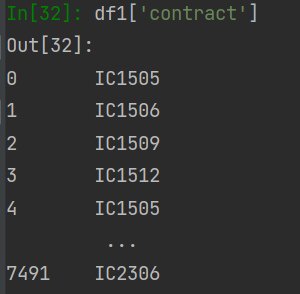
pd.Series(map(lambda x: str(end_date3[x]), list(df1['contract'])))
end_date
df1['contract']
最终结果:

map函数的用法:
def multiply(x):
return (x*x)
def add(x):
return (x+x)
funcs = [multiply, add]
for i in range(5):
value = map(lambda x: x(i), funcs)
print(list(value))
# Output:
# [0, 0]
# [1, 2]
# [4, 4]
# [9, 6]
# [16, 8]
2. 制造dict和key
pos_signal = {}
3. 善用if in
def find_index_constitutes(code):
key = str(code[0]) + '|' + str(code[1])
if key in index_htable:
return index_htable[key]
else:
return '其他'
4. 多进程
pool.join 是按顺序输出。
5、 For 循环基本用法
将所有的数据输出:
res=[]
res=pd.DataFrame() 【如果是矩阵】
for i in ... #循环处理文档的每一行
.........
line=..... #line为每一行的处理结果
res.append(line) #如果前面加上res=可能会报错
print(res) #res就是所需要的结果
For 循环的参数: for i in range( len(X)):
range:(start, stop[, step]) 算前不算后
range(10)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
range(1, 11)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
range(0, 30, 5)
[0, 5, 10, 15, 20, 25]
size:len(X)
输出行数:x.shape[0]
输出列数:x.shape[1]
将dataframe拼接:
result = []
for t in dates:
result.append(func(t))
print (pd.concat(result, axis=1))
将list中多个dataframe拼接成dataframe,先append,再concat
for t in dates:
expseason2.append(expseason1)
expseaso3=pd.concat(expseason2,axis=0)
6. 反向循环
for t in reversed(range(col - 1)):
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
7. iterrows 循环 :行循环
创造样例数据
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(2,2), columns = list('AB'))
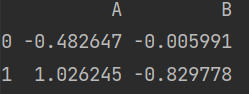
for x, y in df.iterrows():
print(x)
print(y)

y['A']
8. enumerate 循环: 行列名称
for x, y in df. enumerate():
print(x)

print(y)

9. list中简化for 循环:
重复
date = [1,2,3]
[x for x in date for i in range(3)]

累加+for简化:
n=index_price.shape[0]
count=[0 for x in range(0,n)]
10. 通过 dict 制造key,搜索双标签对应的值
index_htable={}
for _,row in idc.iterrows(): #按行循环
key = str(row[u'股票代码']) + '|' +str(row[u'日期']) #根据不同 的索引重新制作键值
value = str(row[u'指数代码'])
if value == '000300.SH':
value = '沪深300'
else:
value = '其他'
index_htable[key] = value # 对值重新定义索引和名称
def find_index_constitutes(code):
key = str(code[0]) + '|' + str(code[1])
if key in index_htable: # 搜寻键对应的值
print('found key',key,index_htable[key])
return index_htable[key]
else:
return '其他'
11. 使用生成器占用更少资源。yield
# generator version
def fibon(n):
a = b = 1
for i in range(n):
yield a
a, b = b, a + b
for x in fibon(1000000):
print(x)
用这种方式,我们可以不用担心它会使用大量资源。然而,之前如果我们这样来实现的话,这也许会在计算很大的输入参数时,用尽所有的资源
def fibon(n):
a = b = 1
result = []
for i in range(n):
result.append(a)
a, b = b, a + b
return result
def generator_function():
for i in range(3):
yield i
使用next() 获取下一个元素。
gen = generator_function()
print(next(gen))
# Output: 0
print(next(gen))
# Output: 1
print(next(gen))
# Output: 2
print(next(gen))
# Output: Traceback (most recent call last):
# File ""
12. iter: 迭代
my_string = "Yasoob"
my_iter = iter(my_string)
next(my_iter)
# Output: 'Y'
13. reduce
当需要对一个列表进行一些计算并返回结果时,Reduce 是个非常有用的函数。举个例子,当你需要计算一个整数列表的乘积时。通常在 python 中你可能会使用基本的 for 循环来完成这个任务。
from functools import reduce
product = reduce( (lambda x, y: x * y), [1, 2, 3, 4] )
# Output: 24
14. filter过滤
number_list = range(-5, 5)
less_than_zero = filter(lambda x: x < 0, number_list)
print(list(less_than_zero))
# Output: [-5, -4, -3, -2, -1]















 1654
1654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









