









视频地址:【吴恩达团队Tensorflow2.0实践系列课程第三课】TensorFlow2.0中的自然语言处理
Tokenizer
本阶段完成的工作:
- 构建语料库词典: { w o r d : i n t e g e r } \{word : integer\} {word:integer};
- 基于语料库词典,将句子转换为等长的整数值列表: s e q u e n c e → [ i n t e g e r , . . . , i n t e g e r ] sequence\rightarrow[integer,...,integer] sequence→[integer,...,integer]。
1. 对句子中的词编码,建立语料库(字典)
from tensorflow.keras.preprocessing.text import Tokenizer
sentences = [
'i love my dog',
'I, love my cat',
'You love my dog!'
]
tokenizer = Tokenizer(num_words = 100)#只对前100个词编码
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
print(word_index)
结果:
{'love': 1, 'my': 2, 'i': 3, 'dog': 4, 'cat': 5, 'you': 6}
2. 将句子转换为基于词编码的列表
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.preprocessing.text import Tokenizer
sentences = [
'I love my dog',
'I love my cat',
'You love my dog!',
'Do you think my dog is amazing?'
]
tokenizer = Tokenizer(num_words = 100, oov_token="<OOV>")
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(sentences)
print("\nWord Index = " , word_index)
print("\nSequences = " , sequences)
输出:
Word Index = {'<OOV>': 1, 'my': 2, 'love': 3, 'dog': 4, 'i': 5, 'you': 6, 'cat': 7, 'do': 8, 'think': 9, 'is': 10, 'amazing': 11}
Sequences = [[5, 3, 2, 4], [5, 3, 2, 7], [6, 3, 2, 4], [8, 6, 9, 2, 4, 10, 11]]
其中oov_token指定未出现的词编码。根据训练集中已有语料库的编码,对测试集句子进行编码:
# Try with words that the tokenizer wasn't fit to
test_data = [
'i really love my dog',
'my dog loves my manatee'
]
test_seq = tokenizer.texts_to_sequences(test_data)
print("\nTest Sequence = ", test_seq)
输出:
Test Sequence = [[5, 1, 3, 2, 4], [2, 4, 1, 2, 1]]
3. 将所有句子列表的大小调为相同的——padding与truncating
承接2中代码,还需导入新的模块:
from tensorflow.keras.preprocessing.sequence import pad_sequences
不足最大长度,padding填充(默认在前面):
padded = pad_sequences(sequences, maxlen=5)#默认为'pre'
print("\nPadded Sequences:")
print(padded)
输出:
Padded Sequences:
[[ 0 5 3 2 4]
[ 0 5 3 2 7]
[ 0 6 3 2 4]
[ 9 2 4 10 11]]
padded_post = pad_sequences(sequences, padding='post',maxlen=5)
print("\nPost Padded Sequences:")
print(padded_post)
输出:
Post Padded Sequences:
[[ 5 3 2 4 0]
[ 5 3 2 7 0]
[ 6 3 2 4 0]
[ 9 2 4 10 11]]
长度长于最大长度,使用truncating截断:
truncated = pad_sequences(test_seq, maxlen=4)
print("\nTruncated Test Sequence: ")
print(truncated)
输出:
Truncated Test Sequence:
[[1 3 2 4]
[4 1 2 1]]
truncated_post = pad_sequences(test_seq, truncating='post',maxlen=4)
print("\nPost Truncated Test Sequence: ")
print(truncated_post)
输出:
Post Truncated Test Sequence:
[[5 1 3 2]
[2 4 1 2]]
实例
数据集介绍:News Headlines Dataset For Sarcasm Dection
- is_sarcastic:1表示这条新闻是讽刺的,反之为0;
- headline:新闻的标题;
- article_link:新闻原文的链接,获取补充数据时有用。
首先导入数据:
import json
sentences = []
labels = []
urls = []
with open('./tmp/Sarcasm_Headlines_Dataset.json','r') as f:
for line in f.readlines():
item = json.loads(line)
sentences.append(item['headline'])
labels.append(item['is_sarcastic'])
urls.append(item['article_link'])
导入库:
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
分词并作词编码:
tokenizer = Tokenizer(oov_token="<OOV>")
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
print(len(word_index))
print(word_index)
句子编码:
sequences = tokenizer.texts_to_sequences(sentences)
padded = pad_sequences(sequences, padding='post')
print(padded[0])
print(padded.shape)
IMDB影评情感分析
导入数据集
TensorFlow提供的数据集:TensorFlow Data Services / TFTS for short。安装tensorflow_datasets:
import tensorflow_datasets as tfds
imdb, info = tfds.load("imdb_reviews", with_info=True, as_supervised=True)#返回数据和元数据
数据集格式转换
import numpy as np
train_data, test_data = imdb['train'], imdb['test']
training_sentences = []
training_labels = []
testing_sentences = []
testing_labels = []
# str(s.tonumpy()) is needed in Python3 instead of just s.numpy()
for s,l in train_data:#s,l为tensor,需转换为numpy
training_sentences.append(str(s.numpy()))
training_labels.append(l.numpy())
for s,l in test_data:
testing_sentences.append(str(s.numpy()))
testing_labels.append(l.numpy())
training_labels_final = np.array(training_labels)
testing_labels_final = np.array(testing_labels)
词编码、句子编码
#超参数
vocab_size = 10000
embedding_dim = 16
max_length = 120
trunc_type='post'
oov_tok = "<OOV>"
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
tokenizer = Tokenizer(num_words = vocab_size, oov_token=oov_tok)
tokenizer.fit_on_texts(training_sentences)
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(training_sentences)
padded = pad_sequences(sequences,maxlen=max_length, truncating=trunc_type)
testing_sequences = tokenizer.texts_to_sequences(testing_sentences)
testing_padded = pad_sequences(testing_sequences,maxlen=max_length)
搭建网络训练
- Embedding层基于每个词的编码,经过word2vec之类的模型训练出词向量。在word2vec中,输入为基于词编码得到的one-hot编码,训练模型的过程中得到词向量。 i n t e g e r → v e c t o r integer\rightarrow vector integer→vector
- 经过两层全连接层作分类。
#搭建网络结构
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.Flatten(),#较慢,但精度高
#tf.keras.layers.GlobalAveragePooling1D(),#比Flatten()更快,但精度略低
tf.keras.layers.Dense(6, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
model.summary()

num_epochs = 10
model.fit(padded, training_labels_final, epochs=num_epochs, validation_data=(testing_padded, testing_labels_final))

查看词嵌入层
- Word Embedding/词嵌入:在一个表示词的高维向量空间中,词和它的关联词应该是聚在一类的,以此来体现 语义/情感。
e = model.layers[0]
weights = e.get_weights()[0]
print(weights.shape) # shape: (vocab_size, embedding_dim)
输出:(10000,16)
可视化词嵌入层得到的词向量
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
print(decode_review(padded[1]))
print(training_sentences[1])
import io
out_v = io.open('vecs.tsv', 'w', encoding='utf-8')
out_m = io.open('meta.tsv', 'w', encoding='utf-8')
for word_num in range(1, vocab_size):
word = reverse_word_index[word_num]
embeddings = weights[word_num]
out_m.write(word + "\n")
out_v.write('\t'.join([str(x) for x in embeddings]) + "\n")
out_v.close()
out_m.close()
在网页http://projection.tensorflow.org/:首先导入vecs.tsv文件,然后导入meta.csv文件。(并打不开这个网页ヽ(ー_ー)ノ)
讽刺新闻分类
import json
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
超参数:
vocab_size = 10000
embedding_dim = 16
max_length = 32
trunc_type='post'
padding_type='post'
oov_tok = "<OOV>"
training_size = 20000
数据集:
sentences = []
labels = []
with open('./tmp/Sarcasm_Headlines_Dataset.json','r') as f:
for line in f.readlines():
item = json.loads(line)
sentences.append(item['headline'])
labels.append(item['is_sarcastic'])
#划分训练集测试集
training_sentences = sentences[0:training_size]
testing_sentences = sentences[training_size:]
training_labels = labels[0:training_size]
testing_labels = labels[training_size:]
分词:
tokenizer = Tokenizer(num_words=vocab_size, oov_token=oov_tok)
tokenizer.fit_on_texts(training_sentences)
word_index = tokenizer.word_index
training_sequences = tokenizer.texts_to_sequences(training_sentences)
training_padded = pad_sequences(training_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)
testing_sequences = tokenizer.texts_to_sequences(testing_sentences)
testing_padded = pad_sequences(testing_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)
# Need this block to get it to work with TensorFlow 2.x
import numpy as np
training_padded = np.array(training_padded)
training_labels = np.array(training_labels)
testing_padded = np.array(testing_padded)
testing_labels = np.array(testing_labels)
训练模型:
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
model.summary()
num_epochs = 30
history = model.fit(training_padded, training_labels, epochs=num_epochs, validation_data=(testing_padded, testing_labels), verbose=2)
绘制acc和loss曲线:
import matplotlib.pyplot as plt
def plot_graphs(history, string):
plt.plot(history.history[string])
plt.plot(history.history['val_'+string])
plt.xlabel("Epochs")
plt.ylabel(string)
plt.legend([string, 'val_'+string])
plt.show()
plot_graphs(history, "accuracy")
plot_graphs(history, "loss")
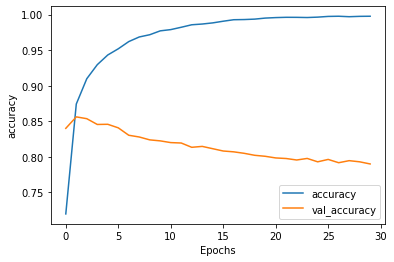
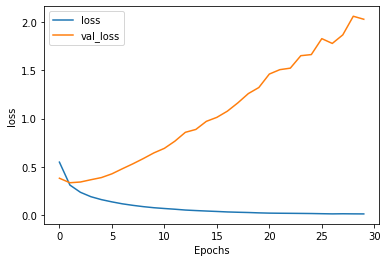
可以看到,虽然训练集的acc在上升、loss在下降,但测试集的acc却在下降、loss却在上升。这种现象在处理文本数据时很常见,可以通过调整超参数得到一个好的结果。
-
调整为:
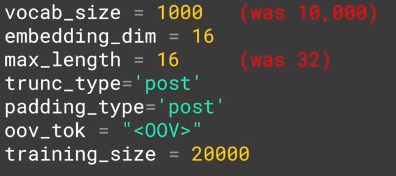
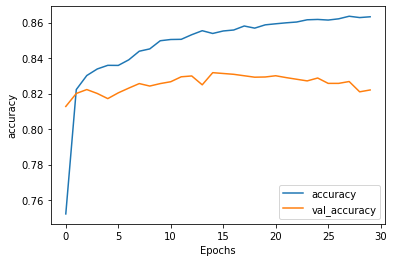

-
调整为:
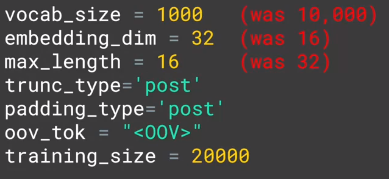

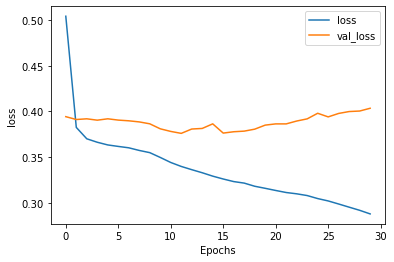
有所改观。
pre-tokenized
IMDB数据集已经在sub words上作了tokenization,
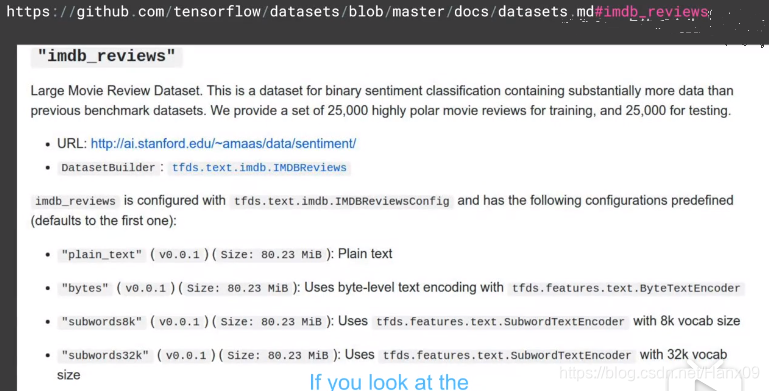
子词,就是将一般的词,比如 unigram 分解成更小单元,uni+gram,而这些小单元也有各自意思,同时这些小单元也能用到其他词里去。子词技巧:The Tricks of Subword
导入数据:
import tensorflow as tf
import tensorflow_datasets as tfds
imdb, info = tfds.load("imdb_reviews/subwords8k", with_info=True, as_supervised=True)
调用分词器:
train_data, test_data = imdb['train'], imdb['test']
tokenizer = info.features['text'].encoder
print ('Vocabulary size: {}'.format(tokenizer.vocab_size))
print(tokenizer.subwords)
演示分词器:
sample_string = 'TensorFlow, from basics to mastery'
tokenized_string = tokenizer.encode(sample_string)
print ('Tokenized string is {}'.format(tokenized_string))
original_string = tokenizer.decode(tokenized_string)
print ('The original string: {}'.format(original_string))
for ts in tokenized_string:
print ('{} ----> {}'.format(ts, tokenizer.decode([ts])))
训练模型:
#处理数据集
BUFFER_SIZE = 10000
BATCH_SIZE = 64
train_data = train_data.shuffle(BUFFER_SIZE)
train_data = train_data.padded_batch(BATCH_SIZE, tf.compat.v1.data.get_output_shapes(train_data))
test_data = test_data.padded_batch(BATCH_SIZE, tf.compat.v1.data.get_output_shapes(test_data))
#搭建网络结构
embedding_dim = 64
model = tf.keras.Sequential([
tf.keras.layers.Embedding(tokenizer.vocab_size, embedding_dim),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(6, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.summary()
#训练模型
num_epochs = 10
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
history = model.fit(train_data, epochs=num_epochs, validation_data=test_data)
绘制acc和loss曲线:
import matplotlib.pyplot as plt
def plot_graphs(history, string):
plt.plot(history.history[string])
plt.plot(history.history['val_'+string])
plt.xlabel("Epochs")
plt.ylabel(string)
plt.legend([string, 'val_'+string])
plt.show()
plot_graphs(history, "accuracy")
plot_graphs(history, "loss")

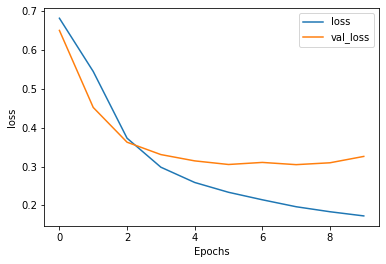
不同的隐藏层
LSTM
导入数据:
import tensorflow as tf
import tensorflow_datasets as tfds
imdb, info = tfds.load("imdb_reviews/subwords8k", with_info=True, as_supervised=True)
train_data, test_data = imdb['train'], imdb['test']
tokenizer = info.features['text'].encoder
训练模型:
#处理数据集
BUFFER_SIZE = 10000
BATCH_SIZE = 64
train_data = train_data.shuffle(BUFFER_SIZE)
train_data = train_data.padded_batch(BATCH_SIZE, tf.compat.v1.data.get_output_shapes(train_data))
test_data = test_data.padded_batch(BATCH_SIZE, tf.compat.v1.data.get_output_shapes(test_data))
#搭建网络结构
model = tf.keras.Sequential([
tf.keras.layers.Embedding(tokenizer.vocab_size, 64),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.summary()
#训练模型
num_epochs = 10
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
history = model.fit(train_data, epochs=num_epochs, validation_data=test_data)
绘制acc和loss曲线:
import matplotlib.pyplot as plt
def plot_graphs(history, string):
plt.plot(history.history[string])
plt.plot(history.history['val_'+string])
plt.xlabel("Epochs")
plt.ylabel(string)
plt.legend([string, 'val_'+string])
plt.show()
plot_graphs(history, "accuracy")
plot_graphs(history, "loss")
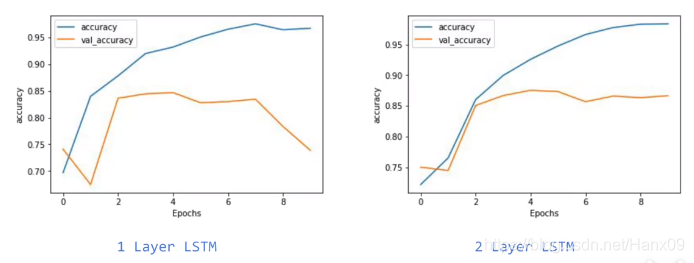
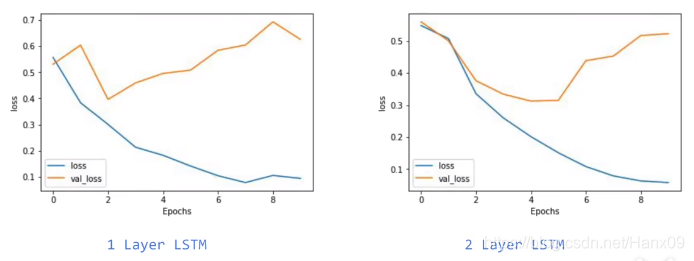
一层LSTM与两层LSTM比较
堆叠两层LSTM的网络结构:
model = tf.keras.Sequential([
tf.keras.layers.Embedding(tokenizer.vocab_size, 64),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64, return_sequences=True)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
epoch=10时的acc与loss比较
epoch=50时的acc与loss比较
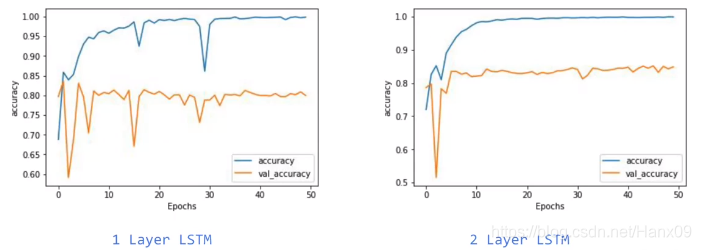
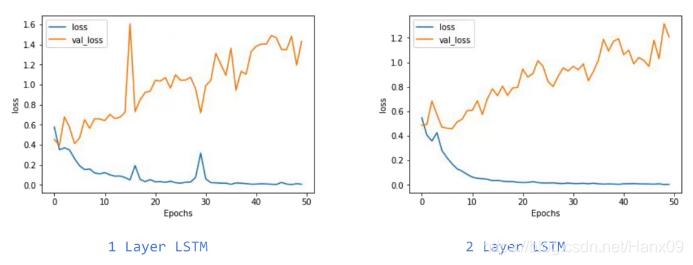
- 一层LSTM会出现锯齿状,两层LSTM更光滑一些。
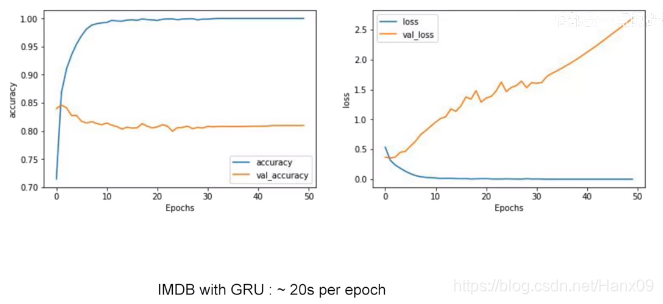
- 这里使用小量的sub words来编码一个大量的数据集,测试集的精确度能够达到80%左右已经不错了。
Flatten+平均池化与LSTM
model = tf.keras.Sequential([
tf.keras.layers.Embedding(tokenizer.vocab_size, 64),
tf.keras.layers.Flatten(),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
acc与loss比较

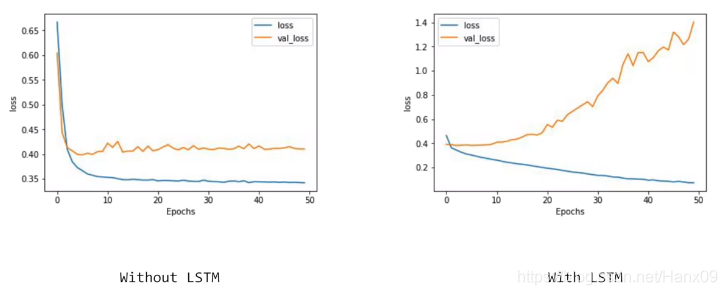
- acc:没有LSTM层时,训练数据集迅速达到85%左右,测试数据集均迅速达到80%左右,之后都处于一个稳定的值;有LSTM层时,训练集迅速达到85%,并在之后的迭代中不断acc上升,测试集一开始便达到82%,之后下降到和没有LSTM层时一样的数值,表明有LSTM层时出现过拟合,可以调整超参数解决这一问题。
- loss:与acc传达的信息相似。
卷积层+平均池化
model = tf.keras.Sequential([
tf.keras.layers.Embedding(tokenizer.vocab_size, 64),
tf.keras.layers.Conv1D(128,5,activation='relu'),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
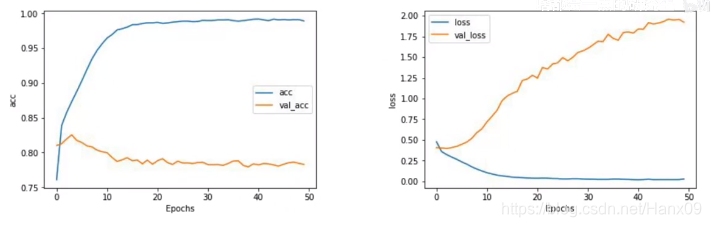
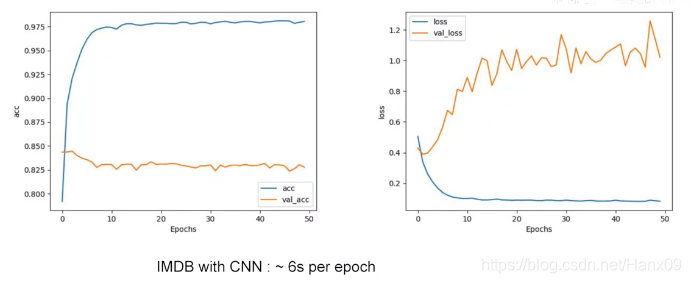
- acc是非常接近1的。
- 同样出现过拟合现象。
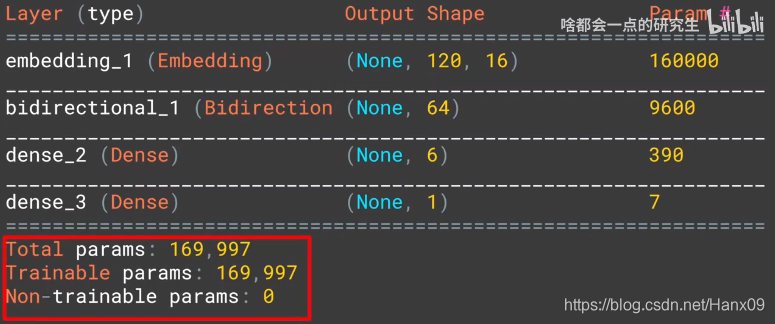
GRU
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size,embedding_dim,input_length=max_length),
tf.keras.layers.Bidirectional(tf.keras.layers.GRU(32)),
tf.keras.layers.Dense(6, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
不同隐藏层的参数个数、训练时间及acc/loss比较
Flatten层
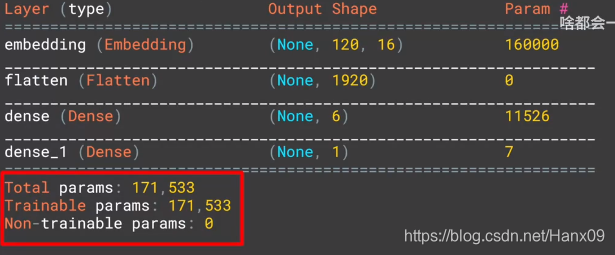
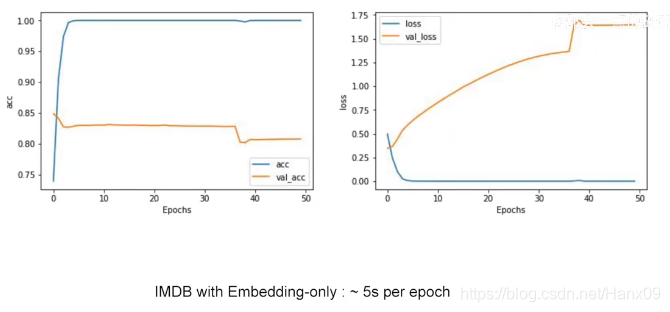
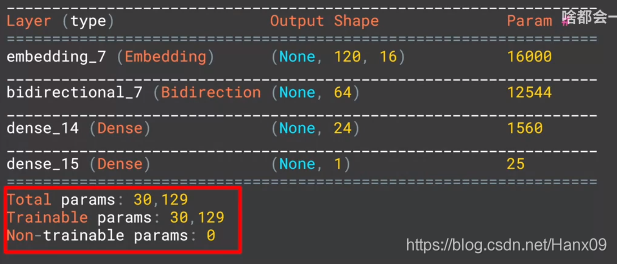
LSTM层
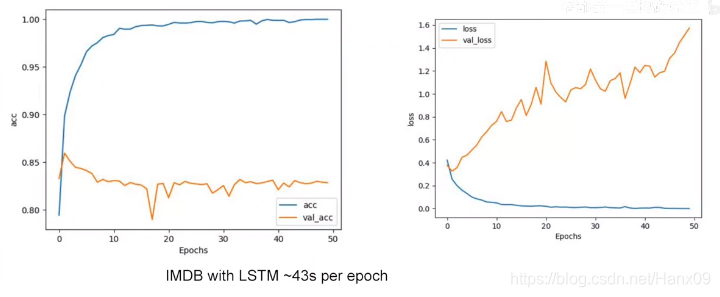
卷积层

GRU
文本生成
import tensorflow as tf
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Embedding, LSTM, Dense, Bidirectional
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import Adam
import numpy as np
tokenizer = Tokenizer()
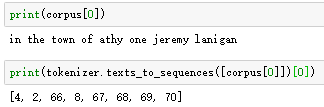
data="In the town of Athy one Jeremy Lanigan \n Battered away til he hadnt a pound. \nHis father died and made him a man again \n Left him a farm and ten acres of ground. \nHe gave a grand party for friends and relations \nWho didnt forget him when come to the wall, \nAnd if youll but listen Ill make your eyes glisten \nOf the rows and the ructions of Lanigans Ball. \nMyself to be sure got free invitation, \nFor all the nice girls and boys I might ask, \nAnd just in a minute both friends and relations \nWere dancing round merry as bees round a cask. \nJudy ODaly, that nice little milliner, \nShe tipped me a wink for to give her a call, \nAnd I soon arrived with Peggy McGilligan \nJust in time for Lanigans Ball. \nThere were lashings of punch and wine for the ladies, \nPotatoes and cakes; there was bacon and tea, \nThere were the Nolans, Dolans, OGradys \nCourting the girls and dancing away. \nSongs they went round as plenty as water, \nThe harp that once sounded in Taras old hall,\nSweet Nelly Gray and The Rat Catchers Daughter,\nAll singing together at Lanigans Ball. \nThey were doing all kinds of nonsensical polkas \nAll round the room in a whirligig. \nJulia and I, we banished their nonsense \nAnd tipped them the twist of a reel and a jig. \nAch mavrone, how the girls got all mad at me \nDanced til youd think the ceiling would fall. \nFor I spent three weeks at Brooks Academy \nLearning new steps for Lanigans Ball. \nThree long weeks I spent up in Dublin, \nThree long weeks to learn nothing at all,\n Three long weeks I spent up in Dublin, \nLearning new steps for Lanigans Ball. \nShe stepped out and I stepped in again, \nI stepped out and she stepped in again, \nShe stepped out and I stepped in again, \nLearning new steps for Lanigans Ball. \nBoys were all merry and the girls they were hearty \nAnd danced all around in couples and groups, \nTil an accident happened, young Terrance McCarthy \nPut his right leg through miss Finnertys hoops. \nPoor creature fainted and cried Meelia murther, \nCalled for her brothers and gathered them all. \nCarmody swore that hed go no further \nTil he had satisfaction at Lanigans Ball. \nIn the midst of the row miss Kerrigan fainted, \nHer cheeks at the same time as red as a rose. \nSome of the lads declared she was painted, \nShe took a small drop too much, I suppose. \nHer sweetheart, Ned Morgan, so powerful and able, \nWhen he saw his fair colleen stretched out by the wall, \nTore the left leg from under the table \nAnd smashed all the Chaneys at Lanigans Ball. \nBoys, oh boys, twas then there were runctions. \nMyself got a lick from big Phelim McHugh. \nI soon replied to his introduction \nAnd kicked up a terrible hullabaloo. \nOld Casey, the piper, was near being strangled. \nThey squeezed up his pipes, bellows, chanters and all. \nThe girls, in their ribbons, they got all entangled \nAnd that put an end to Lanigans Ball."
corpus = data.lower().split("\n")
tokenizer.fit_on_texts(corpus)#建立字典映射
total_words = len(tokenizer.word_index) + 1
print(tokenizer.word_index)
print(total_words)
input_sequences = []
for line in corpus:
token_list = tokenizer.texts_to_sequences([line])[0]
for i in range(1, len(token_list)):
n_gram_sequence = token_list[:i+1]
input_sequences.append(n_gram_sequence)
# pad sequences
max_sequence_len = max([len(x) for x in input_sequences])
input_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre'))
# create predictors and label
xs, labels = input_sequences[:,:-1],input_sequences[:,-1]
ys = tf.keras.utils.to_categorical(labels, num_classes=total_words)#one-hot
下面对以上代码作说明:

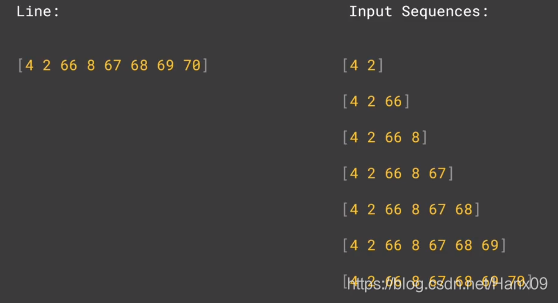
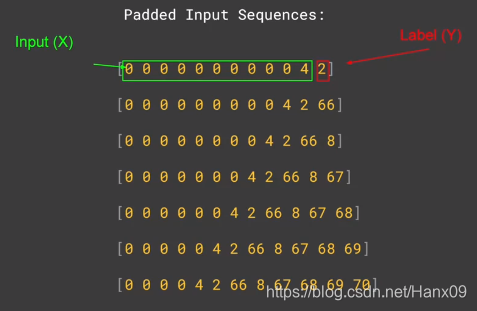
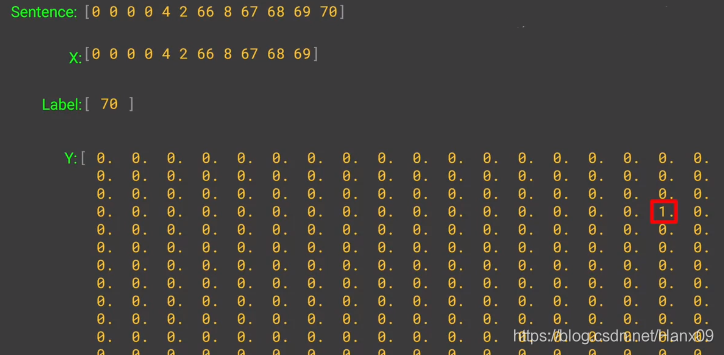
使用前面的几位作输入,最后一位作输出:
搭建网络,进行训练:
model = Sequential()
model.add(Embedding(total_words, 64, input_length=max_sequence_len-1))
model.add(Bidirectional(LSTM(20)))
model.add(Dense(total_words, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(xs, ys, epochs=500, verbose=1)
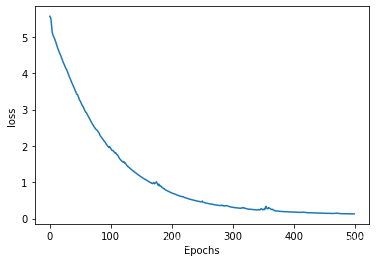
绘制训练集上的acc和loss曲线:
import matplotlib.pyplot as plt
def plot_graphs(history, string):
plt.plot(history.history[string])
plt.xlabel("Epochs")
plt.ylabel(string)
plt.show()
plot_graphs(history, 'loss')
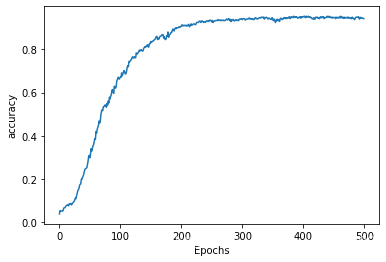
plot_graphs(history,'accuracy')
进行预测:
seed_text = "Laurence went to dublin"
next_words = 10
for _ in range(next_words):
token_list = tokenizer.texts_to_sequences([seed_text])[0]
token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')
predicted = model.predict_classes(token_list, verbose=0)
output_word = ""
for word, index in tokenizer.word_index.items():
if index == predicted:
output_word = word
break
seed_text += " " + output_word
print(seed_text)
输出:
Laurence went to dublin three weeks at brooks academy academy academy rose ill jig

















 888
888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









