







函数1:建立语料库
data_initialization(data, gaz_file, train_file, dev_file, test_file)
def data_initialization(data, gaz_file, train_file, dev_file, test_file):
data.build_alphabet(train_file)#建立的train file的词表
data.build_alphabet(dev_file)
data.build_alphabet(test_file)
# TODO gaz_file词典?
data.build_gaz_file(gaz_file)
data.build_gaz_alphabet(train_file)
data.build_gaz_alphabet(dev_file)
data.build_gaz_alphabet(test_file)
data.fix_alphabet()
return data
之后的数据处理部分的核心函数在data文件夹下。
data.build_alphabet(dev_file)——建立语料库。
data.build_gaz_alphabet(dev_file)——建立词典库。
加载pretrain的词典库。
之后,上边的vbocabluary可以得到词典集合、char集合和Word集合。根据集合可以确定对应的index值。
在之后,是将每句话的Word、char和词典使用对应的ID存储。
data.generate_instance_with_gaz(train_file,‘train’)
#返回的是 #train_text返回的是words, biwords, chars, gazs, labels,train_ids返回的是word_Ids, biword_Ids, char_Ids, gaz_Ids, label_Ids
之后,加载预训练的词向量。
data.build_word_pretrain_emb(char_emb)#pretrain_word_embedding——numpy数组,word_emb_dim——int
data.build_biword_pretrain_emb(bichar_emb)
data.build_gaz_pretrain_emb(gaz_file)
在之后,是调用模型完成训练。
train(data, save_model_dir, seg)
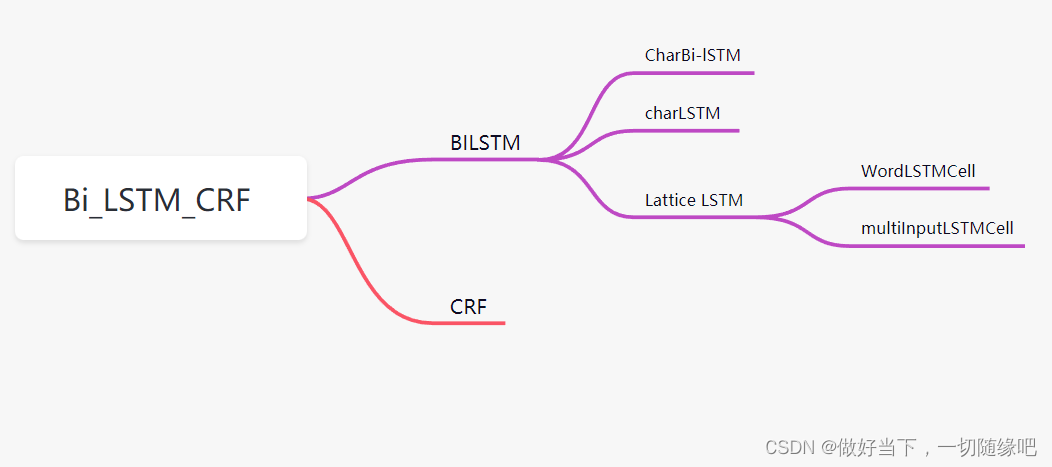
模型部分
主模型:BiLSTM_CRF模型
子模型:
BiLSTM和CRF模型。
在BILSTM 模型中,包含的子模型有:
CharBiLSTM、CharCNN、LatticeLSTM 模型。
self.word_embeddings = nn.Embedding(len(data.word_alphabet), self.embedding_dim)
self.biword_embeddings = nn.Embedding(len(data.biword_alphabet), data.biword_emb_dim)
if data.pretrain_word_embedding is not None:
self.word_embeddings.weight.data.copy_(torch.from_numpy(data.pretrain_word_embedding))
else:
self.word_embeddings.weight.data.copy_(torch.from_numpy(self.random_embedding(len(data.word_alphabet), self.embedding_dim)))
if data.pretrain_biword_embedding is not None:
self.biword_embeddings.weight.data.copy_(torch.from_numpy(data.pretrain_biword_embedding))
else:
self.biword_embeddings.weight.data.copy_(torch.from_numpy(self.random_embedding(len(data.biword_alphabet), data.biword_emb_dim)))
# The LSTM takes word embeddings as inputs, and outputs hidden states
# with dimensionality hidden_dim.
默认的embedding_dim是Word和char的embedding,lstm_input = self.embedding_dim + self.char_hidden_dim
如果使用,bi-gram,
lstm_input += data.biword_ emb_dim
在lattice_lstm中,
主函数是Lattice_LSTM,子函数包括:WordLSTMCell、MultiInputLSTMCell,
self.rnn = MultiInputLSTMCell(input_dim, hidden_dim)
self.word_rnn = WordLSTMCell(word_emb_dim, hidden_dim)
目前,在py3.7版本或者以上额版本是可以运行 ,但是loss好像存在问题。欢迎一起来改。
(py2的环境下,win里,我没有安上torch的0.3.0,在py3上的做的程序运行。)
本机地址:E:\PythonProject\pythonProject_draft\词典使用\LatticeLSTM-master
https://gitcode.net/Hekena/latticelstm-master_py3/-/tree/master















 583
583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











