







 本文详细介绍了循环神经网络(RNN)的结构,强调了RNN在处理时序序列问题上的优势。通过图形和公式解析,展示了RNN如何通过权重共享实现信息传递,并预告了RNN参数更新的关键——反向传播通过时间(BPTT)。
本文详细介绍了循环神经网络(RNN)的结构,强调了RNN在处理时序序列问题上的优势。通过图形和公式解析,展示了RNN如何通过权重共享实现信息传递,并预告了RNN参数更新的关键——反向传播通过时间(BPTT)。
下面简单介绍一下RNN的结构,如果简略地去看,RNN结构很简单,根本没有CNN那么复杂,但是要具体实现,还是需要仔细思考一下,希望本篇博客能把RNN结构说的明白。
循环神经网络(Recurrent Neural Network,RNN)DNN以及CNN在对样本提取特征的时候,样本与样本之间是独立的,而有些情况是无法把每个输入的样本都看作是独立的,比如NLP中的此行标注问题,ASR中每个音素都和前一个音素是相关的,这类问题可以看做一种带有时序序列的问题,无法将样本看做是相互独立的,因此单纯的DNN和CNN解决这类问题就比较棘手。此时RNN就是一种解决这类问题很好的模型。
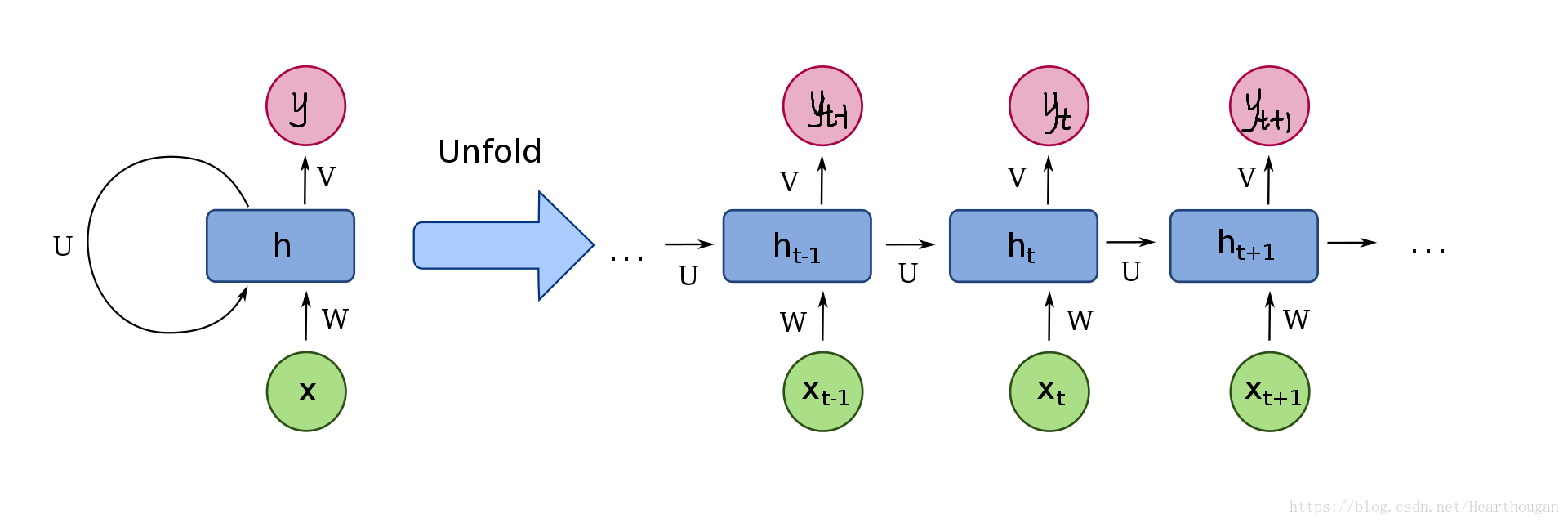
由上图可以看出,RNN的结构是一个重复的过程,且权重是共享的,这也是借鉴了CNN的思想,可以减少参数量,从而减少计算的复杂度。第
时刻隐藏层的输出需要
时刻的隐藏层的输出,RNN以此来实现信息的传递。如果上图计算不清晰,就请看下面的两幅图片。


看到这两幅图已经很清晰地展示了RNN的整体结构,但是在具体实现的时候,或者你需要了解每一个细节,我们知道在图像处理的时候,我
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1929
1929

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









