







一、MapReduce 概述:
1.1MapReduce定义:
MapReduce 是一个分布式运算程序的编程框架,是用户基于hadoop的数据分析应用的核心框架。
MapReduce 的核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个分布式运算程序,并发运行在hadoop 的集群上。
1.2 MapReduce 优缺点:
优点:
(1)MapReduce 易于编程
它简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的PC机器上运行,也就是说你一写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得MapReduce编程变得非常流行
(2)良好的扩展性
当你的计算资源得不到满足时,你可以通过简单的增加机器来扩展它的计算能力。
(3)高容错性
MapReduce设计的初衷就是使得程序能够部署在廉价的PC机器是上,这就要求它具有很高的容错性。比如其中一台机器挂了,它就可以把上面的计算任务转移到另外一个节点上去运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由
hadoop内部完成的。
(4)适合PB级以上海量数据的离线处理。
缺点:
(1)不擅长实时计算
MapReduce 无法向 Mysql 一样 ,在毫秒或者秒级内返回结果。
(2)不擅长流式计算
流式计算输入的数据是动态的,而MapReduce输入的数据集是静态的,不能动态变化。
(3)不擅长DAG(有向图计算)
多个应用程序存在依赖关系,后一个应用程序的输入为前一个应用程序的输出。在这种情况下,MapReduce并不是不能做,而是使用后,每个MapReduce作业的输出结果都会写入到磁盘,会造成大量的磁盘IO,导致性能非常低下。
1.3 MapReduce 核心思想:
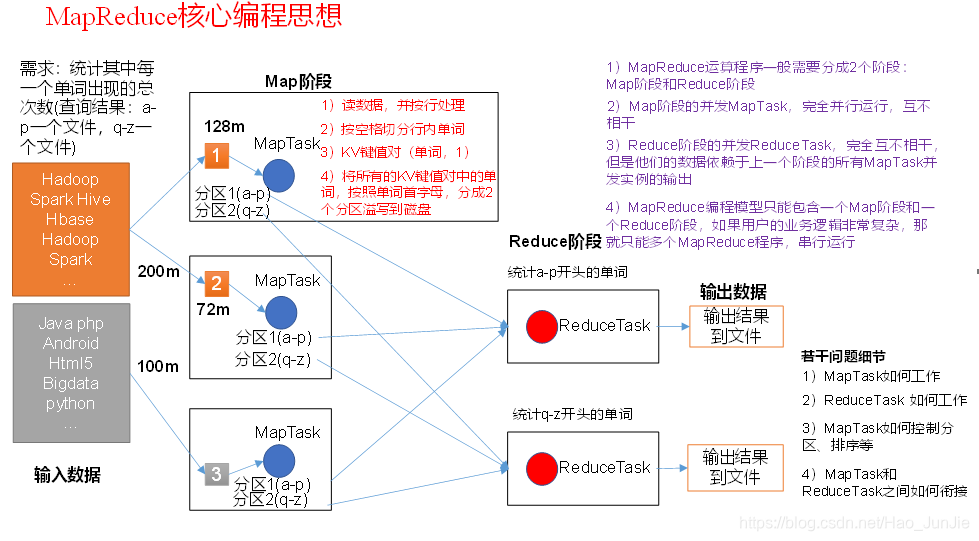
1)分布式的运算程序往往需要分成至少2个阶段。
2)第一个阶段的MapTask并发实例,完全并行运行,互不相干。
3)第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。
4)MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行。
总结:分析WordCount数据流走向深入理解MapReduce核心思想。
1.4、 MapReduce进程:
一个完整的MapReduce程序在分布式运行时有三类实例进程;
1)MrAppMaster 负责整个程序的过程调度以及状态协调
2)MapTask 负责Map 阶段 整个数据处理流程
3)ReduceTask 负责Reduce 阶段 整个数据处理流程。
1.5、java的数据类型对应的Hadoop数据序列化类型
| Java类型 | Hadoop Writable类型 |
| Boolean | BooleanWritable |
| Byte | ByteWritable |
| Int | IntWritable |
| Float | FloatWritable |
| Long | LongWritable |
| Double | DoubleWritable |
| String | Text |
| Map | MapWritable |
| Array | ArrayWritable |
1.6 编写MapReduce 的程序 的规范
用户编写的程序分为三个部分,Mapper,Reducer,Driver
Mapper:
(1)用户自定义的Mapper要继承自己的父类。
(2)Mapper输入数据是kv对的形式(kv可自己定义)
(3)Mapper中的业务逻辑代码在map() 方法中。
(4)Mapper 输出数据是kv对的形式(kv可自己定义)
Reducer:
(1) 用户自定义的Reducer 要继承自己的父类。
(2)Reducer 的输入类型是Mapper的输出类型也是kv
(3)Reducer的业务逻辑代码在reduce() 方法中。
Driver:
相当于yarn集群的客户端,用于提交我们整个程序到yarn集群,提交的是封装MapReduce程序相关运行参数的job对象、
1.7 编写MapReduce程序-----》WordCount 来初步理解:
需求:统计一个文件中每一个单词出现的次数:
文件中内容(输入数据): 输出的数据:


环境准备:
(1) 创建maven 工程
(2) 在pom 文件中添加一下依赖
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
</dependencies>
(3)在项目的src/main/resources目录下,新建一个文件,命名为“log4j2.xml”,在文件中填入。
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="error" strict="true" name="XMLConfig">
<Appenders>
<!-- 类型名为Console,名称为必须属性 -->
<Appender type="Console" name="STDOUT">
<!-- 布局为PatternLayout的方式,
输出样式为[INFO] [2018-01-22 17:34:01][org.test.Console]I'm here -->
<Layout type="PatternLayout"
pattern="[%p] [%d{yyyy-MM-dd HH:mm:ss}][%c{10}]%m%n" />
</Appender>
</Appenders>
<Loggers>
<!-- 可加性为false -->
<Logger name="test" level="info" additivity="false">
<AppenderRef ref="STDOUT" />
</Logger>
<!-- root loggerConfig设置 -->
<Root level="info">
<AppenderRef ref="STDOUT" />
</Root>
</Loggers>
</Configuration>
(4)编写程序:
a:编写Mapper 类
package com.c21.demo;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
//处理map
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取一行
String line = value.toString();
//切割字符
String[] lineArr = line.split(" ");
for (String word : lineArr) {
//以 word 1 的方式发送到reduce 中
context.write(new Text(word),new IntWritable(1));
}
}
}b、编写reducer 类:
package com.c21.demo;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, IntWritable, Text,IntWritable> {
// 相同的分区聚合到一个reduce中
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 分组累计求和
int sum=0;
for (IntWritable count : values) {
sum+=count.get();
}
context.write(key,new IntWritable(sum));
}
}
c、编写Driver 类
package com.c21.demo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 获取配置对象
Configuration configuration = new Configuration();
//根据配置获取Job作业
Job job = Job.getInstance(configuration);
job.setJarByClass(WordCountDriver.class);
job.setJobName("wordcount");
//设置mapper 和 reducer 类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//设置mapper 的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置reduce 的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置输入和输出路径
// 6 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//提交作业
// 7 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
System.out.println();
//
}
}
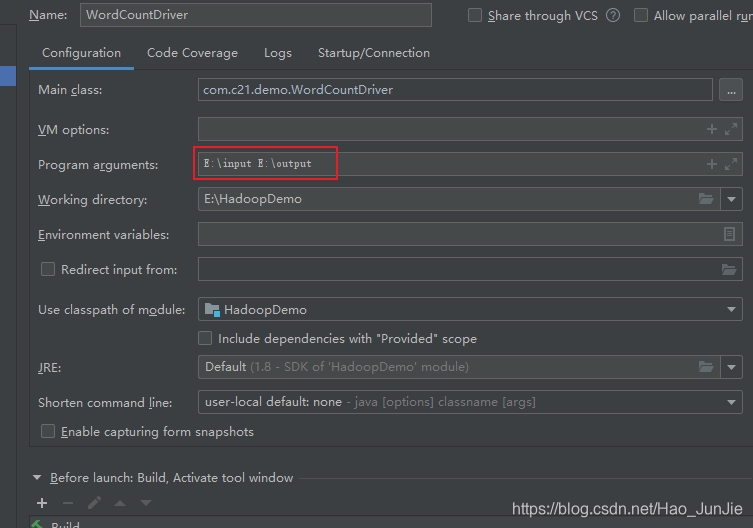
d、运行设置:设置输入文件目录和输出文件(结果) 目录。
二、Hadoop 序列化:
2.1 序列化概述:
2.1.1:什么是序列化:
序列化就是把内存中的对象转换成字节序列(或其他数据传输协议),以便存储于磁盘和网络传输。
反序列化就是把字节序列(或其他数据传输协议),或者是磁盘的持久化数据转换成内存中的对象。
2.1.2:为什么要序列化
一般来说 "活的" 对象只存在于内存中,关机断电就没了,而且"活的"对象只能由本地进程使用,不能通过网络发送到另一台计算机上,然后序列化可以存储"活的" 对象,可以将"活的" 对象发送到远程计算机上。
2.1.3:为什么不用java 序列化
java 序列化是一个重量级的序列化框架(serializable) ,一个对象被序列化后会附带很多额外信息(各种校验信息,Header,继承体系等),不方便网络高效传输,Hadoop 自己开发出一套序列化机制(Writable)
Hadoop 序列化特点:
(1) 紧凑:高效使用存储空间
(2)快速:读写数据额外开销小
(3) 可扩展性:随着通讯协议的升级而升级
(4)互操性:支持多语言的交互
2.2自定义bean对象实现序列化接口(Writable)
在企业开发中往往常用的基本序列化类型不能满足所有需求,比如在Hadoop框架内部传递一个bean对象,那么该对象就需要实现序列化接口。
具体实现bean对象序列化步骤如下7步:
(1)必须实现Writable接口
(2)反序列化时,需要反射调用空参构造函数,所以必须有空参构造
(3)重写序列化方法
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
(4)重写反序列化方法
@Override
public void readFields(DataInput in) throws IOException {
upFlow = in.readLong();
downFlow = in.readLong();
sumFlow = in.readLong();
}
(6)要想把结果显示在文件中,需要重写toString(),可用”\t”分开,方便后续用。
(7)如果需要将自定义的bean放在key中传输,则还需要实现Comparable接口,因为MapReduceShuffle过程要求对key必须能排序。详见后面排序案例。
2.3 序列化案例操作
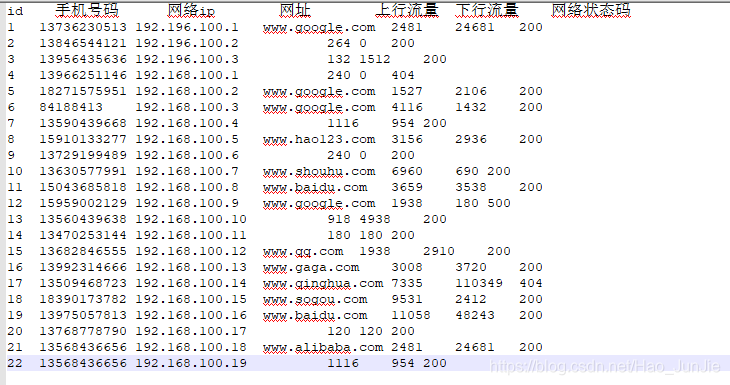
需求: 统计每一个手机号耗费的总上行流量、下行流量、总流量
输入数据格式 如下:
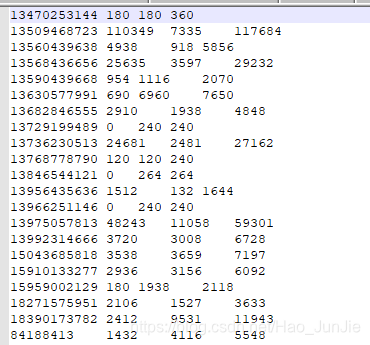
输出数据格式如下:
![]()
可以将 key 作为手机号,value 是bean 对象,但value 要想传递就必须实现序列化。
实现:
自定义bean
package com.c21.demo;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
//编写流量统计的bean 对象
//实现Writable 接口
public class FlowBean implements Writable {
private long upFlow;
private long downFlow;
private long sumFlow;
//反序列化时,需要反射调用空参构造函数,所以必须有
public FlowBean() {
super();
}
//有参构造
public FlowBean(long upFlow, long downFlow) {
super();
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
}
// 写序列化方法
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
//反序列化
//反序列化方法读顺序必须和写序列化方法的写顺序必须一致
public void readFields(DataInput in) throws IOException {
this.upFlow = in.readLong();
this.downFlow = in.readLong();
this.sumFlow = in.readLong();
}
// 编写toString方法,方便后续打印到文本
@Override
public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow;
}
//get set 方法
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
public void set(long downFlow, long upFlow) {
this.upFlow = downFlow;
this.downFlow = upFlow;
this.sumFlow = upFlow + downFlow;
}
}
自定义Mapper:
package com.c21.demo;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FlowCountMapper extends Mapper<LongWritable, Text, Text, FlowBean> {
FlowBean v = new FlowBean();
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 切割字段
String[] fields = line.split("\t");
// 3 封装对象
// 取出手机号码
String phoneNum = fields[1];
// 取出上行流量和下行流量
long upFlow = Long.parseLong(fields[fields.length - 3]);
long downFlow = Long.parseLong(fields[fields.length - 2]);
k.set(phoneNum);
v.set(downFlow, upFlow);
// 4 写出
context.write(k, v);
}
}
自定义reducer:
package com.c21.demo;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowCountReducer extends Reducer<Text,FlowBean,Text,FlowBean> {
FlowBean resultBean = new FlowBean();
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context)throws IOException, InterruptedException {
long sum_upFlow = 0;
long sum_downFlow = 0;
// 1 遍历所用bean,将其中的上行流量,下行流量分别累加
for (FlowBean flowBean : values) {
sum_upFlow += flowBean.getUpFlow();
sum_downFlow += flowBean.getDownFlow();
}
// 2 封装对象
// FlowBean resultBean = new FlowBean(sum_upFlow, sum_downFlow);
resultBean.set(sum_upFlow,sum_downFlow);
// 3 写出
context.write(key, resultBean);
}
}
自定义Driver:
package com.c21.demo;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FlowCountDriver {
public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException {
// 输入输出路径需要根据自己电脑上实际的输入输出路径设置
args = new String[] { "E:\\input\\", "E:\\output" };
// 1 获取配置信息,或者job对象实例
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 6 指定本程序的jar包所在的本地路径
job.setJarByClass(FlowCountDriver.class);
// 2 指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(FlowCountMapper.class);
job.setReducerClass(FlowCountReducer.class);
// 3 指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
// 4 指定最终输出的数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 5 指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 将job中配置的相关参数,以及job所用的java类所在的jar包, 提交给yarn去运行
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
结果:
三、MapReduce 实现原理:
3.1InputFormat 数据输入:

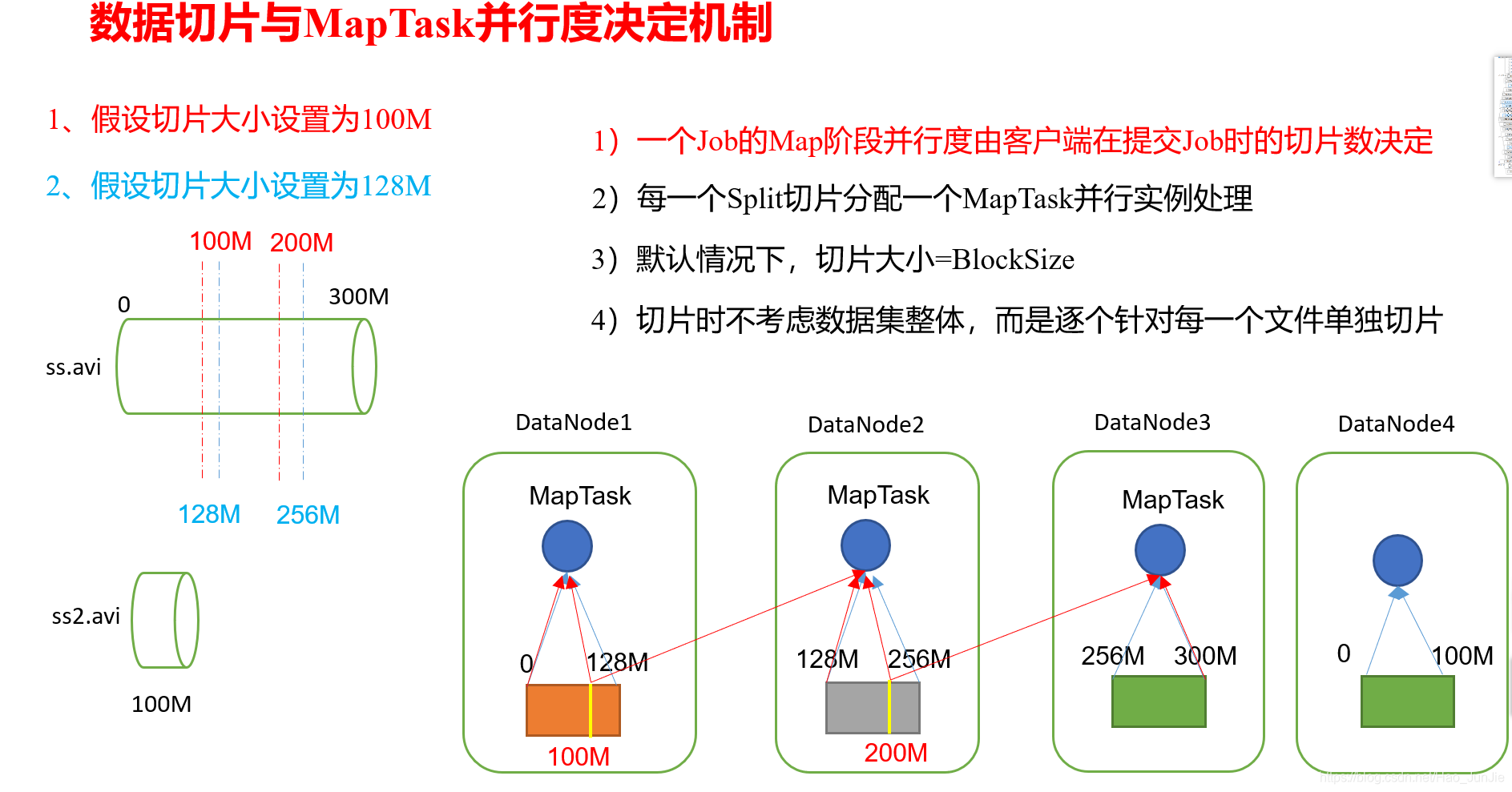
3.1.1 切片与MapTask并行度决定机制:
a.问题引出
MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个Job的处理速度。
思考:1G的数据,启动8个MapTask,可以提高集群的并发处理能力。那么1K的数据,也启动8个MapTask,会提高集群性能吗?MapTask并行任务是否越多越好呢?哪些因素影响了MapTask并行度?
b.MapTask并行度决定机制
数据块:Block是HDFS物理上把数据分成一块一块。
数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。
3.1.2 Job提交流程源码和切片源码详解:
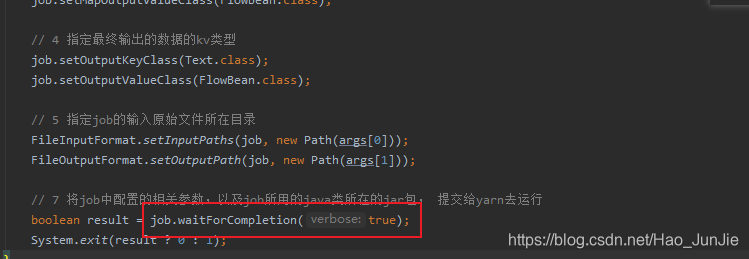
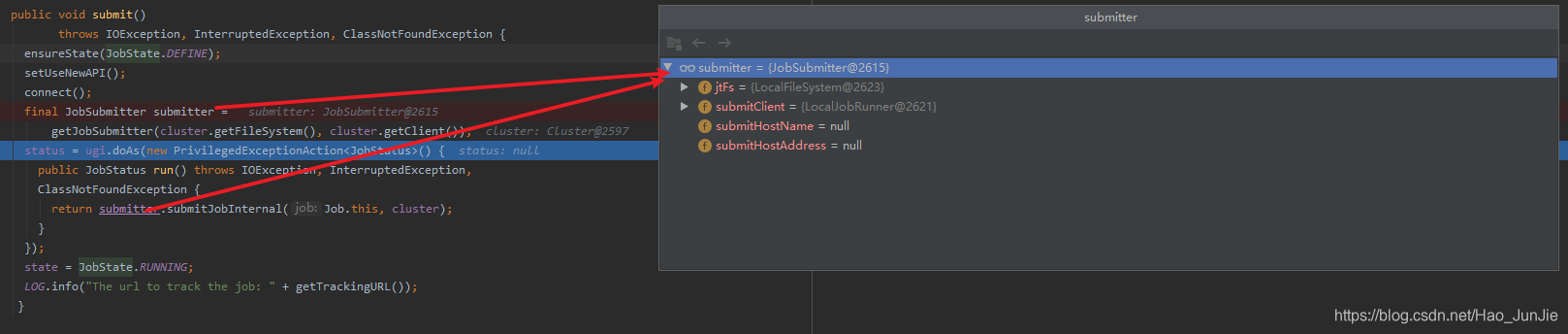
进入waitForCompletion 方法之后
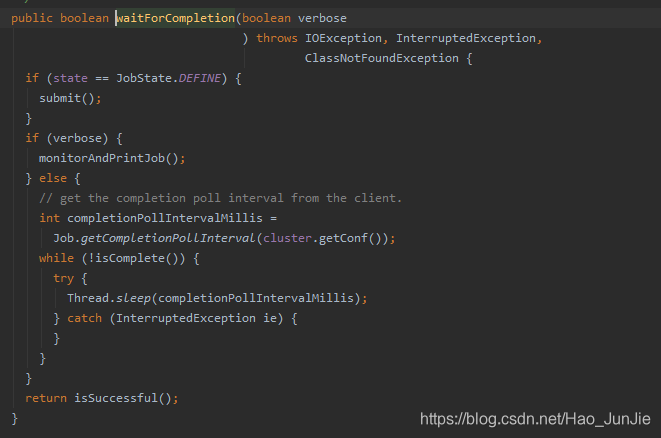
当state为DEFINE 进行submit() 进行提交
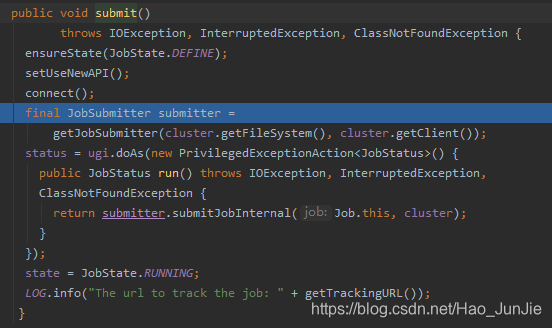
ensureState(JobState.DEFINE):确保job的状态为DEFINE
setUSerNewAPI(); 使用新的API
connect() 建立连接:是提交到YARN集群还是Local 如下图:
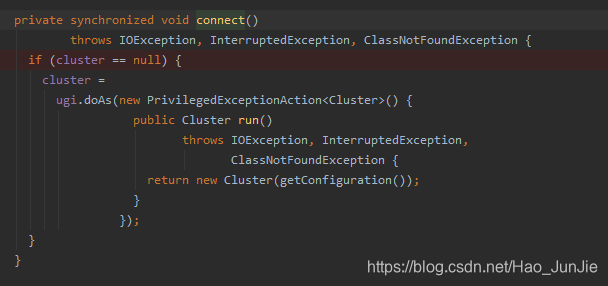
返回Cluster对象:return new Cluster(getConfiguration())
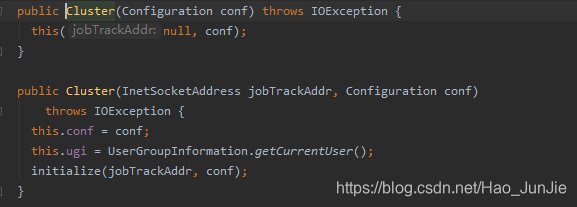
Cluster 调用initialize(jobTrackAddr,conf)
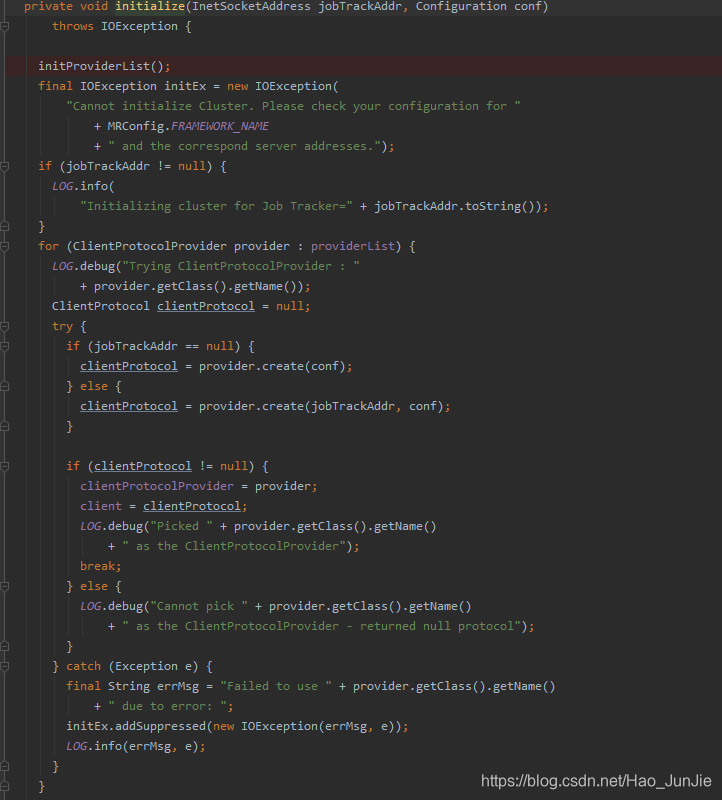
调用 initProviderList();
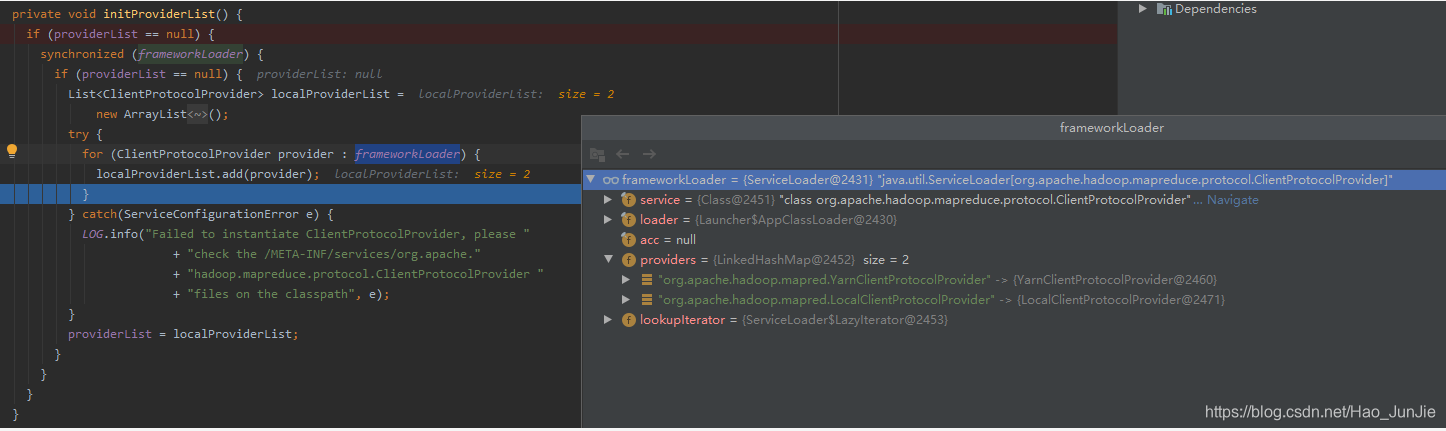
providerList 值为:YarnClientProtocolProvider 和 LocalClientProtocolProvider


如果连接的是Yarn集群 clientProtocol就是 YARNRunner 如果连接的是local clientProtocol就是LocalJobRunner
进行提交:
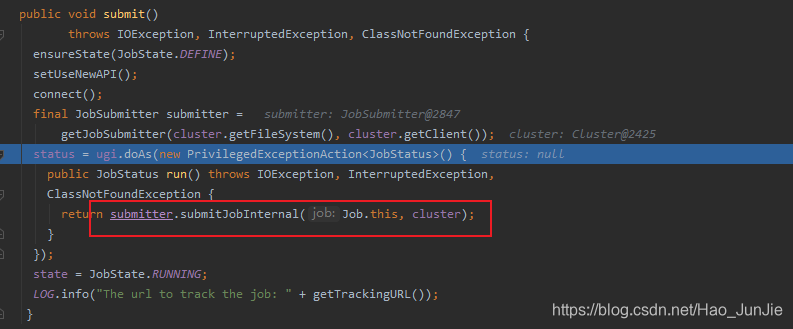
submitJobInternal(Job.this,cluster):如下代码:
JobStatus submitJobInternal(Job job, Cluster cluster)
throws ClassNotFoundException, InterruptedException, IOException {
//validate the jobs output specs
checkSpecs(job);
Configuration conf = job.getConfiguration();
addMRFrameworkToDistributedCache(conf);
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
//configure the command line options correctly on the submitting dfs
InetAddress ip = InetAddress.getLocalHost();
if (ip != null) {
submitHostAddress = ip.getHostAddress();
submitHostName = ip.getHostName();
conf.set(MRJobConfig.JOB_SUBMITHOST,submitHostName);
conf.set(MRJobConfig.JOB_SUBMITHOSTADDR,submitHostAddress);
}
JobID jobId = submitClient.getNewJobID();
job.setJobID(jobId);
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
JobStatus status = null;
try {
conf.set(MRJobConfig.USER_NAME,
UserGroupInformation.getCurrentUser().getShortUserName());
conf.set("hadoop.http.filter.initializers",
"org.apache.hadoop.yarn.server.webproxy.amfilter.AmFilterInitializer");
conf.set(MRJobConfig.MAPREDUCE_JOB_DIR, submitJobDir.toString());
LOG.debug("Configuring job " + jobId + " with " + submitJobDir
+ " as the submit dir");
// get delegation token for the dir
TokenCache.obtainTokensForNamenodes(job.getCredentials(),
new Path[] { submitJobDir }, conf);
populateTokenCache(conf, job.getCredentials());
// generate a secret to authenticate shuffle transfers
if (TokenCache.getShuffleSecretKey(job.getCredentials()) == null) {
KeyGenerator keyGen;
try {
keyGen = KeyGenerator.getInstance(SHUFFLE_KEYGEN_ALGORITHM);
keyGen.init(SHUFFLE_KEY_LENGTH);
} catch (NoSuchAlgorithmException e) {
throw new IOException("Error generating shuffle secret key", e);
}
SecretKey shuffleKey = keyGen.generateKey();
TokenCache.setShuffleSecretKey(shuffleKey.getEncoded(),
job.getCredentials());
}
if (CryptoUtils.isEncryptedSpillEnabled(conf)) {
conf.setInt(MRJobConfig.MR_AM_MAX_ATTEMPTS, 1);
LOG.warn("Max job attempts set to 1 since encrypted intermediate" +
"data spill is enabled");
}
copyAndConfigureFiles(job, submitJobDir);
Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
// Create the splits for the job
LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir));
int maps = writeSplits(job, submitJobDir);
conf.setInt(MRJobConfig.NUM_MAPS, maps);
LOG.info("number of splits:" + maps);
int maxMaps = conf.getInt(MRJobConfig.JOB_MAX_MAP,
MRJobConfig.DEFAULT_JOB_MAX_MAP);
if (maxMaps >= 0 && maxMaps < maps) {
throw new IllegalArgumentException("The number of map tasks " + maps +
" exceeded limit " + maxMaps);
}
// write "queue admins of the queue to which job is being submitted"
// to job file.
String queue = conf.get(MRJobConfig.QUEUE_NAME,
JobConf.DEFAULT_QUEUE_NAME);
AccessControlList acl = submitClient.getQueueAdmins(queue);
conf.set(toFullPropertyName(queue,
QueueACL.ADMINISTER_JOBS.getAclName()), acl.getAclString());
// removing jobtoken referrals before copying the jobconf to HDFS
// as the tasks don't need this setting, actually they may break
// because of it if present as the referral will point to a
// different job.
TokenCache.cleanUpTokenReferral(conf);
if (conf.getBoolean(
MRJobConfig.JOB_TOKEN_TRACKING_IDS_ENABLED,
MRJobConfig.DEFAULT_JOB_TOKEN_TRACKING_IDS_ENABLED)) {
// Add HDFS tracking ids
ArrayList<String> trackingIds = new ArrayList<String>();
for (Token<? extends TokenIdentifier> t :
job.getCredentials().getAllTokens()) {
trackingIds.add(t.decodeIdentifier().getTrackingId());
}
conf.setStrings(MRJobConfig.JOB_TOKEN_TRACKING_IDS,
trackingIds.toArray(new String[trackingIds.size()]));
}
// Set reservation info if it exists
ReservationId reservationId = job.getReservationId();
if (reservationId != null) {
conf.set(MRJobConfig.RESERVATION_ID, reservationId.toString());
}
// Write job file to submit dir
writeConf(conf, submitJobFile);
//
// Now, actually submit the job (using the submit name)
//
printTokens(jobId, job.getCredentials());
status = submitClient.submitJob(
jobId, submitJobDir.toString(), job.getCredentials());
if (status != null) {
return status;
} else {
throw new IOException("Could not launch job");
}
} finally {
if (status == null) {
LOG.info("Cleaning up the staging area " + submitJobDir);
if (jtFs != null && submitJobDir != null)
jtFs.delete(submitJobDir, true);
}
}
}JobID jobId = submitClient.getNewJobID():获取Jobid ,并创建Job 路径
copyAndConfigureFiles(job, submitJobDir):拷贝jar包和配置文件到集群;代码如下图:
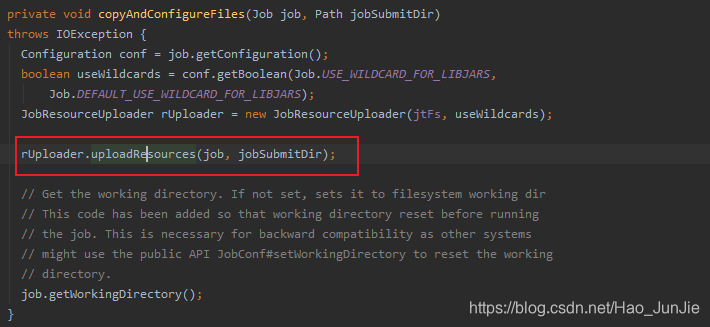

由于截图放不下,所以展示代码段:
private void uploadResourcesInternal(Job job, Path submitJobDir)
throws IOException {
Configuration conf = job.getConfiguration();
short replication =
(short) conf.getInt(Job.SUBMIT_REPLICATION,
Job.DEFAULT_SUBMIT_REPLICATION);
if (!(conf.getBoolean(Job.USED_GENERIC_PARSER, false))) {
LOG.warn("Hadoop command-line option parsing not performed. "
+ "Implement the Tool interface and execute your application "
+ "with ToolRunner to remedy this.");
}
//
// Figure out what fs the JobTracker is using. Copy the
// job to it, under a temporary name. This allows DFS to work,
// and under the local fs also provides UNIX-like object loading
// semantics. (that is, if the job file is deleted right after
// submission, we can still run the submission to completion)
//
// Create a number of filenames in the JobTracker's fs namespace
LOG.debug("default FileSystem: " + jtFs.getUri());
if (jtFs.exists(submitJobDir)) {
throw new IOException("Not submitting job. Job directory " + submitJobDir
+ " already exists!! This is unexpected.Please check what's there in"
+ " that directory");
}
// Create the submission directory for the MapReduce job.
submitJobDir = jtFs.makeQualified(submitJobDir);
submitJobDir = new Path(submitJobDir.toUri().getPath());
FsPermission mapredSysPerms =
new FsPermission(JobSubmissionFiles.JOB_DIR_PERMISSION);
mkdirs(jtFs, submitJobDir, mapredSysPerms);
if (!conf.getBoolean(MRJobConfig.MR_AM_STAGING_DIR_ERASURECODING_ENABLED,
MRJobConfig.DEFAULT_MR_AM_STAGING_ERASURECODING_ENABLED)) {
disableErasureCodingForPath(submitJobDir);
}
// Get the resources that have been added via command line arguments in the
// GenericOptionsParser (i.e. files, libjars, archives).
Collection<String> files = conf.getStringCollection("tmpfiles");
Collection<String> libjars = conf.getStringCollection("tmpjars");
Collection<String> archives = conf.getStringCollection("tmparchives");
String jobJar = job.getJar();
// Merge resources that have been programmatically specified for the shared
// cache via the Job API.
files.addAll(conf.getStringCollection(MRJobConfig.FILES_FOR_SHARED_CACHE));
libjars.addAll(conf.getStringCollection(
MRJobConfig.FILES_FOR_CLASSPATH_AND_SHARED_CACHE));
archives.addAll(conf
.getStringCollection(MRJobConfig.ARCHIVES_FOR_SHARED_CACHE));
Map<URI, FileStatus> statCache = new HashMap<URI, FileStatus>();
checkLocalizationLimits(conf, files, libjars, archives, jobJar, statCache);
Map<String, Boolean> fileSCUploadPolicies =
new LinkedHashMap<String, Boolean>();
Map<String, Boolean> archiveSCUploadPolicies =
new LinkedHashMap<String, Boolean>();
uploadFiles(job, files, submitJobDir, mapredSysPerms, replication,
fileSCUploadPolicies, statCache);
uploadLibJars(job, libjars, submitJobDir, mapredSysPerms, replication,
fileSCUploadPolicies, statCache);
uploadArchives(job, archives, submitJobDir, mapredSysPerms, replication,
archiveSCUploadPolicies, statCache);
uploadJobJar(job, jobJar, submitJobDir, replication, statCache);
addLog4jToDistributedCache(job, submitJobDir);
// Note, we do not consider resources in the distributed cache for the
// shared cache at this time. Only resources specified via the
// GenericOptionsParser or the jobjar.
Job.setFileSharedCacheUploadPolicies(conf, fileSCUploadPolicies);
Job.setArchiveSharedCacheUploadPolicies(conf, archiveSCUploadPolicies);
// set the timestamps of the archives and files
// set the public/private visibility of the archives and files
ClientDistributedCacheManager.determineTimestampsAndCacheVisibilities(conf,
statCache);
// get DelegationToken for cached file
ClientDistributedCacheManager.getDelegationTokens(conf,
job.getCredentials());
}(-------------------------------------复制jar包到集群代码结束-----------------------------------------)
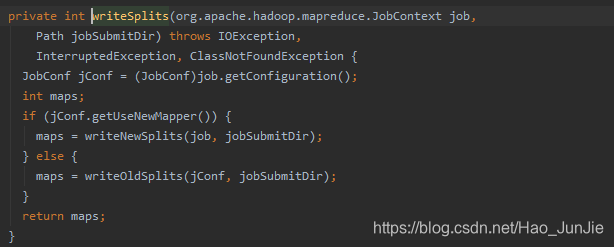
int maps = writeSplits(job, submitJobDir); 设置切片信息
conf.setInt(MRJobConfig.NUM_MAPS, maps); 将切片信息配置到配置文件中,相当于设置map 数量。设置切片代码如下:
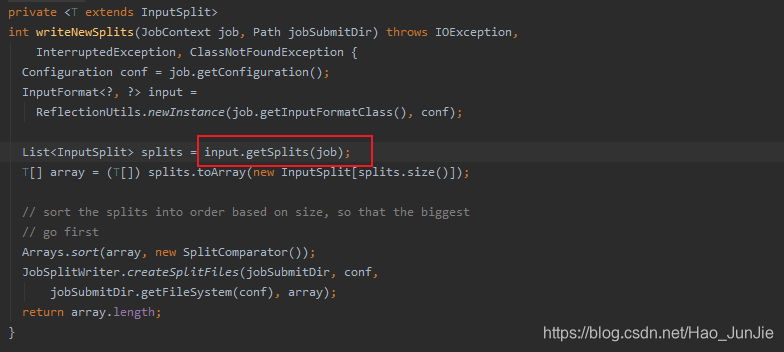
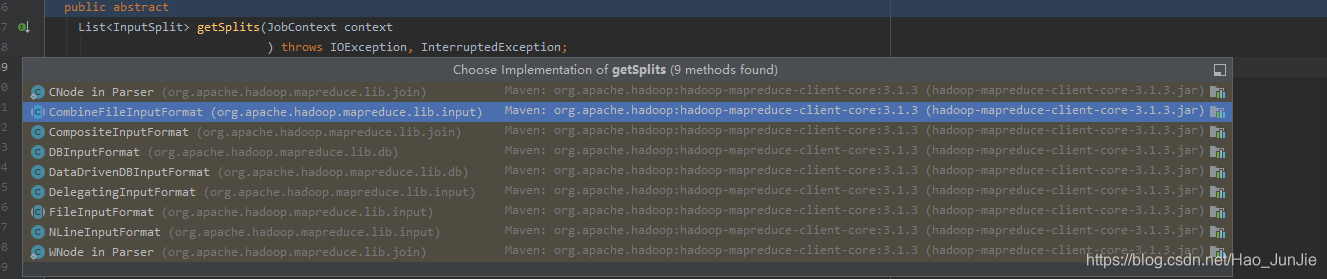
是一个抽象方法,默认是FileInputFormat :代码如下:
public List<InputSplit> getSplits(JobContext job) throws IOException {
StopWatch sw = new StopWatch().start();
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
long maxSize = getMaxSplitSize(job);
// generate splits
List<InputSplit> splits = new ArrayList<InputSplit>();
List<FileStatus> files = listStatus(job);
boolean ignoreDirs = !getInputDirRecursive(job)
&& job.getConfiguration().getBoolean(INPUT_DIR_NONRECURSIVE_IGNORE_SUBDIRS, false);
for (FileStatus file: files) {
if (ignoreDirs && file.isDirectory()) {
continue;
}
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
if (isSplitable(job, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
} else { // not splitable
if (LOG.isDebugEnabled()) {
// Log only if the file is big enough to be splitted
if (length > Math.min(file.getBlockSize(), minSize)) {
LOG.debug("File is not splittable so no parallelization "
+ "is possible: " + file.getPath());
}
}
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
} else {
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files for metrics/loadgen
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));
}
return splits;
}long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job)); 对应下面代码:
long maxSize = getMaxSplitSize(job);对应下面代码:

切片大小 :
long splitSize = computeSplitSize(blockSize, minSize, maxSize); 对应下面代码:
具体的切分代码:如下图:
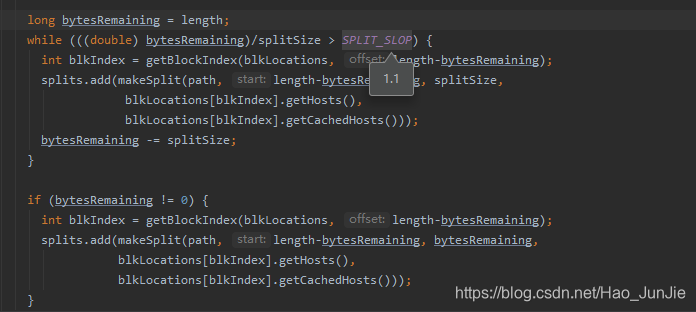
注意:blocksize 本地模式是32M
-------------------------------------------------------------------------------------------切片代码结束--------------------------------------------------------------------------------------------
向Stag路径写XML配置文件

地址如下:


可以看到有一些job的配置信息,和job的切片信息。
提交Job,返回提交状态
status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials()); 如下代码:
![]()
status 信息包括job_id,用户名,调度队列,用户名,配置文件位置 等。 如下图:
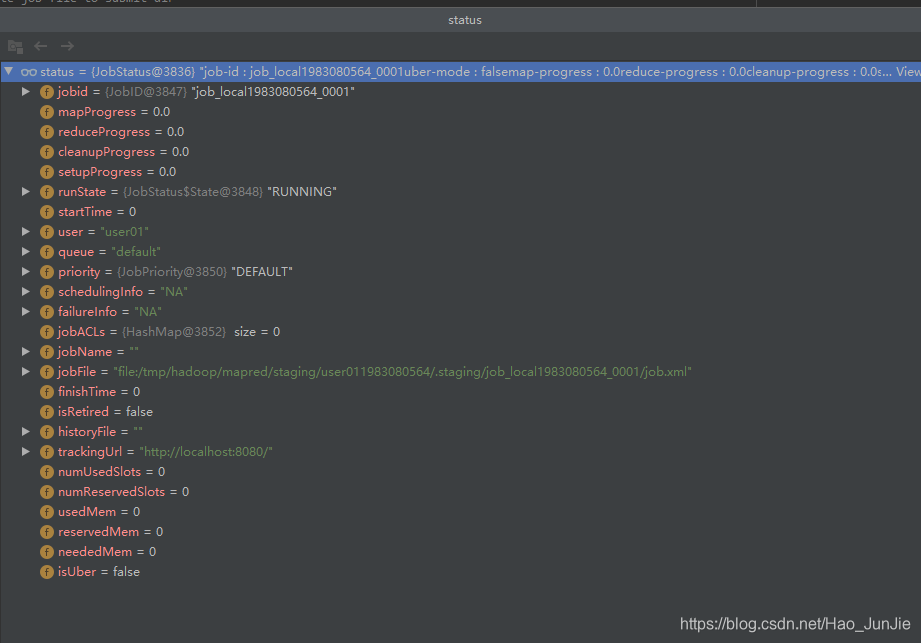
-------------------------------------------------源码解析完毕------------------------------------------------------------------------------
下面是源码解析的简洁版:
waitForCompletion()
submit();
// 1建立连接
connect();
// 1)创建提交Job的代理
new Cluster(getConfiguration());
// (1)判断是本地yarn还是远程
initialize(jobTrackAddr, conf);
// 2 提交job
submitter.submitJobInternal(Job.this, cluster)
// 1)创建给集群提交数据的Stag路径
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
// 2)获取jobid ,并创建Job路径
JobID jobId = submitClient.getNewJobID();
// 3)拷贝jar包到集群
copyAndConfigureFiles(job, submitJobDir);
rUploader.uploadFiles(job, jobSubmitDir);
// 4)计算切片,生成切片规划文件
writeSplits(job, submitJobDir);
maps = writeNewSplits(job, jobSubmitDir);
input.getSplits(job);
// 5)向Stag路径写XML配置文件
writeConf(conf, submitJobFile);
conf.writeXml(out);
// 6)提交Job,返回提交状态
status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());
图解:

对应下图:
2.FileInputFormat切片源码解析(input.getSplits(job)) 简洁版 可以与上面的源码解析对应看

3.1.3 由于InputFormat是一个抽象类,不同的实现类,分片机制不同,如下图:

FileInputFormat 切片机制:
(1) 简单地按照文件的内容长度进行切片
(2)切片大小,默认等于Block 大小。
(3)切片时不考虑数据集整体,而是逐一针对每一个文件单独切片
2、案例分析
(1)输入数据有两个文件:
file1.txt : 320M
file2.txt: 10M
(2) 经过FileInputFormat的切片机制运算后,形成的切片信息如下:
file1.txt split1 0~128
file1.txt split2 128~256
file1.txt split3 256~320
file2.txt split4 0~10
FileInputFormat切片大小的参数配置
(1) 源码中计算切片大小的公式
Math.max(minSize,Math.min(maxSize,blockSize))
mapreduce.input.fileinputformatsplit.minsize=1 默认值为1
mapreduce.input.fileinputformatsplit.maxsize=Long MAXValue 默认值为 Long MaxValue
因此,默认情况下,切片大小=blocksize
(2) 通过调minSize 和 maxSize 就可以设置切片大小
maxSize(切片最大值):参数如果调的比blockSize 小,则会让切片变小,而且就等于配置的这个参数的值。
minSize(切片最大值):参数调的比blockSize 大,则可以让切片变得比blockSize 还大。
(3) 获取切片信息API
//获取切片的文件名称
String name = inputSplit.getPath().getName();
//根据文件类型获取切片信息
FIleSplit inputSplit = (FileSplit) context.getInputSplit();















 664
664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









