







1. TensorFlow数据流图
TensorFlow数据流图是一种声明式编程范式

数据流图/计算图
- TensorFlow数据流图描述了算法模型的计算拓扑,其中的各个操作(节点)都是抽象的函数映射或数学表达式;
- 换句话说,数据流图本身是一个具有计算拓扑和内部结构的“壳”,在用户向数据流图填充数据前,图中并没有真正执行任何计算。

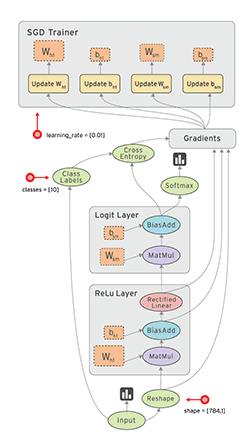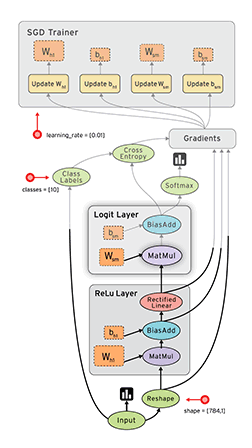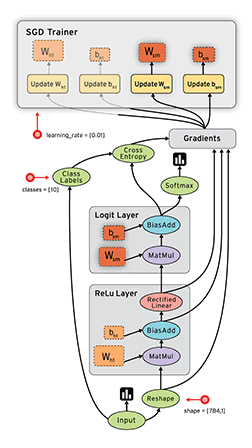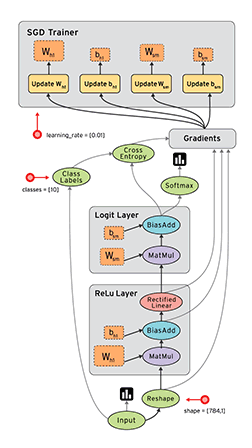
计算图是一个有向图,由以下内容组成: - 一组节点,
- 计算节点:无状态的计算或控制操作,主要负责算法逻辑表达或流程控制,如逻辑操作、神经网络的操作、规约操作等
- 存储节点:有状态的变量操作,通常用来存储迭代更新的模型参数
- 数据节点:数据的占位符操作,用于描述图外输入数据的属性
- 一组有向边,TensorFlow有两种边
- 常规边(实线):代表数据依赖关系。一个节点的运算输出成为另一个节点的输入,两个节点之间有tensor流动(值传递)
- 特殊边(虚线):不携带值,表示两个节点之间的控制相关性。比如,happens-before关系,表示源节点必须在目的节点执行前完成执行
数据流图优势
- 并行式计算快:可执行队列和拓扑排序的思想
- 分布式计算快(CPUs,GPUs,TPUs)
- 预编译优化(XLA)
操作
- 计算图中的节点就是操作:加法、乘法、构建变量的初始值……
- 操作时模型功能的实际载体
- 操作的输入和输出是张量或操作(函数式编程)
- 每个运算操作都有属性,在构建图的时候需要确定下来
- 操作可以和计算设备绑定,指定操作在某个设备上执行,比如,这个操作是运行在GPU,那个操作是运行在CPU上的
- 操作之间存在顺序关系,这些操作之间的依赖 就是“边”
TensorFlow典型计算和控制操作

张量/Tensor
在数学里,张量是一种几何实体,广义上表示任意形式的“数据”。张量可以理解为0阶标量、1阶向量和2阶矩阵在高维空间上的推广,张量的阶描述它表示数据的最大维度。
在TensorFlow中,张量(Tensor)表示某种相同数据类型的多维数组。因此,张量有两个重要属性:数据类型(如浮点数、整型、字符串)、数组形状(各个维度的大小)。
- 张量是用来表示多维数据的;
- 张量是执行操作时的输入或输出数据;
- 用户通过执行操作来创建或计算张量;
- 张量并没有真正保存数字,它保存的是计算过程;
- 张量的形状不一定在编译时确定,可以在运行时通过形状推断计算得出;
在TensorFlow中,有几类比较特别的张量,由以下操作产生:
tf.constant(value):常量。在运行过程中值不会改变的单元,在TensorFlow中无须进行初始化操作。tf.Variable(value,name):变量。在运行过程中值会改变的单元,在TensorFlow中须进行初始化操作。tf.placeholder:占位符。形状可不确定,数据填充。(TensorFlow2.x有变化)
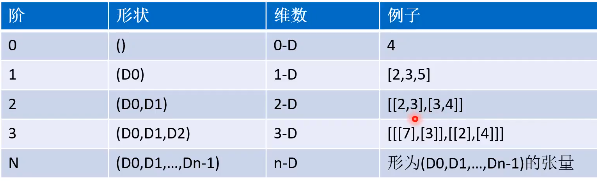
张量的形状
描述张量维度的三个术语:阶(Rank)、形状(shape)、维数(dimension)
import tensorflow as tf
scalar=tf.constant(100)
vector=tf.constant([1,2,3,4,5])
matrix=tf.constant([[1,2,3],[4,5,6]])
cube_matrix=tf.constant([[[1],[2],[3]],[[4],[5],[6]],[[7],[8],[9]]])
#获取张量形状
print(scalar.get_shape())
print(vector.get_shape())
print(matrix.get_shape())
print(cube_matrix.get_shape())
输出:
()
(5,)
(2, 3)
(3, 3, 1)
获取张量的元素
- 阶为1的张量通过
t[i]获取元素; - 阶为2的张量通过
t[i,j]获取元素; - 阶为3的张量通过
t[i,j,k]获取元素;
print(vector[0])
print(matrix[0,0])
print(cube_matrix[0,0,0])
输出:
tf.Tensor(1, shape=(), dtype=int32)
tf.Tensor(1, shape=(), dtype=int32)
tf.Tensor(1, shape=(), dtype=int32)
张量的类型
TensorFlow支持14种不同的类型:
- 实数:
tf.float32,tf.float64 - 整数:
tf.int8,tf.int16,tf.int32,tf.int64,tf.uint8 - 布尔:
bool - 复数:
tf.complex64,tf.complex128
默认类型:不带小数点的数会被默认为int32,带小数点的数会被默认为float32.
TensorFlow会对参与运算的所有张量进行类型的检查,发现类型不匹配时会报错。
变量
TensorFlow变量(Variable)的主要作用是维护特定节点的状态,如深度学习或机器学习的模型参数。
tf.Variable方法是操作,返回值是变量(特殊张量)- 通过
tf.Variable方法创建的变量,与张量一样,可以作为操作的输入和输出,不同之处在于:- 张量的生命周期通常随依赖的计算完成而结束,内存也随即释放
- 变量则常驻内存,在每一步训练时不断更新其值,以实现模型参数的更新
变量的赋值
与传统编程语言不同,TensorFlow中的变量定义后,一般无需人工赋值,系统会根据算法模型,训练优化过程中自动调整变量对应的数值。特殊情况需要人工更新的,可用变量赋值语句:update_op = tf.assign(variable_to_be_updated,new_value)
占位符
- TensorFlow使用占位符操作表示图外输入的数据,如训练和测试数据
2. TensorFlow可视化工具——TensorBoard
- 通过TensorFlow程序运行过程中输出的日志文件可视化TensorFlow程序的运行状态
- TensorBoard和TensorFlow程序跑在不同的进程中
TensorFlow2中使用TensorFlow1.x中数据流图
- 定义一个计算图,生成日志
#想用1.x版本的代码时,可以使用:
import tensorflow.compat.v1 as tf
#执行以下代码禁用2.0的模式
tf.disable_eager_execution()
#清除default graph和不断增加的节点
tf.reset_default_graph()
# 定义一个简单的计算图,实现向量加法的操作
input1=tf.constant([1.0,2.0,3.0],name="input1")
input2=tf.Variable(tf.random_uniform([3]),name="input2")
output=tf.add_n([input1,input2],name='add')
# logdir改为自己机器上的合适路径
logdir='E:/workspace/Python/TensorFlow/logs'
# 生成一个写日志的writer,并将当前的TensorFlow计算图写入日志
writer=tf.summary.FileWriter(logdir,tf.get_default_graph())
writer.close()
- 打开Anaconda Prompt :激活TensorFlow环境
⟹
\Longrightarrow
⟹ 进入生成日志文件的路径
⟹
\Longrightarrow
⟹在日志文件目录下输入
tensorboard --logdir=logpath

- 复制里面的网址(http://localhost:6006/)在浏览器中打开.

TensorFlow2中TensorBoard可视化
TensorFlow2.0(9):TensorBoard可视化















 1451
1451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









