







回归
1. 模型建立
- 模型:这里为线性模型;
- 衡量模型好坏:损失函数;

- 训练模型目标:最小化损失函数,优化方法求解优化问题;

2. 模型评价
- 训练集、测试集上的平均误差:主要关注测试集上的平均误差;
3. 模型优化
3.1 增大模型复杂度
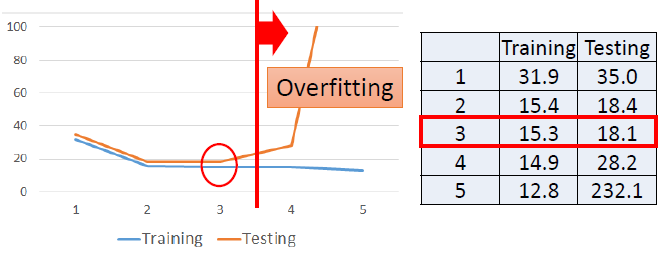
- 随着模型复杂度的增加,训练集上的平均误差逐渐减小,测试集上的平均误差先减小后增大,过于复杂的模型会出现过拟合现象;
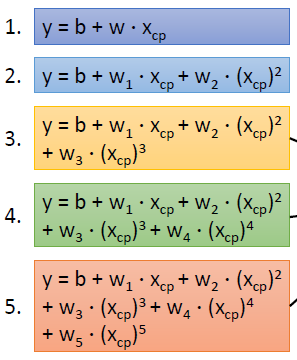
3.2 考虑隐变量
-
不同的隐变量取值,建立不同的模型;
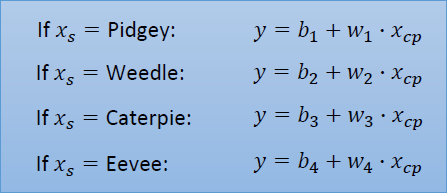
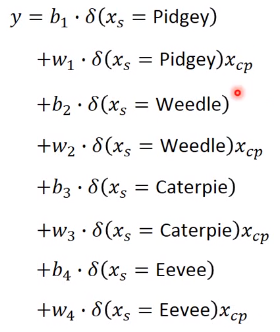
其中 δ \delta δ为示性函数。 -
可在此基础上进一步增加模型复杂度;
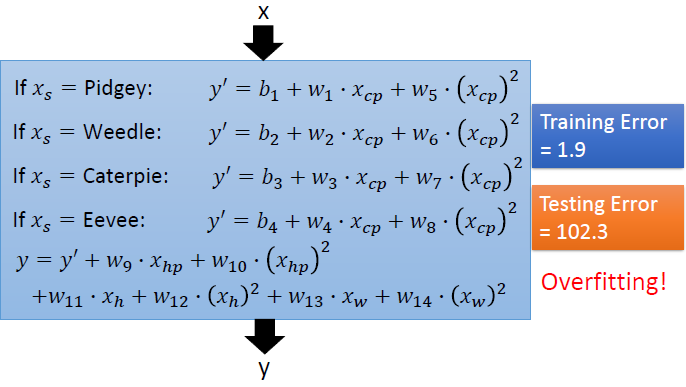
3.3 正则化
- 线性模型为例:惩罚较大的系数项,希望获得较小的系数项;
- 数据有噪声,系数较小的模型受噪声的影响较小。

- 正则化参数
λ
\lambda
λ:平衡拟合优度和惩罚项

4. 模型选择
误差的来源:偏差与方差
- 简单的模型受样本数据影响小,估计量的偏差大、方差小;复杂模型相反;

- 偏差、方差不能同时达到最小;

偏差太大、欠拟合
- 增加特征;
- 增加模型复杂度。
偏差太大、欠拟合
- 增加数据;
- 正则化。
二分类
分类任务实例
- 信用评级
- 医疗诊断
- 手写字体识别
- 人脸识别
分类模型框架
- 线性模型做分类存在问题:

- 理想的分类模型框架:

1. 朴素贝叶斯模型(生成模型框架)
-
模型

-
先验概率

-
Probability from Class:考虑两个特征,即 x x x是二维的;假设数据来自高斯分布,不同类别的数据来自不同的高斯分布, P ( x ∣ C 1 ) ∼ N ( μ 1 , Σ 1 ) P(x|C_1)\sim \mathcal{N}(\mu^1,\Sigma^1) P(x∣C1)∼N(μ1,Σ1), P ( x ∣ C 2 ) ∼ N ( μ 2 , Σ 2 ) P(x|C_2)\sim \mathcal{N}(\mu^2,\Sigma^2) P(x∣C2)∼N(μ2,Σ2);极大似然法求出参数,

-
分类

-
精度分析:决策边界是个曲线,精度不是很高

-
模型优化:减少参数,假设两个类别共用一个协方差

优化结果:精度提升,决策边界是线性的

模型特点:为什么共用协方差阵是分类边界是线性的
- 当两个类别共用一个协方差时,
∃
w
,
b
\exist w,b
∃w,b使得
P
(
C
1
∣
x
)
=
σ
(
w
T
+
b
)
P(C_1|x)=\sigma(w^T+b)
P(C1∣x)=σ(wT+b)




2. 逻辑回归(判别模型框架)
- 模型:直接估计
w
,
b
w,b
w,b

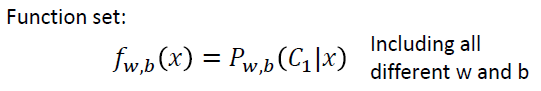

- 损失函数:最小化负对数似然函数
⟺
\Longleftrightarrow
⟺最小化交叉熵损失函数

- 梯度下降求解
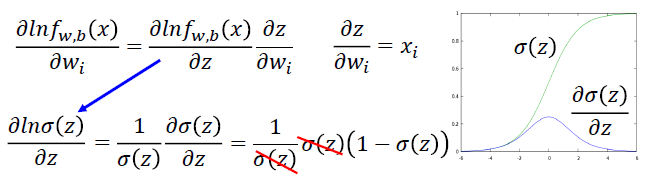
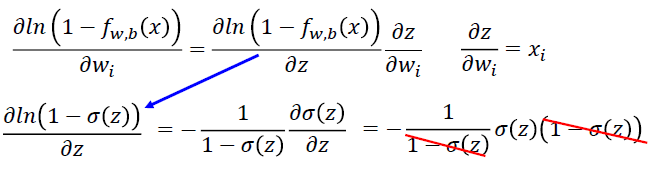

损失函数为什么不选残差平方和
- 残差平方和函数的梯度在距离最优值很远的点处也很小



逻辑回归的局限
- 决策边界是线性,不能对“异或”问题准确分类

- 解决方法:特征变换(诸如SVM中核技巧)


逻辑回归与线性回归的区别

3. 生成模型与判别模型
- 朴素贝叶斯模型中通过估计
μ
,
Σ
\mu,\Sigma
μ,Σ进而计算得到的
w
,
b
w,b
w,b与逻辑回归中直接估计得到的
w
,
b
w,b
w,b不同:生成模型中对概率分布作了假设,判别模型中没有作任何假设

生成模型优势
- 生成模型对概率分布作了假设,受数据的影响较小,
- 不需要太大的数据集,
- 对于噪声数据更具有稳健性;
- 先验概率 P ( C 1 ) P(C_1) P(C1)与依赖类别的概率 P ( x ∣ C 1 ) P(x|C_1) P(x∣C1)可以通过不同的数据集来估计。
多分类

















 1450
1450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









