







目录(本文内容过多,请根据目录选择内容阅读。)
(1)使用给出的数据完成训练集、测试集的划分,以及对模型的评价。
2.1模型评估的样本集构建与评价
2.1.1原理简介
在模型投放使用之前,通常需要对其进行性能评估,模型评估的一个重要目的是选出一个最合适的模型,对机器学习而言,希望模型对未知数据的泛化能力强,即算法对新鲜样本的适应能力强,所以需要模型评估这一过程来体现不同的模型对于未知数据的表现效果,而样本集的构建时模型评估过程中不可或缺的一步。
在机器学习中,需要使用样本集来训练模型,其目的在于学习用于训练的样本之间的联系以及规律,从而能让模型具有一定的判断能力。
一般地,将模型预测的输出与样本的真实值之间的差异称为误差,误差反映了模型在样本集上的表现能力,虽然误差越小说明模型越优秀。实际上我们期望的是模型在新样本上的预测值与真实值之间的误差,即泛化误差更小。泛化误差更能体现模型的稳健性。但是我们是无法直接得到泛化误差的。为了近似模型的泛化误差,不仅需要训练集,至少还需要测试集来测试模型对新样本的泛化能力,将测试集上的误差作为最终的评判标准来近似泛化误差。通常,我们将现有的样本集选取一部分作为训练集,另一部分作为测试集,并且保证训练集和测试集尽量不出现交集,也就是说,测试集的样本全都是在训练集中未出现过的。将学习过的样本再拿去测试,显然会拟合的很好,但是无法代表模型的泛化能力。
过拟合现象:模型如果在样本集上训练的过好,导致训练到的模型认为自然界所有同类型的数据都具有相同的规律,这样的模型在新样本上表现很差,泛化能力下降,也就是机器学习上的过拟合现象;
欠拟合现象:相对的,如果用于训练的样本集较少,不能很好地表示数据之间的联系和规律,那么就会导致学习不足,即欠拟合现象。
为了解决测试集的问题,我们可以将所有数据分为训练集和测试集两部分,且保证数据相互独立,通常的做法包括留出法、交叉验证法和自助法。
2.1.2样本集的构建方法
1.留出法
留出法(hold-out)直接将数据集D划分为两个互斥集合,其中一部分作为训练集S,另一部分作为测试集T,即
,且
。通常训练样本和测试样本的比例可以为7:3或者8:2。同时,训练集与测试集的划分有如下两个注意事项。
(1)一致性
训练集和测试集的划分要尽可能保持数据分布的一致性,避免因数据在划分过程中引入额外偏差而对最终结果产生影响。所以通常将不同类别的样本保持同等或相似比例,比如需要按照7:3的比例划分训练集与测试集时,不能直接在整体上进行划分,而是将每类样本都按照7:3的比例划分训练集与测试集,再将每类上的划分进行合并,得到最终的训练集与测试集,这种方法被称为分层采样。如图2.1所示。

(2)随机性
对打乱样本集的数据重新进行划分,模型评估的结果往往也会不相同,所以需要对样本集进行若干次随机划分,重复实验取平均值,避免单次使用留出法的不稳定性。
2.交叉验证法
交叉验证法(cross validation)将数据集D划分成k个大小相同或者相似的互斥的子集,每次使用k-1个子集的并集作为训练集,剩余的子集作为测试集,进行k次训练和测试,计算模型在测试集上的准确率,最终返回k个测试结果的平均值(k最常用的取值是10),如图2.2所示,将整个数据集D均匀分成k份,虚线框的部分表示测试集,其余为训练集。交叉验证法评估结果的稳定性和真实性依赖于k的取值,所以交叉验证法又称为k折交叉验证法(k-fold cross validation)。

分层采样
与留出法类似,为了避免因数据在划分过程中引入额外偏差而对最终结果产生影响,进行分层采样是非常必要的,如图2.3所示,分层采样将n个类别的数据集分别分成k份,取出每个类别的测试集的并集作为最终的测试集,其余的作为最终的训练集。并且,将数据集D划分为k个子集存在多种划分方式,为了减小因样本划分不同而引入的差别,k折交叉验证通常随即使用不同的划分方式重复p次,最终的评估是p次k折交叉验证的平均值。

3.自助法
自助法(bootstrapping)以自助采样法为基础,对含有m个样本的数据集D,每次随机从D中挑选一个样本,放入D'中,然后将样本放回D中,重复m次之后,得到了包含m个样本的数据集D',将D'作为训练集,用数据集D中没有出现在训练集D'中的样本作为测试集。可以证明约有1/3未出现在训练集中的样本被用作测试集。证明如下。
样本在m次采样中始终不被采到的概率为
取极限得到
2.1.3算法步骤
1.留出法
留出法的步骤如下。
- 按分层采样的方式将数据集D中的数据随即划分为7:3(比例自定),即训练集:测试集为7:3.
- 在训练集上训练后得到一个模型,用该模型在测试集上测试,保存模型的评估指标。
- 重复上述步骤n次(循环次数n可自定),取n次的平均指标作为实验结果。
2.交叉验证法
- k折交叉验证算法的步骤及流程图如图2.4所示。
- 对样本数为m的数据集D,以分层采样的方式将D中的数据以随机均分或近似均分的方式分为k份数据,每份数据样本数约为m/k个。
- 取出第i(i = 1,2,…,k)份作为第i次的测试集,剩下的作为训练集。
- 在训练集上训练后得到一个模型,用该模型在测试集上测试,保存模型的评估指标。
- 重复步骤2、3 k次,确保每个子集都有一次作为测试集的机会。
- 计算k组测试指标的平均值,将其作为当前k折交叉验证下模型的性能指标。

3.自助法
自助法的步骤如下。
- 从样本数为m的数据集D中随机抽取一个样本,记录在D'中,然后放回D。
- 重复步骤1 m次
- 得到样本数为m的数据集D',将D'作为训练集,将出现在D中且没有出现在D'中的数据作为测试集。
- 在训练集上训练后得到一个模型,用该模型在测试集上测试,保存模型的评估指标。
- 重复上述步骤n次(循环次数自定),计算平均指标。
2.1.4实战
1.数据集
本次使用的是鸢尾花数据集(Iris Dataset),该数据集由Fisher于1936年收集整理,是一类多重变量分析的数据集。该数据集共有150个样本数据,可分为Iris Setosa(山鸢尾)、Iris Versicolour(杂色鸢尾)和Iris Virginica(弗吉尼亚鸢尾),每个类别有50个样本数据,每个样本数据包括:花萼长度、花萼宽度、花瓣长度、花瓣宽度,单位均为cm。可通过数据的属性判断该数据属于哪个类别。
# 导入鸢尾花数据集
from sklearn.datasets import load_iris
iris = load_iris()load_iris()函数将返回一个Bunch对象,它直接继承自Dict类,与字典类似,由键值对组成。可以输出该对象的键值,代码如下:

我们需要使用的参数主要是‘data’、‘target’。
data:数据列表,data里面是花萼长度、花萼宽度、花瓣长度、花瓣宽度的测量数据。
target:分类的结果,这里共3个分类,分别是类别0、类别1、类别2。

2.Sklearn实现
(1)留出法
实现留出法函数主要如下:
sklearn.model_selection.train_test_split(*arrays, test_size=None, train_size=None, random_state=None, shuffle=True, stratify=None)参数含义如下:
- *arrays:表示一个或者多个数据集
- test_size:表示一个浮点数、整数或者None,用于指定测试集的大小
- train_size:表示一个浮点数、整数或者None,用于指定训练集的大小
- random_state:表示一个整数,或者一个RandomState实例,或者None
- shuffle:表示一个bool值。如果该值为True,则在划分数据集之前先混洗数据集
- stratify:表示一个数据或者None。如果它不是None,则原始数据会分层采样,采样的标记数据由该参数据决定。
留出法代码:
# 导入鸢尾花数据集
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import Counter
# 导入数据集
iris = load_iris()
# x存放特征数据,y存放标签数据
x = iris.data
y = iris.target
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.3,
random_state=1, shuffle=True, stratify=y)
# 计算分层采样时各类的抽样占比
count = Counter(y_train)
print("使用分层采样")
for k, v in count.items():
ratio = v / len(y_train)
print("class:{0}, radio:{1:.2f}".format(k, ratio))
输出结果:
(2)交叉验证法
Sklearn提供了一种直接进行交叉验证划分的类KFold,该类不考虑分层采样,其定义如下:
sklearn.model_selection.KFold(n_splits=5, shuffle=False, random_state=None)参数含义如下:
- n_splits:表示划分为几块(至少是2),默认值为5
- shuffle:表示是否打乱划分,默认值为False,即不打乱
- random_state:表示是否固定随机起点,默认值为None,当shuffle为True时启用
交叉验证法代码如下:
from sklearn.model_selection import StratifiedKFold
from sklearn.datasets import load_iris
from collections import Counter
# 导入数据集
iris = load_iris()
# x存放特征数据,y存放标签数据
x = iris.data
y = iris.target
# 十折交叉验证
sp = 10
x_train, x_test, y_train, y_test = [], [], [], []
# 划分训练集和测试集
skf = StratifiedKFold(n_splits=sp, shuffle=True, random_state=1)
# 遍历索引生成器获取每次划分的训练集和测试集‘
for train_index, test_index in skf.split(x, y):
x_test = x[test_index]
y_test = y[test_index]
x_train = x[train_index]
y_train = y[train_index]
# 计算未使用分层采样时各类的抽样占比
i = 0
count = Counter(y_train)
for train_index, test_index in skf.split(x, y):
if i == 3:
break
print("使用分层采样")
for k, v in count.items():
ratio = v / len(y_train)
print("class:{0}, radio:{1:.2f}".format(k, ratio))
i += 1
输出结果:

(3)自助法
自助法实现简单,无相关库函数使用,代码如下:
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
x = iris.data
y = iris.target
# 创建DataFrame,将数据放入
data = {
"SLength": x[:, 0],
"SWidth": x[:, 1],
"PLength": x[:, 2],
"PWidth": x[:, 3],
}
data = pd.DataFrame(data)
# 将标签作为一列添加进去
data['class'] = y
# 随机采样得到训练集
train_data = data.sample(frac=1.0, replace=True)
# 按照索引定位,找到data中不在训练集中的数据作为测试集
test_data = data.loc[data.index.difference(train_data.index)].copy()
print("训练集")
print("index", train_data)
print("测试集")
print("index", test_data)
输出结果: (测试集数据较多,未全部截图。)

(4)评价
完成了训练集和测试集的划分后,接下来就要对模型进行评价,下面介绍简单的初步评估的方法。即建立模型并对训练集进行拟合,然后再对测试集做出预测,计算准确率,对模型做大致的评价。
“评价”中使用 K 近邻(K-nearest neighbor,KNN)算法,主要有以下三个步骤:
- 计算距离:给定测试集,计算它与训练集中每个样本的距离,一般采用欧氏距离;
- 寻找邻居:圈定距离最近的 k 个训练样本,作为测试样本的近邻;
- 进行分类:根据这 k 个近邻归属的主要类别,以投票法来对测试对象分类。
代码如下:
from sklearn import neighbors
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
# 导入数据集
iris = load_iris()
# x存放特征数据,y存放标签数据
x = iris.data
y = iris.target
# 划分样本集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3,
random_state=1, shuffle=True, stratify=y)
# 构建模型
model = neighbors.KNeighborsClassifier(n_neighbors=3)
# 拟合训练集
model.fit(x_train, y_train)
# 对测试集进行预测
prediction = model.predict(x_test)
# print(prediction)
# print(y_test)
print(classification_report(y_true=y_test, y_pred=prediction))
输出结果:
3.自编代码实现
自己看书吧,意义不大,会用就行,没有书的朋友可以不管。
2.1.5实验
1.实验目的
- 掌握模型评估的原理、目的和意义。
- 掌握模型评估的流程步骤。
- 能过熟练利用Sklearn实现对数据集的划分以及评价。
2.实验数据
良性和恶性肿瘤数据,直接从Sklearn导入,代码如下:
from sklearn.datasets import load_breast_cancer
# 加载乳腺癌数据集
cancer = load_breast_cancer()
x = cancer.data
y = cancer.target3.实验要求
(1)使用给出的数据完成训练集、测试集的划分,以及对模型的评价。
留出法:
from sklearn import neighbors
from sklearn.metrics import classification_report
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
# 加载乳腺癌数据集
cancer = load_breast_cancer()
x = cancer.data
y = cancer.target
# 数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3,
random_state=1, shuffle=True, stratify=y)
# 构建模型
model = neighbors.KNeighborsClassifier(n_neighbors=3)
# 拟合训练集
model.fit(x_train, y_train)
# 对测试集进行预测
prediction = model.predict(x_test)
print(classification_report(y_true=y_test, y_pred=prediction))结果:

交叉验证法:
from sklearn import neighbors
from sklearn.metrics import classification_report
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import StratifiedKFold
# 加载乳腺癌数据集
cancer = load_breast_cancer()
x = cancer.data
y = cancer.target
# 十折交叉验证
sp = 10
x_train, x_test, y_train, y_test = [], [], [], []
# 数据集划分
skf = StratifiedKFold(n_splits=sp, shuffle=True, random_state=1)
# 遍历索引生成器获取每次划分的训练集和测试集‘
for train_index, test_index in skf.split(x, y):
x_test = x[test_index]
y_test = y[test_index]
x_train = x[train_index]
y_train = y[train_index]
# 构建模型
model = neighbors.KNeighborsClassifier(n_neighbors=3)
# 拟合训练集
model.fit(x_train, y_train)
# 对测试集进行预测
prediction = model.predict(x_test)
print(classification_report(y_true=y_test, y_pred=prediction))
结果:

自助法:
from sklearn import neighbors
from sklearn.metrics import classification_report
from sklearn.datasets import load_breast_cancer
import numpy as np
from sklearn.utils import resample
# 加载乳腺癌数据集
cancer = load_breast_cancer()
# print(cancer.DESCR)
# 提取特征和标签
x = cancer.data
y = cancer.target
# 生成自助法样本
n_samples = len(x)
x_train, y_train = resample(x, y, n_samples=n_samples, replace=True) # 生成训练集(有放回抽样)
x_test = np.array([x for x in x if x.tolist() not in x_train.tolist()]) # 生成测试集(不在训练集中的样本)
y_test = np.array([y[i] for i, x in enumerate(x) if x.tolist() not in x_train.tolist()])
# 构建模型
model = neighbors.KNeighborsClassifier(n_neighbors=3)
# 拟合训练集
model.fit(x_train, y_train)
# 对测试集进行预测
prediction = model.predict(x_test)
print(classification_report(y_true=y_test, y_pred=prediction))
结果:

(2)尝试使用多种模型分类,观察评价模型的好坏。
我们将尝试几种常用的分类模型,如逻辑回归、K近邻、支持向量机、随机森林和决策树。
# 导入所需库
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, accuracy_score
# 导入分类模型
from sklearn.linear_model import LogisticRegression # 逻辑回归
from sklearn.neighbors import KNeighborsClassifier # K近邻
from sklearn.svm import SVC # 支持向量机
from sklearn.ensemble import RandomForestClassifier # 随机森林
from sklearn.tree import DecisionTreeClassifier # 决策树
# 导入数据集
data = load_breast_cancer()
X = data.data # 特征
y = data.target # 目标变量
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义分类器
models = {
'Logistic Regression': LogisticRegression(max_iter=10000),
'K-Nearest Neighbors': KNeighborsClassifier(),
'Support Vector Machine': SVC(),
'Random Forest': RandomForestClassifier(),
'Decision Tree': DecisionTreeClassifier()
}
# 训练并评估模型
for model_name, model in models.items():
model.fit(X_train, y_train) # 训练模型
y_pred = model.predict(X_test) # 预测测试集
accuracy = accuracy_score(y_test, y_pred) # 计算准确率
print(f'{model_name} Accuracy: {accuracy:.2f}')
print(classification_report(y_test, y_pred))
print('-' * 50)
结果:


1. Logistic Regression (逻辑回归)
优点:
- 逻辑回归模型简单易解释,对线性可分数据集效果很好。
- 准确率较高,F1-score也很好,尤其是在类别1上(恶性肿瘤)。
缺点:
- 对于复杂的非线性数据,逻辑回归的表现可能不如其他复杂模型(如随机森林或支持向量机)。
2. K-Nearest Neighbors (K近邻)
优点:
- KNN在处理非线性关系时表现出色,且不需要对数据进行假设。
- 类别0的精确率为1.00,表示模型预测的类别0全为正确,但召回率为0.88,表明有部分实际为类别0的样本未能被正确识别。
缺点:
- 对于大数据集计算开销较大,训练速度慢,因为它需要计算所有点之间的距离。
- 对于噪声敏感。
3. Support Vector Machine (支持向量机)
优点:
- SVM在高维空间中表现出色,能够处理非线性边界。
- 对类别0的精确率较高,但召回率略低(可能漏检一些类别0样本)。
缺点:
- 对于非常大的数据集,训练时间可能会很长。
- SVM对于选择合适的核函数和参数调优较为敏感。
4. Random Forest (随机森林)
优点:
- 随机森林通过集成多棵决策树来减少过拟合,提高了预测的准确性和稳健性。
- 对于不平衡数据集,随机森林的表现较好,类别1(恶性肿瘤)的精确率和召回率都很高。
缺点:
- 随机森林模型较为复杂,训练时间较长,尤其在大数据集下。
- 模型可解释性较差,难以理解每个特征的具体贡献。
5. Decision Tree (决策树)
优点:
- 决策树模型简单易解释,能够直观地了解模型的决策路径。
- 训练速度快,对噪声数据较为健壮。
缺点:
- 容易过拟合,尤其是深度较大的决策树。
- 在一些数据集上,性能不如随机森林等集成模型。
(3)尝试对回归问题的数据集构造模型进行评估。
该数据集为加州房价数据集。加州房价数据集是一个广泛使用的机器学习数据集,用于预测加州不同地区房屋价格的中位数。该数据集包含了1990年加州的所有普查区域,共计20640个实例。每个实例包含了8个特征:人口中位数、房屋总数、卧室总数、年收入中位数、房屋价值中位数、海拔、纬度和经度。这些特征被用来预测该地区房屋价格的中位数。
import pandas as pd
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
import matplotlib.pyplot as plt
# 加载加州房价数据集
california_housing = fetch_california_housing()
X = california_housing.data
y = california_housing.target
# 拆分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化和训练线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
# 使用测试集进行预测
y_pred = model.predict(X_test)
# 计算并输出均方误差和R^2的分数
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Squared Error (MSE): {mse:.5f}")
print(f"R^2 Score: {r2:.5f}")
# 输出模型系数
'''
线性回归模型的系数表示每个特征对房价中位数的影响程度。系数的绝对值越大,影响程度越大。
系数为正表示特征值越大,房价中位数越高;系数为负表示特征值越大,房价中位数越低。
'''
coefficients = pd.DataFrame(model.coef_, california_housing.feature_names, columns=['Coefficient'])
print(coefficients)
# 可视化实际值与预测值
plt.figure(figsize=(8, 6))
plt.scatter(y_test, y_pred, alpha=0.5) # 绘制散点图,alpha参数控制透明度,0为完全透明,1为完全不透明
plt.xlabel("Actual Median House Value")
plt.ylabel("Predicted Median House Value")
plt.title("Actual vs Predicted House Prices")
plt.plot([y.min(), y.max()], [y.min(), y.max()], 'r--') # 对角线
plt.show()
结果 :


2.2评估指标计算
2.2.1原理简介
1.分类模型的评估标准
(1)混淆矩阵
混淆矩阵(confusion matrix)是监督学习种的一种可视化工具,主要用于比较分类结果和实例的真实信息。矩阵种的每行代表实例的预测类别,每列代表实例的真实类别,如表所示。

TP+FP+TN+FN = 样本总数。第一个字母表示本次预测的正确性,第二个字母表示由分类器预测的类别。
- T表示正确,F表示错误。
- P表示预测为正例,N表示预测为反例
- 真正率(true positive rate,TPR):TPR=TP/(TP+FN),即被预测为正的正样本数/正样本实际数。
- 假正率(false positive rate,FPR):FPR=FP/(FP+TN),即被预测为正的负样本数/负样本实际数。
- 假负率(fasle negative rate,FNR):FNR=FN/(TP+FN),即被预测为负的正样本数/正样本实际数。
- 真负率(true negative rate,TNR):TNR=TN/(FP+TN),即被预测为负的负样本数/负样本实际数。
(2)准确率
准确率(accuracy)是最常用的分类性能指标,准确率是针对所有预测正确的样本。即正确预测的正负样本数/样本总数。公式如下:
(3)精准率
精准率(precision)是针对预测正确的正样本而不是所有预测正确的样本。表现为预测出是正的样本里面有多少样本真正是正的。也可以理解为查准率。即正确预测的正样本数/预测的正样本总数,公式如下:
(4)召回率
召回率(recall)表现出在实际正样本中,分类器能正确预测出多少正样本。与真正率相等,也可以理解为查全率。即正确预测的正样本数/实际的正样本总数。公式如下:
(5)F1值
F1值是精确率和召回率的调和值,也是调和平均数,最大为1,最小为0.更接近于两个数中较小的一个,所以精确率和召回率接近时,F1值最大。F1值即正确预测的正样本数/实际的正样本总数。公式如下:
(6)PRC
PRC(precision recall curve,精确率-召回率曲线)是以查准率或精确率为Y轴、查全率或召回率为X轴而绘制的图。它是综合评价整体结果的评估指标。所以哪种类型(正或负)样本多,权重就大。
PRC能直观地显示出学习器在样本总体上的查全率和查准率,它是一条总体趋势递减的曲线。在进行比较时,若一个学习器的PRC被另一个学习器的PRC完全包裹住,则可断言后者的性能优于前者。如下图所示,C被A、B包裹,可以断言A、B的性能优于C。
由于A、B两条曲线相交,难以比较。此时较为合理的判据就是比较PRC下于坐标轴围成的面积,该指标在一定程度上表示了学习器在查准率和查全率上取得相对“双高”的比例。
因为这个值不易估算,所以引入平衡点(即在P=R的直线与曲线相交的点,BEP)来度量,其值越大表明分类器性能越好,由图可知,A的性能优于B。

(7)ROC
ROC(receiver operating characteristic,受试者工作特征)曲线以真正率(TPR)为Y轴,以假正率(FPR)为X轴,对角线对应于随机猜测模型,在逻辑回归里面,对于正负例的界定,通常会设一个阈值,大于该阈值的为正类,小于该阈值的为负类。如果减小这个阈值,更多的样本会被识别为正类,将提高正类的识别率,但同时也会使得更多的负类被错误地识别为正类。为了直观表示这一现象,引入ROC曲线。根据分类结果计算得到ROC空间中相应的点,连接这些点就形成ROC曲线。一般情况下,这条曲线都应该处于(0,0)和(1,1)连线的上方。
ROC曲线

ROC曲线越接近左上角,该分类器的性能就越好。一般而言,如果ROC的曲线是光滑的,那么基本可以判断没有太大的误差。如果一个学习器的ROC曲线被另一个学习器的ROC曲线包裹,可以断言后者性能优于前者;若两个学习器的ROC曲线相交,可以通过比较ROC曲线下与坐标轴围成的面积的大小来比较性能优劣。(面积大的曲线对应的分类器性能更好)
(8)AUC
AUC(area under curve,曲线下面积)的值为ROC曲线下方与坐标轴围成的面积,若分类器的性能较好,则AUC为1。一般的AUC值为0.5~1,AUC值越高,模型的区分能力越好。若AUC=0.5,即与上图ROC曲线中的
斜线重合,表示模型的区分能力与随即猜测没有差别。若AUC<0.5,则可能是好坏标签标反,也可能是模型真的很差。
2.回归模型的评价指标
一般的,对于回归问题,存在真实值序列
与预测值序列
,对其准确程度进行评价时一般使用平均绝对误差、平均绝对百分比误差、平均平方误差等。
(1)平均绝对误差
平均绝对误差(mean absolute error,MAE)的值越大,说明预测模型误差越大。MAE的值越小,说明预测模型拥有更好的精确度。公式如下:
(2)平均绝对百分比误差
平均绝对百分比误差(mean absolute percent error,MAPE)的值越大,说明预测模型误差越大。MAPE的值越小,说明预测模型拥有更好的精确度。公式如下:
(3)平均平方误差
平均平方误差(mean squared error,MSE)的值越大,说明预测模型误差越大。MSE的值越小,说明预测模型拥有更好的精确度。公式如下:
(4)平均平方根误差
平均平方根误差(root mean squared error,RMSE)的值越大,说明预测模型误差越大。RMSE的值越小,说明预测模型拥有更好的精准度。公式如下:
(5)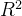 决定系数(R-Squared)
决定系数(R-Squared)
分子部分表示真实值与预测值的平方差之和,分母部分表示真实值与均值的平方差之和,其取值范围为[0,1]。一般的,
2.2.2代码实现与实战
1.分类模型
(1)数据集:现有5个苹果,对这5个苹果的态度分别是喜欢、喜欢、不喜欢、不喜欢、喜欢,用数组表示就是y=[1,1,0,0,1]。将苹果的图片等特征代入分类模型中,得到的分类结果是y_hat=[1,1,0,0,0]。
(2)自编代码实现与结果展示。
第一个代码块新建一个func.py文件放入,第二个代码块随便建一个py文件放入,然后执行第二个代码块
# 真正率
def TPR(y, y_hat):
true_positive = sum(yi == 1 and yi_hat == 1 for yi, yi_hat in zip(y, y_hat))
actual_positive = sum(y)
return true_positive / actual_positive
# 假正率
def FPR(y, y_hat):
false_positive = sum(yi == 0 and yi_hat == 1 for yi, yi_hat in zip(y, y_hat))
actual_negative = len(y) - sum(y)
return false_positive / actual_negative
# 假负率
def FNR(y, y_hat):
false_negative = sum(yi == 1 and yi_hat == 0 for yi, yi_hat in zip(y, y_hat))
actual_positive = sum(y)
return false_negative / actual_positive
# 真负率
def TNR(y, y_hat):
false_negative = sum(yi == 0 and yi_hat == 0 for yi, yi_hat in zip(y, y_hat))
actual_negative = len(y) - sum(y)
return false_negative / actual_negative
# 准确率
def ACC(y, y_hat):
return sum(yi == yi_hat for yi, yi_hat in zip(y, y_hat)) / len(y)
# 精确率
def PRE(y, y_hat):
true_positive = sum(yi == 1 and yi_hat == 1 for yi, yi_hat in zip(y, y_hat))
predicted_positive = sum(y_hat)
return true_positive / predicted_positive
# 召回率
def REC(y, y_hat):
true_positive = sum(yi == 1 and yi_hat == 1 for yi, yi_hat in zip(y, y_hat))
actual_positive = sum(y)
return true_positive / actual_positive
# F1值
def F1_score(y, y_hat):
return 2 * (PRE(y, y_hat) * REC(y, y_hat)) / (PRE(y, y_hat) + REC(y, y_hat))
# ROC曲线
def ROC(y, y_hat_prob):
thresholds = sorted(set(y_hat_prob), reverse=True)
ret = [[0, 0]]
for threshold in thresholds:
y_hat = [int(yi_hat_prob >= threshold) for yi_hat_prob in y_hat_prob]
ret.append([TPR(y, y_hat), 1 - TNR(y, y_hat)])
return ret
# AUC曲线
def AUC(y, y_hat_prob):
roc = iter(ROC(y, y_hat_prob))
tpr_pre, fpr_pre = next(roc)
auc = 0
for tpr, fpr in roc:
auc += (tpr + tpr_pre) * (fpr - fpr_pre) / 2
# tpr_pre, fpr_pre = tpr, fpr
tpr_pre = tpr
fpr_pre = fpr
return auc
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from numpy.random import seed
from func import *
# 对苹果的态度
# y = [1, 1, 0, 0, 1]
# 将苹果的图片等特征带入分类模型中得到的分类结果
# y_hat = [1, 1, 0, 0, 0]
z = np.array([1, 1, 0, 0, 1])
z_hat = np.array([1, 1, 0, 0, 0])
print("TPR:", TPR(z, z_hat))
print("FPR:", FPR(z, z_hat))
print("FNR:", FNR(z, z_hat))
print("TNR:", TNR(z, z_hat))
print("Accuracy:", ACC(z, z_hat))
print("Precision:", PRE(z, z_hat))
print("Recall:", REC(z, z_hat))
print("F1_Score:", F1_score(z, z_hat))
# 绘制ROC曲线
seed(15)
y = np.array([1, 1, 0, 1, 1, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0])
y_pred = np.array([0.9, 0.8, 0.7, 0.6, 0.55, 0.54, 0.53, 0.52, 0.51, 0.505, 0.4, 0.39, 0.38, 0.37, 0.36, 0.35,
0.34, 0.33, 0.3, 0.1])
points = ROC(y, y_pred)
df = pd.DataFrame(points, columns=['tpr', 'fpr'])
print("AUC is %.3f." % AUC(y, y_pred))
df.plot(x='fpr', y='tpr', label="ROC", xlabel="FPR", ylabel="TPR")
# print(df)
plt.show()
结果:


(3)sklearn库函数实现
代码会报错,这个
ConvergenceWarning是由于在使用scikit-learn库中的lbfgs优化器进行模型训练时,模型未能达到收敛条件。解决办法在源代码结果下方。解决办法参考博客
书上源代码:
from sklearn.metrics import precision_recall_curve
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
digits = datasets.load_digits()
x = digits.data
y = digits.target.copy()
y[digits.target == 9] = 1
y[digits.target != 9] = 0
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=666)
log_reg = LogisticRegression()
log_reg.fit(x_train, y_train)
decision_scores = log_reg.decision_function(x_test)
precision, recall, thresholds = precision_recall_curve(y_test, decision_scores)
# print("Precision: ", precision)
# print("Recall: ", recall)
# print("Thresholds: ", thresholds)
plt.xlabel("Recall")
plt.ylabel("Precision")
plt.title("Precision-Recall Curve")
plt.plot(recall, precision)
plt.show()
源代码结果:与书上由较大差别

优化代码:
import warnings
import numpy as np
from sklearn.metrics import precision_recall_curve
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
digits = datasets.load_digits()
x = digits.data
y = digits.target.copy()
y[digits.target == 9] = 1
y[digits.target != 9] = 0
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=666)
# 忽略警告信息
warnings.filterwarnings('ignore')
# 创建逻辑回归模型,设置参数
log_reg = LogisticRegression(solver='lbfgs', max_iter=500)
log_reg.fit(x_train, y_train)
decision_scores = log_reg.decision_function(x_test)
precision, recall, thresholds = precision_recall_curve(y_test, decision_scores)
# print("Precision: ", precision)
# print("Recall: ", recall)
# print("Thresholds: ", thresholds)
# 预测
y_pred = log_reg.predict(x_test)
# 模型评估
accuracy = np.mean(y_pred == y_test)
print("Accuracy: ", accuracy)
# 绘制Precision-Recall曲线
plt.xlabel("Recall")
plt.ylabel("Precision")
plt.title("Precision-Recall Curve")
plt.plot(recall, precision)
plt.show()
结果:相比源代码有了较好的改变。


2.回归模型
(1)数据集
import numpy as np
# 数据集
y_true = np.array([1.0, 5.0, 4.0, 3.0, 2.0, 5.0, -3.0])
y_pred = np.array([1.0, 4.5, 3.8, 3.2, 3.0, 4.8, -2.2])(2)Sklearn实现
import numpy as np
from sklearn.metrics import mean_squared_error # MSE:均方误差
from sklearn.metrics import mean_absolute_error # MAE:平均绝对误差
from sklearn.metrics import r2_score # R2得分
# 数据集
y_test = np.array([1.0, 5.0, 4.0, 3.0, 2.0, 5.0, -3.0])
y_predict = np.array([1.0, 4.5, 3.8, 3.2, 3.0, 4.8, -2.2])
mean_squared_error(y_test, y_predict)
mean_absolute_error(y_test, y_predict)
np.sqrt(mean_squared_error(y_test, y_predict)) # RMSE:均方根误差
r2_score(y_test, y_predict)
print("MAE:", mean_absolute_error(y_test, y_predict))
print("MSE:", mean_squared_error(y_test, y_predict))
print("RMSE:", np.sqrt(mean_squared_error(y_test, y_predict)))
print("R2:", r2_score(y_test, y_predict))
结果:
 (3)自编实现 :结果同上
(3)自编实现 :结果同上
import numpy as np
def MAE(y_true, y_pred):
n = len(y_true)
return np.sum(np.abs(y_true - y_pred)) / n
def MAPE(y_true, y_pred):
n = len(y_true)
return np.sum(np.abs((y_true - y_pred) / y_true) / n)
def MSE(y_true, y_pred):
n = len(y_true)
return np.sum((y_true - y_pred) ** 2) / n
def RMSE(y_true, y_pred):
return np.sqrt(MSE(y_true, y_pred))
def R2(y_true, y_pred):
return 1 - np.sum((y_true - y_pred) ** 2) / np.sum((y_true - np.mean(y_true)) ** 2)
# 数据集
y_test = np.array([1.0, 5.0, 4.0, 3.0, 2.0, 5.0, -3.0])
y_predict = np.array([1.0, 4.5, 3.8, 3.2, 3.0, 4.8, -2.2])
print("MAE:", MAE(y_test, y_predict))
print("MSE:", MSE(y_test, y_predict))
print("RMSE:", RMSE(y_test, y_predict))
print("R2:", R2(y_test, y_predict))
2.2.3实验
1.实验目的
了解并掌握机器学习模型评估指标的原理与各种计算方法,学会合理使用自编代码或者调用Sklearn库函数来完成相关指标的计算。
2.实验数据
(1)分类模型
现有10个玩具,对玩具的喜爱与否用1和0表示,1代表喜爱,0代表不喜爱。先对10个玩具的喜爱与否用列表表示为[1,1,1,0,1,0,0,0,1,1]。玩具的图片与内容等特征带入分类模型中,得到的预测结果是[1,1,0,0,0,1,0,0,0,1]。也可自行导入所需数据。
(2)回归模型
测试集目标真实值[1.0,4.0,2.0,3.0,1.0,5.0,-3.0,5.0,1.0,3.0,2.0,5.0]。
测试集目标预测值[1.0,4.1,2.2,2.8,1.0,4.8,-2.2,5.1,0.9,3.2,2.1,5.3]。
3.实验要求
(1)对于分类模型,计算出TPR,FPR,FNR,TNR,Accuracy,Precision,Recall,F1值等指标并绘制出ROC曲线。
分类模型代码以及结果:
import numpy as np
import matplotlib.pyplot as plt
from Classification_func import *
from sklearn.metrics import roc_curve, auc
y = np.array([1, 1, 1, 0, 1, 0, 0, 0, 1, 1])
y_hat = np.array([1, 1, 0, 0, 0, 1, 0, 0, 0, 1])
print("TPR:", TPR(y, y_hat))
print("FPR:", FPR(y, y_hat))
print("FNR:", FNR(y, y_hat))
print("TNR:", TNR(y, y_hat))
print("Accuracy:", ACC(y, y_hat))
print("Precision:", PRE(y, y_hat))
print("Recall:", REC(y, y_hat))
print("F1_Score:", F1_score(y, y_hat))
print("-----------------------------------")
# points = ROC(y, y_hat)
# df = pd.DataFrame(points, columns=['tpr', 'fpr'])
print("AUC is %.3f." % AUC(y, y_hat))
# df.plot(x='fpr', y='tpr', label="ROC", xlabel="FPR", ylabel="TPR")
# # print(df)
# plt.show()
# Calculate ROC curve and AUC
fpr_values, tpr_values, _ = roc_curve(y, y_hat)
roc_auc = auc(fpr_values, tpr_values)
# Plot ROC curve
plt.figure(figsize=(8, 6))
plt.plot(fpr_values, tpr_values, color='blue', lw=2, label=f'ROC curve (area = {roc_auc:.3f})')
plt.plot([0, 1], [0, 1], color='grey', lw=1, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate (FPR)')
plt.ylabel('True Positive Rate (TPR)')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc='lower right')
plt.grid(True)
plt.show()
分类模型代码以及结果:


(2)对于回归模型,计算出MAE,MAPE,MSE,RMSE,
回归模型代码以及结果:
import numpy as np
from sklearn.metrics import mean_squared_error # MSE:均方误差
from sklearn.metrics import mean_absolute_error # MAE:平均绝对误差
from sklearn.metrics import mean_absolute_percentage_error # MAPE:平均绝对百分比误差
from sklearn.metrics import r2_score # R2得分
# 数据集
y_test = np.array([1.0, 4.0, 2.0, 3.0, 1.0, 5.0, -3.0, 5.0, 1.0, 3.0, 2.0, 5.0])
y_predict = np.array([1.0, 4.1, 2.2, 2.8, 1.0, 4.8, -2.2, 5.1, 0.9, 3.2, 2.1, 5.3])
mean_squared_error(y_test, y_predict)
mean_absolute_error(y_test, y_predict)
np.sqrt(mean_squared_error(y_test, y_predict)) # RMSE:均方根误差
r2_score(y_test, y_predict)
print("MAE:", mean_absolute_error(y_test, y_predict))
print("MAPE:", mean_absolute_percentage_error(y_test, y_predict))
print("MSE:", mean_squared_error(y_test, y_predict))
print("RMSE:", np.sqrt(mean_squared_error(y_test, y_predict)))
print("R2:", r2_score(y_test, y_predict))

















 1316
1316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











